关于图的算法。
1. 图的存储 稠密图用邻接矩阵存储,稀疏图用邻接表存。
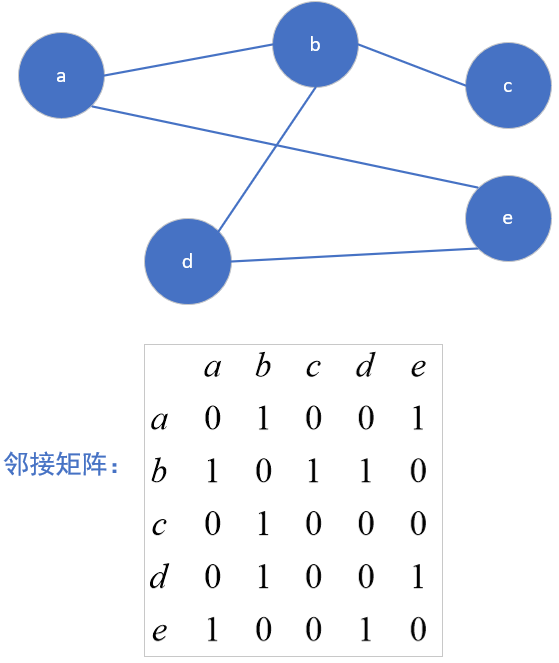
1.1 邻接矩阵 1.1.1 邻接矩阵表示无向图 假如一个图有n个顶点,则开n×n的邻接矩阵,若顶点i到顶点j存在一条边,则g[i][j] = 1,否则为0.
无向图的邻接矩阵一定是对称矩阵。
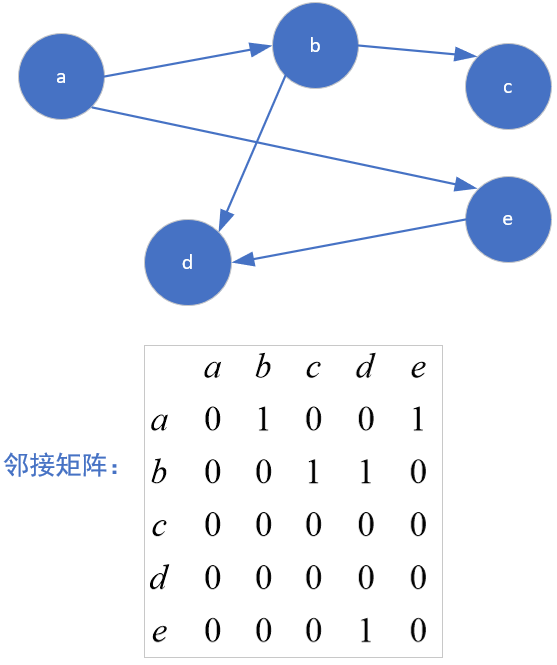
1.1.2 邻接矩阵表示有向图
有向图中某顶点:出度 入度
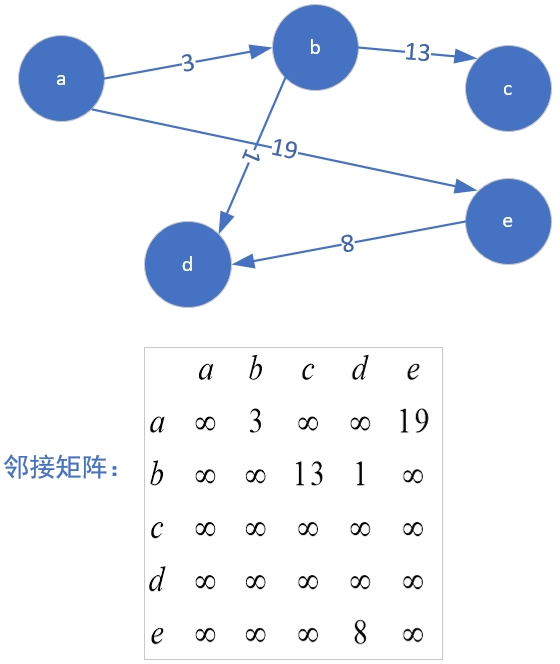
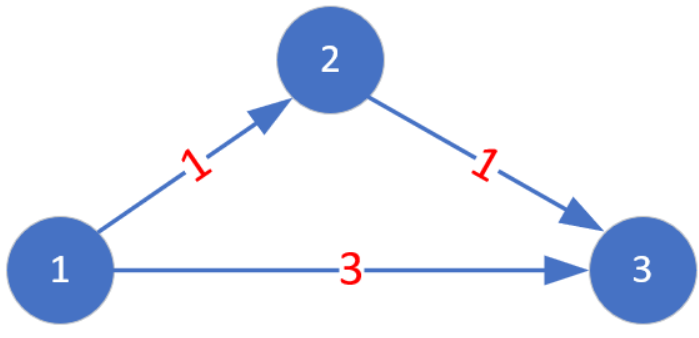
1.1.3 邻接矩阵表示网 网就是边具有非0非1权值的图,若顶点i到顶点j存在一条边,且该边的权值为w,则g[i][j] = w,否则为无穷大.
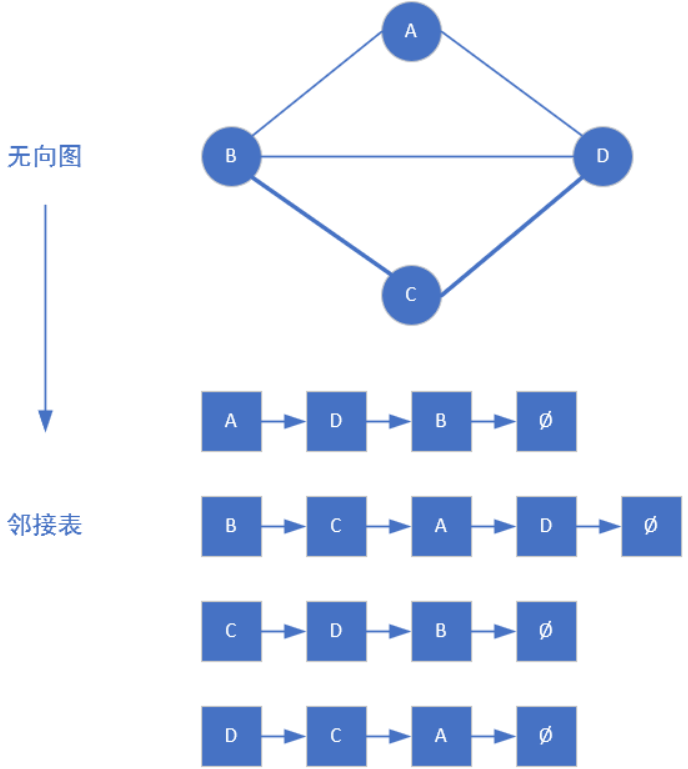
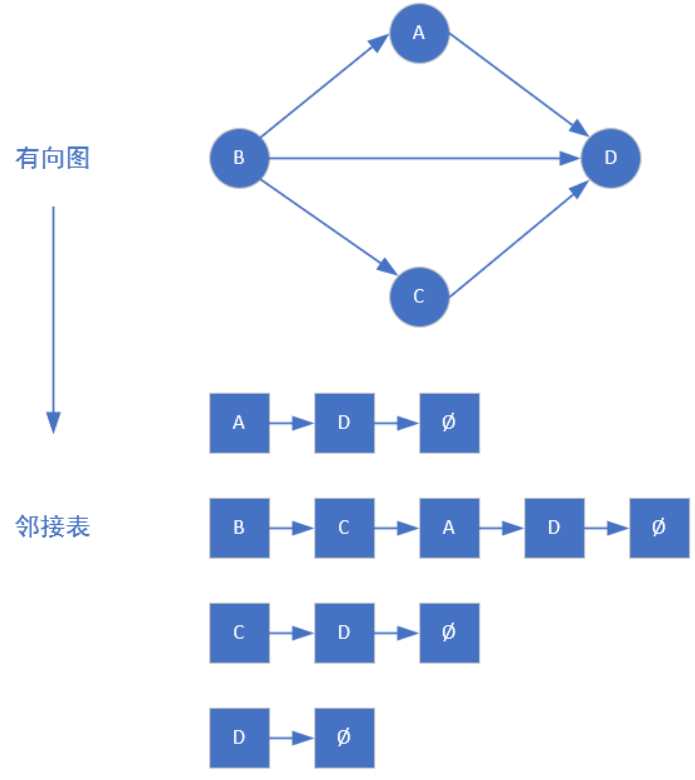
1.2 邻接表 邻接表是一组链表的集合,其中每一个链表的头节点都代表图中某个顶点,该链表上的其他节点代表该顶点的邻居。链表中的每一个节点有两个属性,一个是next,指向该链表头节点的另一个儿子,另一个属性是该节点的编号/值。
1.2.1 邻接表表示无向图
1.2.2 邻接表表示有向图
邻接表的结构与哈希表的拉链法结构一模一样,都是链表类型的数组。
2. 遍历 2.1 深度优先遍历 一直往深处走,直到无路可走时,才会退回寻找其他路径。
用两个经典问题来说明这个算法
2.1.1 全排列 【题目】
输入正整数n,打印1~n的全排列
https://www.acwing.com/problem/content/844/
【解析】
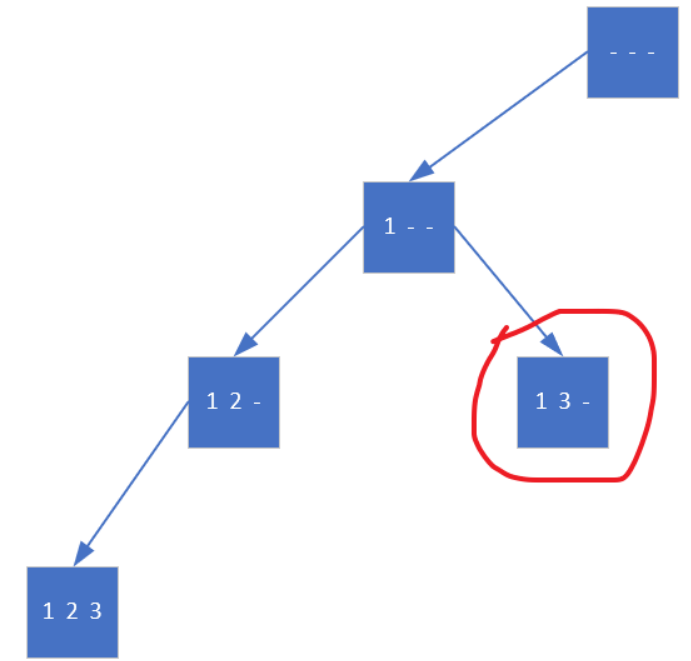
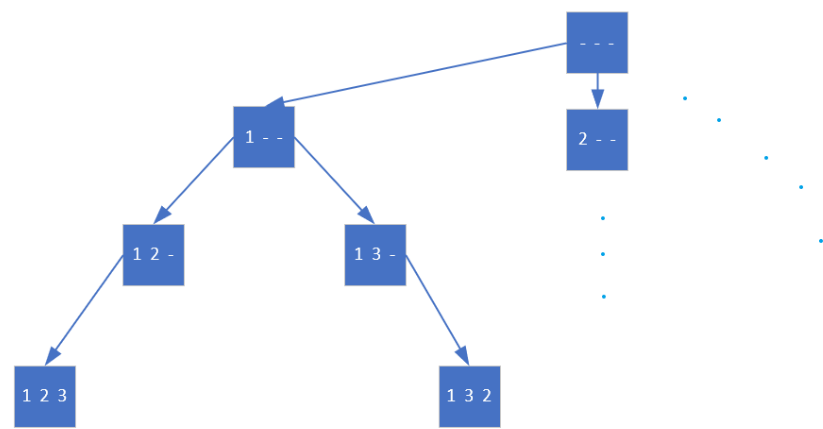
比如n=3,一开始有三个空位可以填
假如第一个位置选择填1
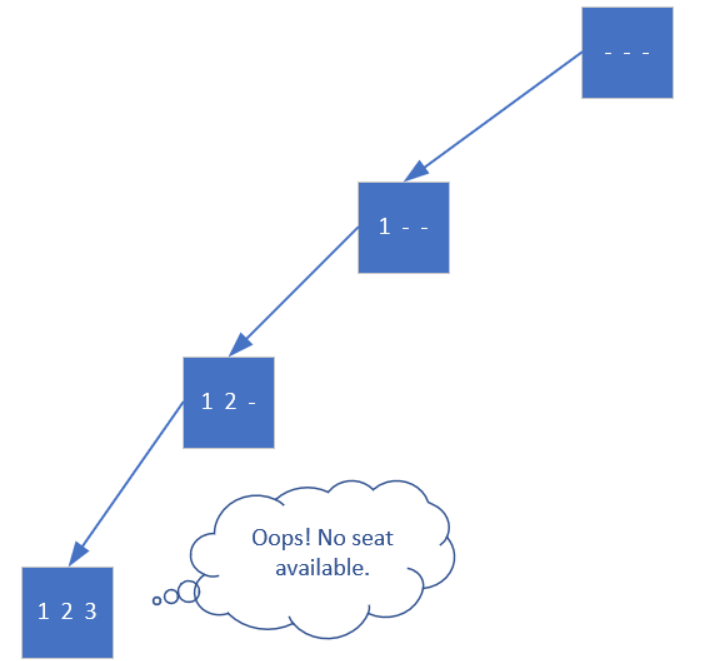
dfs会继续在此基础上决定第二个位置填几,因为是深度优先,优先往深处搜,不撞南墙是不会回头的。所以现在还剩两个位置可填。
这时它意识到自己已经无法前进了,只好回退一步看看有没有别的路。退回到【1 2 _】处后,它发现也没有别的选择了,刚才3也选过了,只能再回退一步到【1 _ _】,检查发现,第二个位置不光可以填2,还可以填3
继续重复上述步骤,直到退回根节点
【ac代码】
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution { final int N = 10 ; int [] path = new int [N]; boolean [] visited = new boolean [N]; public void dfs (int level, int n) { if (level == n){ for (int i = 0 ; i < n; i++) { System.out.print(path[i]); } System.out.println(); return ; } for (int i = 1 ; i <= n; i++) { if (!visited[i]){ path[level] = i; visited[i] = true ; dfs(level+1 , n); path[level] = 0 ; visited[i] = false ; } } } public static void main (String[] args) { Scanner in = new Scanner (System.in); int n = in.nextInt(); Solution s = new Solution (); s.dfs(0 ,n); } }
2.1.2 n皇后 【题目】
https://www.acwing.com/problem/content/845/
一个n*n的棋盘上,任意两个棋子不能出现在同一行 或同一列 或同一斜线 。输出所有可能的方案。
【ac代码】
第一种方法是按照全排列的思路来解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <iostream> using namespace std;const int N = 20 ; bool col[N], dg[N], udg[N]; char chessBoard[N][N]; int n; void dfs (int row) if (row == n) { for (int i = 0 ;i<n;i++) { for (int j = 0 ;j<n;j++) printf ("%c" ,chessBoard[i][j]); printf ("\n" ); } printf ("\n" ); return ; } for (int i = 0 ;i<n;i++) { if (!col[i]&&!dg[i+row]&&!udg[i-row+n]) { chessBoard[row][i] = 'Q' ; col[i] = dg[i+row] = udg[i-row+n] = true ; dfs (row+1 ); col[i] = dg[i+row] = udg[i-row+n] = false ; chessBoard[row][i] = '.' ; } } } int main () scanf ("%d" ,&n); for (int i =0 ;i<n;i++) { for (int j = 0 ;j<n;j++) chessBoard[i][j] = '.' ; } dfs (0 ); return 0 ; }
用i+row和i-row+n为啥能表示对角线?
i在我们的代码中表示列,row代表行,那么对角线就可以用y=x+b来表示。
第二种解法是遍历整个棋盘,在每个位置判断放还是不放。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <iostream> using namespace std;const int N = 20 ; bool row[N], col[N], dg[N], udg[N]; char chessBoard[N][N]; int n; void dfs (int x, int y, int chessCount) if (y>=n) y = 0 , x++; if (x==n) { if (chessCount == n) { for (int i = 0 ;i<n;i++) { for (int j = 0 ;j<n;j++) printf ("%c" ,chessBoard[i][j]); printf ("\n" ); } printf ("\n" ); } return ; } dfs (x,y+1 ,chessCount); if (!row[x]&&!col[y]&&!dg[y+x]&&!udg[y-x+n]) { chessBoard[x][y] = 'Q' ; row[x] = col[y] = dg[y+x] = udg[y-x+n] = true ; dfs (x,y+1 ,chessCount+1 ); row[x] = col[y] = dg[y+x] = udg[y-x+n] = false ; chessBoard[x][y] = '.' ; } } int main () scanf ("%d" ,&n); for (int i =0 ;i<n;i++) { for (int j = 0 ;j<n;j++) chessBoard[i][j] = '.' ; } dfs (0 , 0 , 0 ); return 0 ; }
对比来看,显然按照全排列思路的第一种方法效率更高,好好体会下二者的区别。
2.2 宽度优先遍历 从起点开始逐层向外拓展。
宽度优先队列一般依靠队列完成(比如树的层序遍历)
2.2.1 走迷宫 【题目】
https://www.acwing.com/problem/content/846/
0表示路,1表示墙,在01组成的迷宫中,找出一条从左上角到右下角的最短路。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <iostream> #include <queue> #include <cstring> using namespace std;typedef pair<int , int > PII;const int N = 200 ;bool maze[N][N]; int distan[N][N]; int n, m; int dx[4 ] = {-1 ,0 ,1 ,0 };int dy[4 ] = {0 ,-1 ,0 ,1 };int bfs () memset (distan, -1 , sizeof (distan)); distan[0 ][0 ] = 0 ; queue<PII> q; q.push ({0 , 0 }); while (!q.empty ()) { PII head = q.front (); q.pop (); for (int i = 0 ;i<4 ;i++) { int x = head.first+dx[i]; int y = head.second+dy[i]; if (x>=0 &&x<n&&y>=0 &&y<m&&distan[x][y]==-1 &&maze[x][y]==0 ) { distan[x][y] = distan[head.first][head.second]+1 ; q.push ({x, y}); } } } return distan[n-1 ][m-1 ]; } int main () scanf ("%d %d" ,&n,&m); for (int i= 0 ;i<n;i++) { for (int j = 0 ;j<m;j++) scanf ("%d" ,&maze[i][j]); } printf ("%d" , bfs ()); return 0 ; }
手动模拟一下该算法
可以看出宽搜是齐头并进的地毯式搜索
当所有边的权值为1时,如本题,可以用宽搜来求最短路,其他情况有专门的最短路算法
【本题中还有一个遍历矩阵某位置的上下左右的技巧点】
对一个点(x, y):
1 2 int dx[4 ] = {-1 ,0 ,1 ,0 }; int dy[4 ] = {0 ,-1 ,0 ,1 };
然后用一个循环即可遍历(x, y)的上下左右
1 2 3 4 5 6 for (int i = 0 ;i<4 ;i++){ int tempX = x+dx[i]; int tempY = y+dy[i]; action on (tempX, tempY) ; }
2.3 树和图的遍历 树是有向无环图,但有向无环图不一定是树,因为可能有两个顶点的出边指向同一个顶点。
本节我们采用邻接表存图。
2.3.1 深度优先遍历 1 2 3 4 5 6 7 8 9 10 int dfs (int u) st[u] = true ; for (int i = h[u]; i != -1 ; i = ne[i]) { int j = e[i]; if (!st[j]) dfs (j); } }
比如通过深度优先遍历来求多叉树的总结点数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int dfs (int u) st[u] = true ; int sum = 1 ; for (int i = h[u]; i!=-1 ;i= ne[i]) { int j = e[i]; if (st[j]) continue ; int s = dfs (j); sum+=s; } return sum; }
再通过一个例题来理解。
【题目】
树的重心
https://www.acwing.com/problem/content/848/
【解析】
先引入一些必要的概念
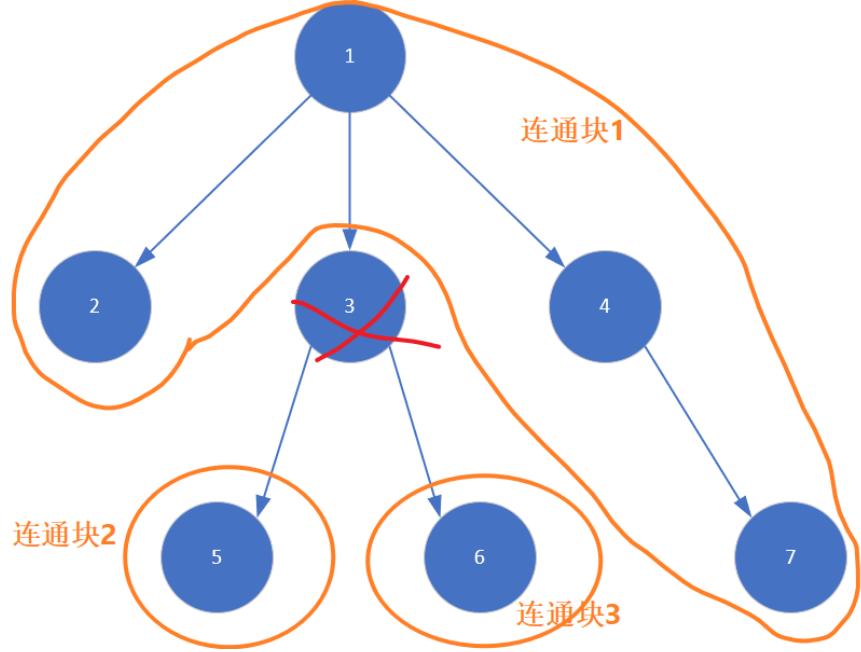
连通块
假如把3号节点删掉,整棵树就被分成了三个连通块。
重心
找出树中的某个节点,如果把这个节点删掉后,划分出的所有连通块的最大值最小(即划分的最平均),则这个点就被称为重心。当树的总结点数为偶数时,可能有多个重心 。
要解决本题,我们需要把所有节点逐个假设为重心,测试每一种假设中最大连通块的大小,完成后最小的那个就是我们要的答案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <iostream> #include <cstring> using namespace std;const int N = 1e5 , M = N*2 ;int e[M], ne[M], idx, h[M]; bool st[M]; int n; int ans = 0x3f3f3f3f ; void add (int a, int b) e[idx] = b; ne[idx] = h[a]; h[a] = idx++; } int dfs (int u) st[u] = true ; int sum = 0 , res = 0 ; for (int i = h[u]; i!=-1 ;i = ne[i]) { int j = e[i]; if (st[j]) continue ; int s = dfs (j); res = max (s, res); sum+=s; } res = max (res, n-sum-1 ); ans = min (ans, res); return sum+1 ; } int main () memset (h, -1 , sizeof (h)); scanf ("%d" ,&n); int a=0 ,b=0 ; for (int i =0 ;i<n-1 ;i++) { scanf ("%d%d" ,&a,&b); add (a, b); add (b, a); } dfs (1 ); printf ("%d" ,ans); return 0 ; }
2.3.2 宽度优先遍历 【题目】
https://www.acwing.com/problem/content/849/
给定一个n个点m条边的有向图,图中可能存在重边和自环。所有边的长度都是1,点的编号为1~n。请你求出1号点到n号点的最短距离 ,如果从1号点无法走到n号点,输出-1。
【解析】
先引入必要的改概念:
重边
自环
题目条件给出所有边的长度都为1,因此我们可以用宽搜来求最短距离
只需要对最基本的深搜框架做一些改动即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <iostream> #include <cstring> #include <queue> using namespace std;const int N = 1e5 +10 ;int ne[N], h[N], e[N], idx; int d[N]; int n, m; void add (int a, int b) e[idx] = b; ne[idx] = h[a]; h[a] = idx++; } int bfs () queue<int > q; q.push (1 ); d[1 ] = 0 ; while (!q.empty ()) { int fore = q.front (); q.pop (); for (int i = h[fore]; i!=-1 ; i = ne[i]) { int succ = e[i]; if (d[succ]==-1 ) { d[succ] = d[fore]+1 ; q.push (succ); } } } return d[n]; } int main () memset (h, -1 , sizeof (h)); memset (d, -1 , sizeof (d)); scanf ("%d%d" ,&n,&m); int a,b; for (int i = 0 ;i<m;i++) { scanf ("%d%d" ,&a,&b); add (a,b); } printf ("%d\n" ,bfs ()); return 0 ; }
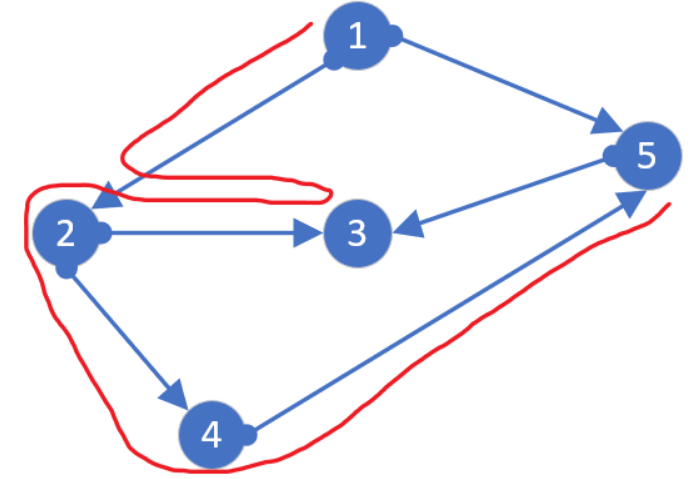
2.3.3 拓扑排序 拓扑序列 : 给定一个有向图,若以该图为准找出一种节点序列,这个序列从左往右的顺序在图中可以【顺着箭头】遍历所有节点,那么这个序列就称为该有向图的拓扑序列(不一定唯一)。
举一个栗子:
按照图中数字123456789的顺序遍历,假如每访问一个点就把这个点删除掉,就会发现每次将要访问的那个节点必然无前驱 (入度为0),此图除了123456789我们还能找出其他的拓扑序列:132645789、136247589….
宽搜的一个经典应用就是拓扑排序,一个 有向无环图 (拓扑图) 必然存在拓扑排序(即它至少存在一个入度为0的点),无向图或者一个有环的图 必然不存在拓扑排序。
思路
可以想像,所有入度为0的点都可以作为拓扑排序的起点,我们要做的第一件事就是把所有入度为0的点全部入队。
弹出队列的队头元素(先把它保存到拓扑序列中),遍历其所有儿子,每访问一个儿子,就将该儿子的入度-1(切断它与它父亲的联系),然后判断:该儿子的入度是否为0?如果为0,说明下次能把它加入到拓扑序列中,现在把它push到队列中即可。这样保证了无论何时队列中任一节点入度总是为0,重复2的操作直到访问完毕,随之也得到了一个拓扑序列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <iostream> #include <queue> #include <cstring> using namespace std;const int N = 1e5 +10 ;int n, m;int h[N], e[N], ne[N], idx; int d[N]; queue<int > q; vector<int > topo; void add (int a, int b) e[idx] = b; ne[idx] = h[a]; h[a] = idx++; d[b]++; } bool TopSort () for (int i = 1 ;i<=n;i++) if (d[i]==0 ) q.push (i); while (!q.empty ()) { int fore = q.front (); topo.push_back (fore); q.pop (); for (int i = h[fore]; i!=-1 ; i=ne[i]) { int succ = e[i]; d[succ]--; if (d[succ]==0 ) q.push (succ); } } return topo.size ()==n; } int main () memset (h, -1 , sizeof (h)); scanf ("%d%d" ,&n,&m); int a,b; for (int i = 0 ;i<m;i++) { scanf ("%d%d" ,&a,&b); add (a, b); } if (!TopSort ()) { printf ("-1\n" ); return 0 ; } for (int i = 0 ;i<topo.size ();i++) printf ("%d " , topo[i]); return 0 ; }
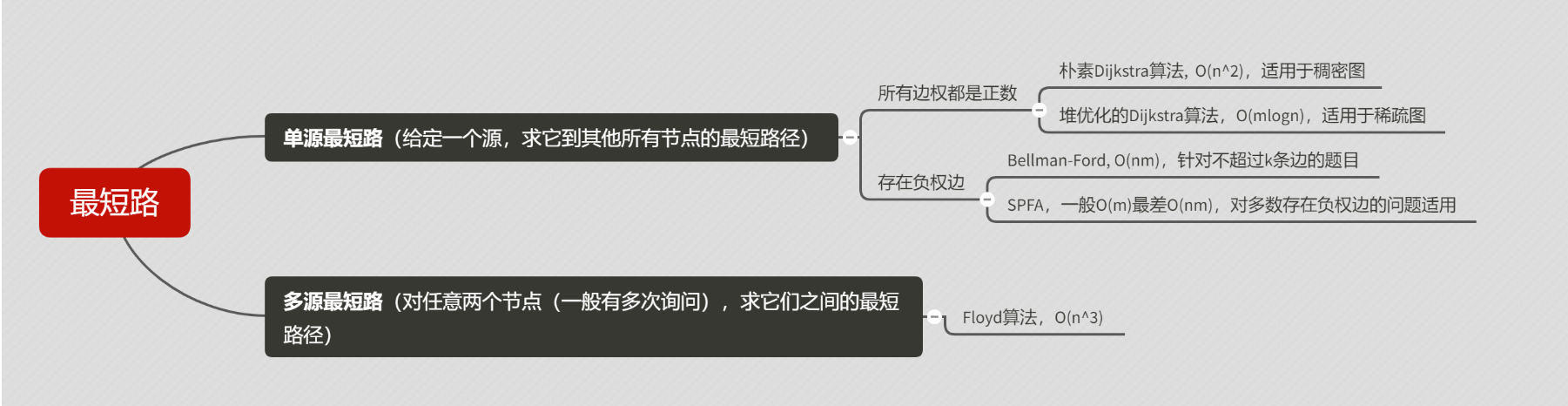
3. 最短路问题 在不同的情境下有不同的最短路算法,假定n为节点数 ,m为边数 :
如何区分稠密图和稀疏图?
最短路问题最大的难点在于如何把问题抽象成最短路问题,即如何定义节点和边
3.1 普通Dijkstra算法 专用于稠密图 ,用邻接矩阵存储。
思路:
每次都在所有还未确定最短路径的顶点中,选出一个与起点距离最近的顶点t,那么可以确定,目前记录的起点到顶点t的距离就是它们的最短距离。
确定了顶点t的最短路径后,以它与起点之间的距离为基础,更新它所有后继到起点的距离。
重复上述动作,直到确定所有顶点的最短路径为止。
题目:给定顶点数n和边数m,求顶点1到顶点n的最短距离。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include <cstring> using namespace std;const int N = 510 ;int n, m; int g[N][N]; int st[N]; int dist[N]; int dijkstra () memset (dist, 0x3f , sizeof (dist)); dist[1 ] = 0 ; for (int i = 0 ;i<n;i++) { int t = -1 ; for (int j = 1 ;j<=n;j++) { if (!st[j] && (t==-1 || dist[t] > dist[j])) t = j; } st[t] = true ; for (int j = 1 ;j<=n;j++) { dist[j] = min (dist[j], dist[t] + g[t][j]); } } if (dist[n]==0x3f3f3f3f ) return -1 ; return dist[n]; } int main () scanf ("%d%d" ,&n,&m); memset (g, 0x3f , sizeof (g)); int x,y,z; for (int i = 0 ;i<m;i++) { scanf ("%d%d%d" ,&x,&y,&z); g[x][y] = min (g[x][y], z); } printf ("%d\n" ,dijkstra ()); return 0 ; }
3.2 堆优化版Dijkstra算法 专用于稀疏图 ,用邻接表存储。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 #include <iostream> #include <cstring> #include <queue> using namespace std;const int N = 1000010 ;typedef pair<int , int > PII; int e[N], ne[N], h[N], w[N], idx; int dist[N]; int st[N]; int n, m; void add (int a, int b, int c) e[idx] = b; w[idx] = c; ne[idx] = h[a]; h[a] = idx++; } int Dijkstra () memset (dist, 0x3f , sizeof (dist)); dist[1 ] = 0 ; priority_queue<PII, vector<PII>, greater<PII>> heap; heap.push ({0 , 1 }); while (!heap.empty ()) { PII fore = heap.top (); heap.pop (); int distance = fore.first; int ver = fore.second; if (st[ver]) continue ; for (int i = h[ver]; i!=-1 ; i = ne[i]) { int succ = e[i]; if (distance + w[i] < dist[succ]) { dist[succ] = distance + w[i]; heap.push ({dist[succ], succ}); } } st[ver] = true ; } if (dist[n]==0x3f3f3f3f ) return -1 ; return dist[n]; } int main () scanf ("%d%d" ,&n,&m); memset (h, -1 , sizeof (h)); int a, b, c; for (int i = 0 ;i<m;i++) { scanf ("%d%d%d" ,&a,&b,&c); add (a, b, c); } printf ("%d\n" ,Dijkstra ()); return 0 ; }
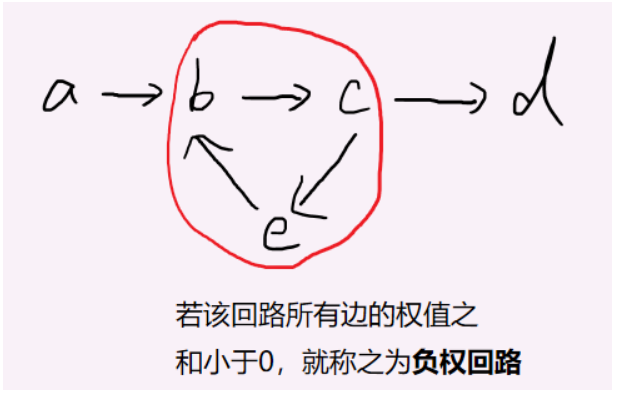
3.3 Bellman-Ford算法 针对于存在负权边的(且限制了最多走k条边的)最短路问题,要注意的是图中如果存在负权回路 ,那么最短路可能 不存在。
负权回路是指:
Bellman-Ford算法十分的暴力,它的策略如下:
将起点外所有点的距离初始化为无穷大,起点距离为0。
起点到终点最多允许经过k条路(一般有此限制才使用bellman-ford算法),因此总共要循环k次找路(每次确定一条边)。每次找路都会遍历所有边 ,如果该边的前驱 与起点的距离不是无穷大 (即其前驱被更新过):可能 利用其前驱更新一条更短的一条路。
该算法设计时有一些小细节,举例如下:
因为我们的算法中,每次确定一条边都要遍历所有边 ,这样就会产生一些问题。它的前驱是否已经被更新过 (即其前驱到起点的距离是否为无穷大),本例此时第二条边的后继顶点3就会依据其前驱到起点的距离dist[2]的值是否为无穷大来决定是否更新,发现dist[2]不为无穷大,因此后继顶点3就会根据前驱顶点2来更新到起点的距离(dist[3]=2),最后返回最短路径2,这就不对了。我们的算法本意是要一条边一条边的确定,上述情况却一次确定了两条边,但它还以为只确定了一条。上一轮找边结束时所有顶点的状态 即可,反映到代码上就是每轮找边开始时把dist数组复制到backup数组中,之后使用的前驱 都从backup数组中取。
例题: 存在负环的图中,经过不超过k条边从起点到顶点n的最短路径长度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include <cstring> using namespace std;const int N = 100010 ;const int M = 10010 ;int n, m, k; struct Edge { int a; int b; int w; }edge[M]; int dist[M], backup[M]; int BellmanFord () memset (dist, 0x3f , sizeof (dist)); dist[1 ] = 0 ; for (int i = 0 ;i<k;i++) { memcpy (backup, dist, sizeof (dist)); for (int j = 1 ;j<=m;j++) { Edge e = edge[j]; dist[e.b] = min (dist[e.b], backup[e.a] + e.w); } } if (dist[n] > 0x3f3f3f3f /2 ) return -1 ; return dist[n]; } int main () scanf ("%d%d%d" ,&n, &m, &k); for (int i = 1 ;i<=m;i++) { scanf ("%d%d%d" , &edge[i].a, &edge[i].b, &edge[i].w); } int re = BellmanFord (); if (re==-1 ) printf ("impossible" ); else printf ("%d\n" ,dist[n]); return 0 ; }
3.4 SPFA 本质上是对bellman-ford算法的优化 。纯正权图中还是老老实实的用Dijkstra 。
回忆bellman-ford算法,它之所以暴力的原因在于,每找一条边都要遍历所有的边,而大多数遍历其实是在做无用功(比如一开始,只有起点距离起点的距离已知,那么这一轮只能更新起点的所有后继,其他的遍历都是浪费)。其后继需要被更新的顶点 会被放在队列中,一开始只有起点在队列中,在遍历所有队列中 顶点的后继时,只有当某一个顶点的距离被更新后 ,才会将它入队,才会在之后更新它的所有后继,因为一个顶点的路径更新了会影响到它所有的后继;而如果遍历到的某顶点无法被更新(要么新路径还没有旧路径短,要么该顶点的前驱与起点的距离还处于未知状态),就会跳过它,暂时不对它的后继做任何测试。这样一来,每一次遍历都是有意义的了,相比bellman-ford节省了很多时间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 #include <iostream> #include <cstring> #include <queue> using namespace std;const int N = 100010 ;int n, m; int h[N], ne[N], e[N], dist[N], w[N], idx; bool st[N]; void add (int a, int b, int c) e[idx] = b; w[idx] = c; ne[idx] = h[a]; h[a] = idx++; } int spfa () dist[1 ] = 0 ; queue<int > q; q.push (1 ); st[1 ] = true ; while (!q.empty ()) { int fore = q.front (); q.pop (); st[fore] = false ; for (int i = h[fore]; i!=-1 ; i = ne[i]) { int succ = e[i]; if (dist[succ] > dist[fore]+w[i]) { dist[succ] = dist[fore]+w[i]; if (!st[succ]) { st[succ] = true ; q.push (succ); } } } } if (dist[n]==0x3f3f3f3f ) return -1 ; return dist[n]; } int main () memset (h, -1 , sizeof (h)); memset (dist, 0x3f , sizeof (dist)); scanf ("%d%d" ,&n,&m); int a,b,c; for (int i = 0 ;i<m;i++) { scanf ("%d%d%d" ,&a, &b, &c); add (a, b, c); } int re = spfa (); if (re==-1 ) printf ("impossible\n" ); else printf ("%d\n" ,re); return 0 ; }
3.4.1 SPFA判断是否存在负环 其方法就是在SPFA中的每一句:
另外需要注意的是,我们不能总是以编号为1的顶点出发寻找负环,因为有可能达到不了负环,所以我们要从每一个顶点出发,也就是最一开始要把所有的顶点全部push到队列中。那么在这样的条件下,我们也不需要把dist数组初始化为无穷大了,全部为0即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #include <iostream> #include <queue> #include <cstring> using namespace std;const int N = 100010 ;int e[N], ne[N], h[N], w[N], cnt[N], st[N], dist[N], idx;int n,m; void add (int a, int b, int c) e[idx] = b; w[idx] = c; ne[idx] = h[a]; h[a] = idx++; } bool spfaJ () queue<int > q; for (int i = 1 ;i<=n;i++) { q.push (i); st[i] = true ; } while (!q.empty ()) { int fore = q.front (); q.pop (); st[fore] = false ; for (int i = h[fore]; i!=-1 ;i = ne[i]) { int succ = e[i]; if (dist[succ] > dist[fore]+w[i]) { dist[succ] = dist[fore]+w[i]; cnt[succ] = cnt[fore]+1 ; if (cnt[succ]>=n) return true ; if (!st[succ]) { q.push (succ); st[succ] = true ; } } } } return false ; } int main () memset (h, -1 , sizeof (h)); scanf ("%d%d" ,&n,&m); int a,b,c; for (int i = 0 ;i<m;i++) { scanf ("%d%d%d" ,&a,&b,&c); add (a,b,c); } int re = spfaJ (); if (re) printf ("Yes\n" ); else printf ("No\n" ); return 0 ; }
3.5 Floyd算法 使用该算法的前提是图中没有负权回路 ,且由于该算法的复杂度为O(n^3),因此图的顶点数必须限制在200以内 ,所以在使用该算法时我们可以总是用邻接矩阵来存图 。
该算法的思路:
题目:给定一个无负权环的图,顶点数不超过200,Q次询问任意两点之间的最短路长度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <iostream> #include <cstring> using namespace std;const int N = 210 ; const int INF= 0x3f3f3f3f ;int n,m,Q; int g[N][N];void floyd () for (int k = 1 ; k<=n; k++) { for (int i = 1 ;i<=n;i++) { for (int j = 1 ; j<=n;j++) { g[i][j] = min (g[i][j], g[i][k]+g[k][j]); } } } } int main () scanf ("%d%d%d" ,&n,&m,&Q); for (int i = 1 ;i<=n;i++) { for (int j = 1 ;j<=n;j++) { if (i==j) g[i][j] = 0 ; else g[i][j] = INF; } } int x, y, z; for (int i = 0 ;i<m;i++) { scanf ("%d%d%d" ,&x, &y, &z); g[x][y] = min (g[x][y], z); } floyd (); for (int i = 0 ;i<Q;i++) { scanf ("%d%d" , &x, &y); int re = g[x][y]; if (re>INF/2 ) printf ("impossible\n" ); else printf ("%d\n" , re); } return 0 ; }
4. 最小生成树 最小生成树的任务:在不产生回路的情况下,以最短的路径连通一张图的所有顶点。带权无向连通图 生成的树,它无环地包含了这张图中所有的顶点,且它所有的边都是图中的边。在所有满足这样条件的树当中,边权总和最小 的就是最小生成树 。
4.1 Prim算法 prim算法思路:
从起点开始,更新它所有的后继的距离,再在已经被更新过距离的所有顶点(目前为起点的所有后继)中找到一个与起点(初始时的连通块)距离最近的顶点作为t,将其加入连通块;然后更新t的所有后继,再在已经被更新过距离的所有顶点中找到一个距离连通块最近的点作为t,将其加入连通块,然后更新t的所有后继…..
prim算法与Dijkstra的区别也在连通块,dist数组在prime算法中并不表示某个顶点到起点的最短距离,而是表示某个顶点到当前连通块的最小距离。
不太明白的话照着代码模拟一遍就懂了。
【题目】
https://www.acwing.com/problem/content/860/
在一个存在重边和自环的无向图(存在负权边)中找出最小生成树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include <iostream> #include <cstring> using namespace std;const int N = 510 ;const int INF = 0x3f3f3f3f ;int g[N][N];int st[N]; int dist[N]; int n, m; int prim () memset (dist, 0x3f , sizeof (dist)); int sum = 0 ; for (int i = 0 ; i<n;i++) { int t = -1 ; for (int j = 1 ; j<=n;j++) { if (!st[j] && (t==-1 || dist[t] > dist[j])) t = j; } if (i && dist[t]==INF) return -1 ; if (i) sum+=dist[t]; st[t] = true ; for (int j = 1 ;j<=n;j++) { dist[j] = min (dist[j], g[t][j]); } } return sum; } int main () scanf ("%d%d" ,&n,&m); for (int i = 1 ;i<=n;i++) { for (int j = 1 ; j<=n;j++) { if (i==j) g[i][j] = 0 ; else g[i][j] = INF; } } int x,y,z; for (int i = 0 ;i<m;i++) { scanf ("%d%d%d" ,&x,&y,&z); g[y][x] = g[x][y] = min (g[x][y], z); } int re = prim (); if (re==-1 ) printf ("impossible\n" ); else printf ("%d\n" ,re); return 0 ; }
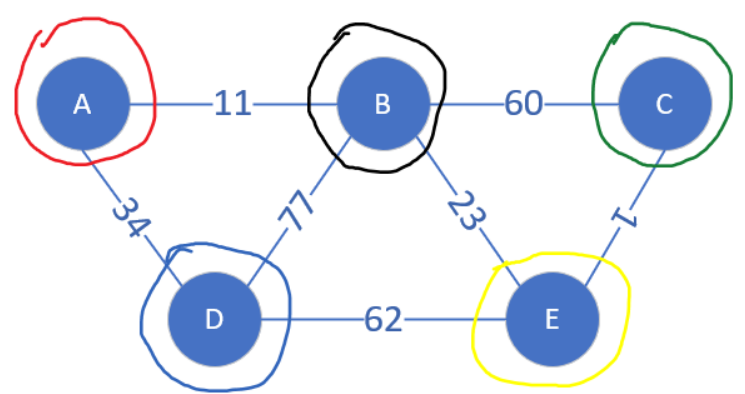
4.2 Kruskal算法 Kruskal算法策略如下:
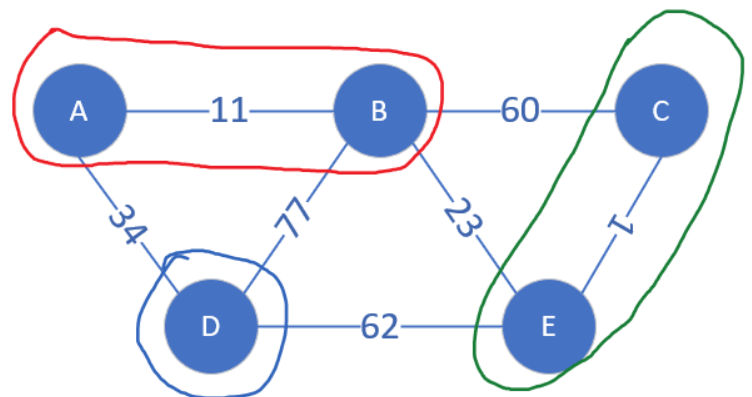
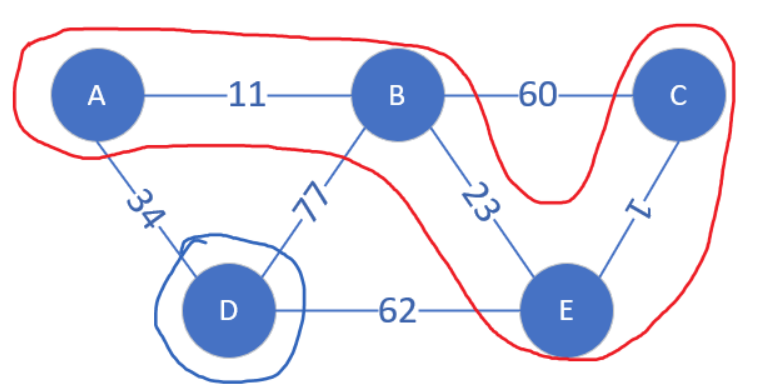
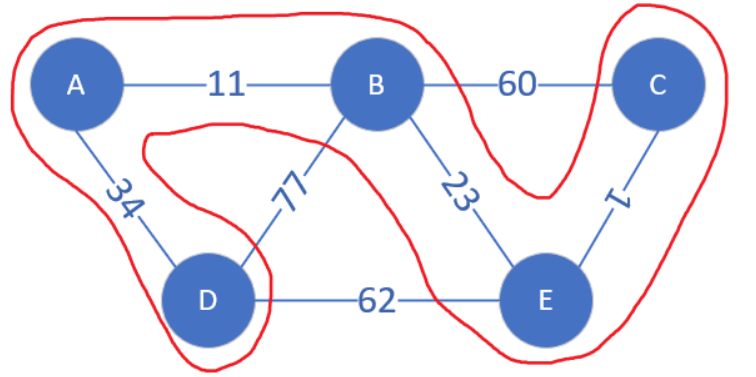
下面来模拟,不同颜色的圈代表不同连通块
排序后遍历所有的边,先走到CE边,它的两个顶点分属不同的连通块,将它们合并。
接下来找到AB边,其两个顶点分属不同的连通块,合并。
接下来是BE边,B和E属于不同连通块,合并。
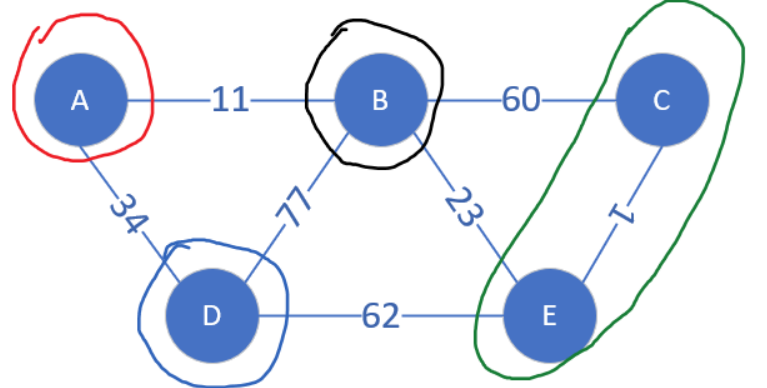
假如现在连通块之外最小的边是BC,顶点B和C属于同一个连通块,这条边就会被跳过。否则如果合并就会产生回路了。
现在连通块中边的数量等于顶点总数-1,说明最小生成树已经被找到了。把点逐渐合并为连通块的工作,我们可以借助并查集 来完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 #include <iostream> #include <algorithm> using namespace std;const int N = 1e5 +10 ;int p[N]; int n,m; struct Edge { int a; int b; int w; }edge[N*2 ]; int cmp (Edge x1, Edge x2) return x1.w<x2.w; } int find (int x) if (p[x]!=x) p[x] = find (p[x]); return p[x]; } int kruskal () int sum = 0 ; int cnt = 0 ; sort (edge, edge+m, cmp); for (int i = 1 ;i<=n;i++) p[i] = i; for (int i = 0 ;i<m;i++) { int a = edge[i].a; int b = edge[i].b; int w = edge[i].w; int root1 = find (a); int root2 = find (b); if (root1!=root2) { p[root1] = root2; sum+=w; cnt++; } if (cnt==n-1 ) return sum; } return -1 ; } int main () scanf ("%d%d" ,&n,&m); for (int i = 0 ;i<m;i++) { scanf ("%d%d%d" ,&edge[i].a,&edge[i].b,&edge[i].w); } int re = kruskal (); if (re==-1 ) printf ("impossible\n" ); else printf ("%d\n" ,re); return 0 ; }
5. 二分图 二分图定义:可以把图中所有顶点分割为两个互不相交的子集,每一条边对应的两个顶点都分属于不同的子集。
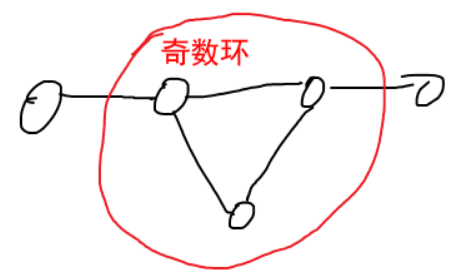
再介绍一个概念奇数环 :边数为奇数的环
二分图还可以这样定义:所有不含有奇数环的图都是二分图
使用染色法 可以判断一个图是否为二分图。
5.1 染色法判断二分图 染色法判断一个图是否为二分图,时间复杂度O(V+E)。
思路:遍历所有顶点(因为图可能不连通),对每一个顶点,将它所属的连通块全部染色。
5.1.1 DFS实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #include <iostream> #include <algorithm> #include <cstring> using namespace std;const int N = 1e5 + 10 , M = 2e5 + 10 ;int e[M], ne[M], h[N], idx;int n, m; int colored[N]; void add (int a, int b) e[idx] = b, ne[idx] = h[a], h[a] = idx ++; } bool DfsColoring (int v, int color) colored[v] = color; for (int i = h[v]; i!=-1 ;i = ne[i]) { int succ = e[i]; if (!colored[succ]) { if (!dfs (succ, ~color)) return false ; } else if (colored[succ]==color) return false ; } return true ; } int main () scanf ("%d%d" , &n, &m); memset (h, -1 , sizeof h); while (m --){ int a, b; scanf ("%d%d" , &a, &b); add (a, b), add (b, a); } int flag = true ; for (int i = 1 ; i <= n; i ++) { if (!colored[i]){ if (!DfsColoring (i, 1 )){ flag = false ; break ; } } } if (flag) puts ("Yes" ); else puts ("No" ); return 0 ; }
5.1.2 BFS实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 #include <iostream> #include <algorithm> #include <queue> #include <cstring> using namespace std;const int N = 1e5 + 10 , M = 2e5 + 10 ;int e[M], ne[M], h[N], idx;int n, m; int colored[N]; void add (int a, int b) e[idx] = b, ne[idx] = h[a], h[a] = idx ++; } bool BfsColoring (int v, int color) queue<int > q; q.push (v); colored[v] = color; while (!q.empty ()) { int fore = q.front (); q.pop (); for (int i = h[fore]; i!=-1 ;i=ne[i]) { int succ = e[i]; if (!colored[succ]) { colored[succ] = ~colored[fore]; q.push (succ); } else if (colored[succ]==colored[fore]) return false ; else continue ; } } return true ; } int main () scanf ("%d%d" , &n, &m); memset (h, -1 , sizeof h); while (m --){ int a, b; scanf ("%d%d" , &a, &b); add (a, b), add (b, a); } int flag = true ; for (int i = 1 ; i <= n; i ++) { if (!colored[i]){ if (!BfsColoring (i, 1 )){ flag = false ; break ; } } } if (flag) puts ("Yes" ); else puts ("No" ); return 0 ; }
5.2 匈牙利算法 理论时间复杂度O(VE),实际一般远低于VE。唯一的一条边 相连
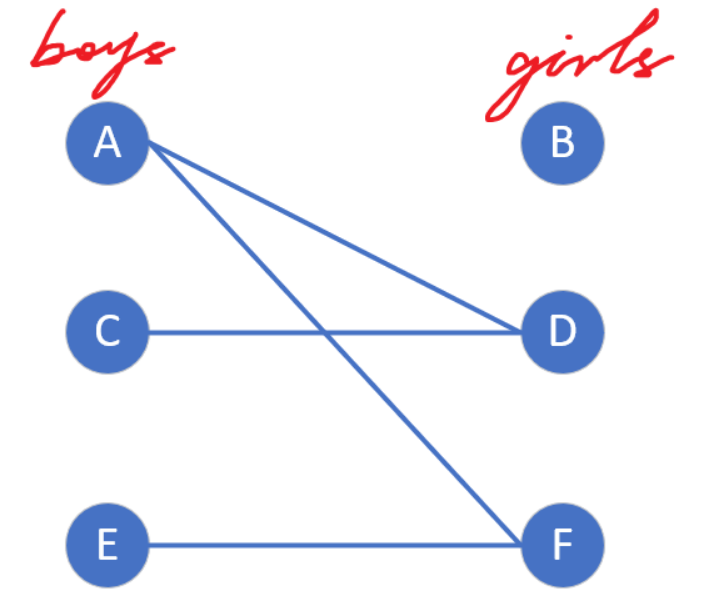
例如这样的一张二分图
我们把它视为适婚年龄男女的恋爱关系图,左侧男生,右侧女生,连线表示互相有好感,现在从媒婆的角度来介绍匈牙利算法实现过程(让最多对男女牵线成功),传授给读者一些人生经验。
遍历左侧所有顶点(男生):
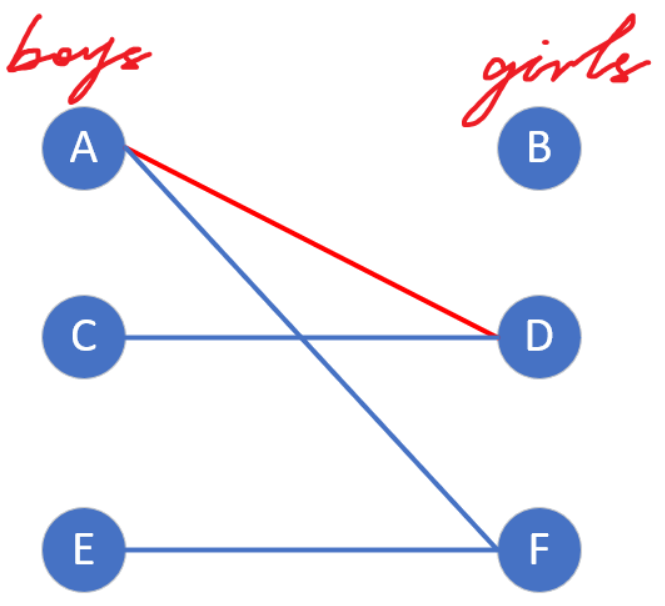
A的第一个喜欢的女生是D,发现D还没有被匹配,就直接与它匹配,它们开始约会。
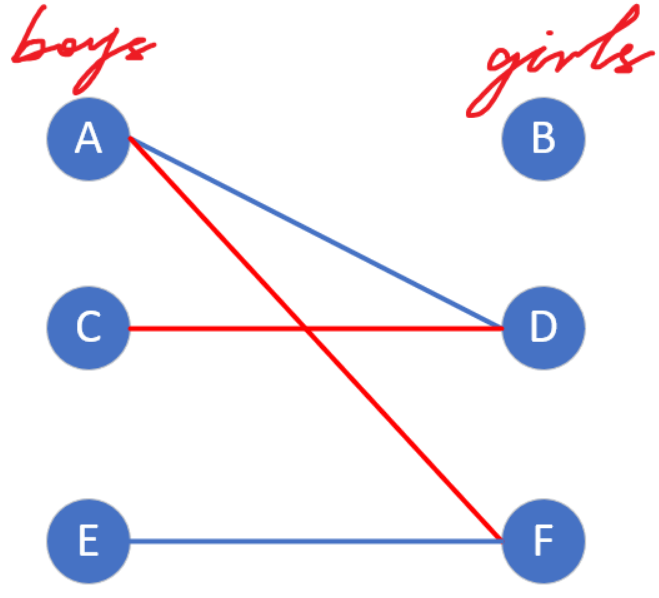
A匹配完成,开始与D约会。现在要为下一个男生C牵线搭桥,C第一个喜欢的女生是D,而D已经与A匹配了,这时怎么办呢?C会直接对D表白,我想要与你约会,如果你现在有男朋友,就看看你的现男友有没有其他喜欢的女生,让他换一个对象;如果没有,现在就跟我处对象。
当天晚上,D就会去告诉A:”你如果有其他喜欢的女生,就去尝试跟她匹配吧,如果匹配上了,就忘了俺,俺去跟C好了,如果你实在找不到,那俺也不会抛弃你,继续跟你好。
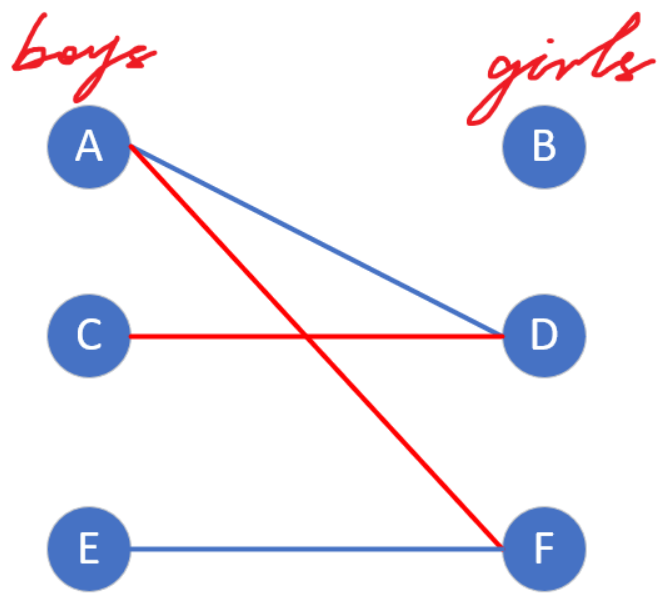
A也不生气,因为他已看破红尘,D这样坦诚对双方都有好处。接着他就去找他其他的暗恋对象,发现F没有匹配,于是乎,皆大欢喜。
现在A和C都已经找到对象了,小E也准备着去跟暗恋多年的对象F告白了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include <iostream> #include <cstring> using namespace std;const int N = 510 ;const int M = 1e5 +10 ;int n1, n2, m; int h[N], ne[M], e[M], idx;int matched[N]; bool callDibs[N]; void add (int a, int b) e[idx] = b; ne[idx] = h[a]; h[a] = idx++; } bool find (int x) for (int i = h[x]; i!=-1 ; i = ne[i]) { int succ = e[i]; if (!callDibs[succ]) { callDibs[succ] = true ; if (!matched[succ] || find (matched[succ])) { matched[succ] = x; return true ; } } } return false ; } int main () memset (h, -1 , sizeof (h)); scanf ("%d%d%d" ,&n1, &n2, &m); int x, y; for (int i = 0 ;i<m;i++) { scanf ("%d%d" ,&x ,&y); add (x, y); } int res = 0 ; for (int i = 1 ; i<=n1;i++) { memset (callDibs, 0 , sizeof (callDibs)); if (find (i)) res++; } printf ("%d\n" , res); return 0 ; }