《计网》Network-Layer-ControlPlane
网络层control-plane实现的是一个 网络范围 的逻辑,这个逻辑不光决定了通信双方的逻辑链路,还决定了管理网络层的服务和其他功能。
5.1 Introduction
网络层data-plane的功能是根据路由表提供的信息来forwarding数据包,那么路由表是如何被计算出来的呢?有两种可能的方案:
Per-router control。即每一个路由器上不光有forwarding的功能,还要有计算routing的功能。
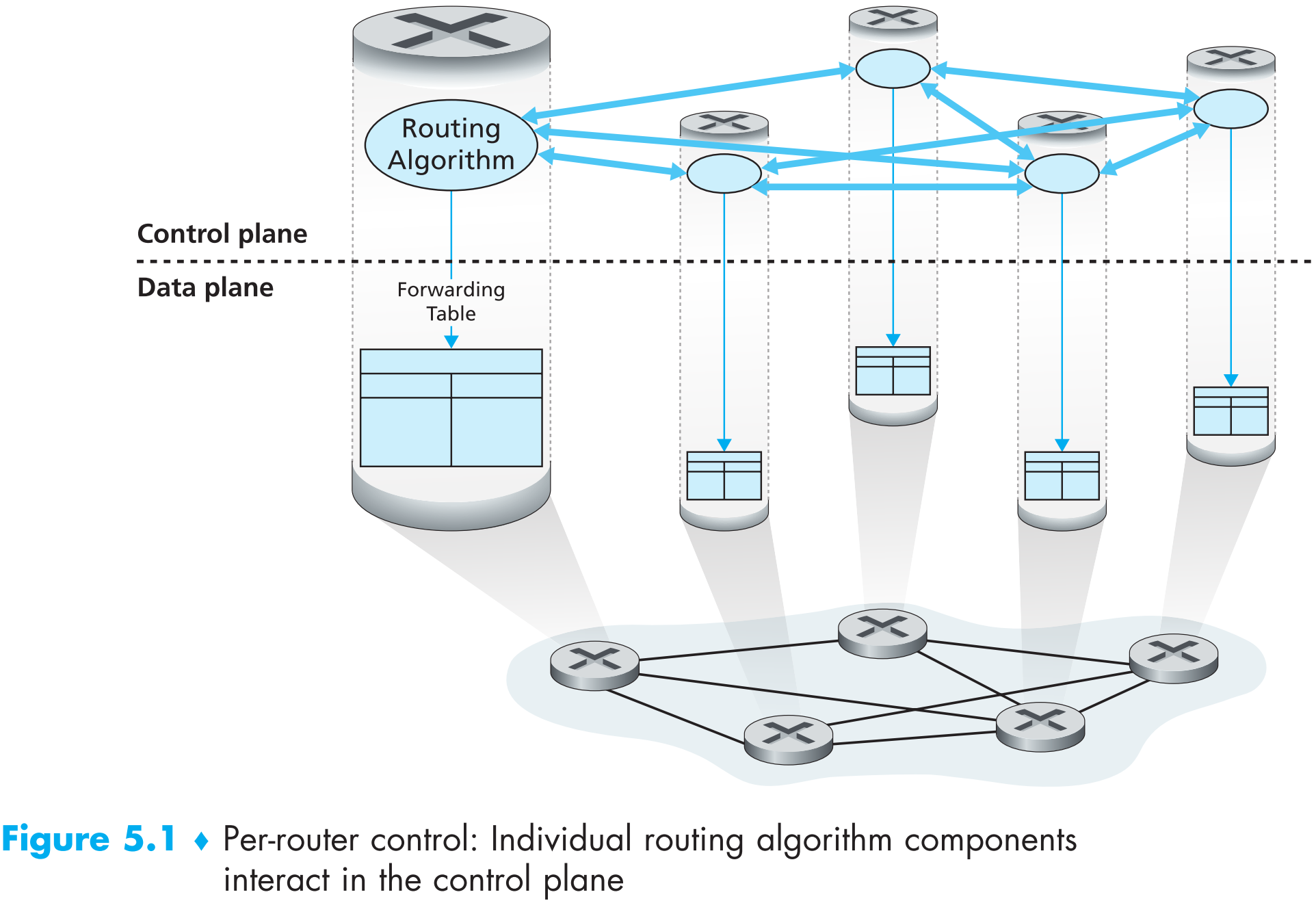
Logically centralized control。所有路由器将自身状态信息传输给一个logically centralized控制中心(controller),控制中心将每个路由器的路由表计算好后分发给它们,如下图
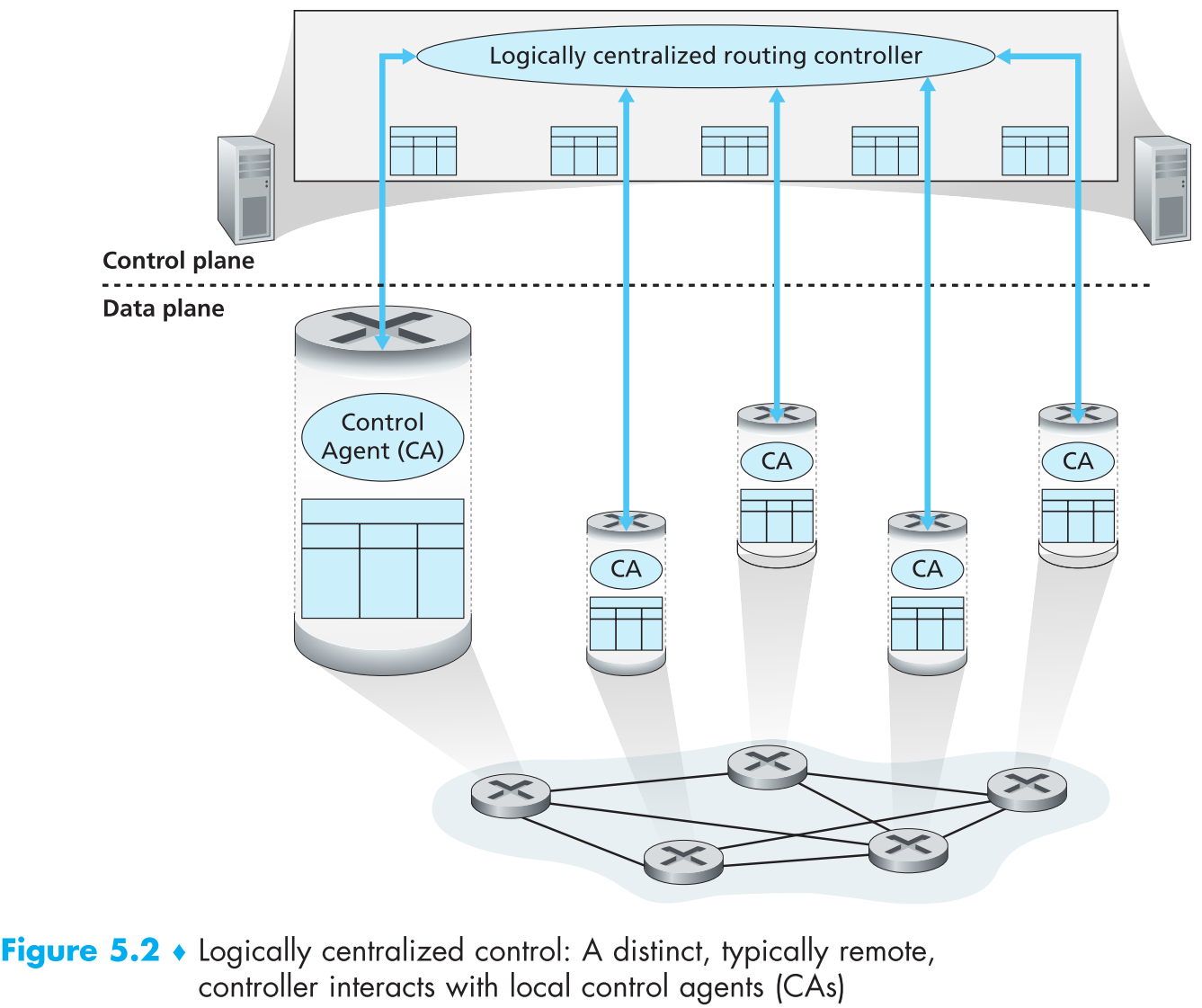
该方案下每一个router内置有 control agent(CA) ,controller通过一种协议与CA交互来配置和维护该router的路由表。CA的功能十分简单:与controller通信,在router上执行controller的命令。另外要注意的是,与第一种方案不同,该方案下CA之间不能直接交互,更不能自己计算路由表,即路由器之间的信息交互必须通过controller完成。
logically centralized这个名字就说明了central contoller实际上不止一个,为了提高容错率(fault-tolerance)以及性能,logically centralized controller事实上是一个服务器集群。
5.2 Routing Algorithms
routing algorithm的目的就是在sender和receiver之间规划出一条最合适的逻辑链路,因为在现实情况中可能有一些特殊情况要考虑,比如B公司的流量不允许经过A的router转发,所以routing algorithm并不总是计算最佳路径。
图论可以将routing计算的问题转化为数学问题,回忆一下,$G = (N,;E)$ 代表一个具有N个顶点和E条边的图,对应到网络场景中,图中的顶点就是路由器,边就是连接两个路由器的链路。
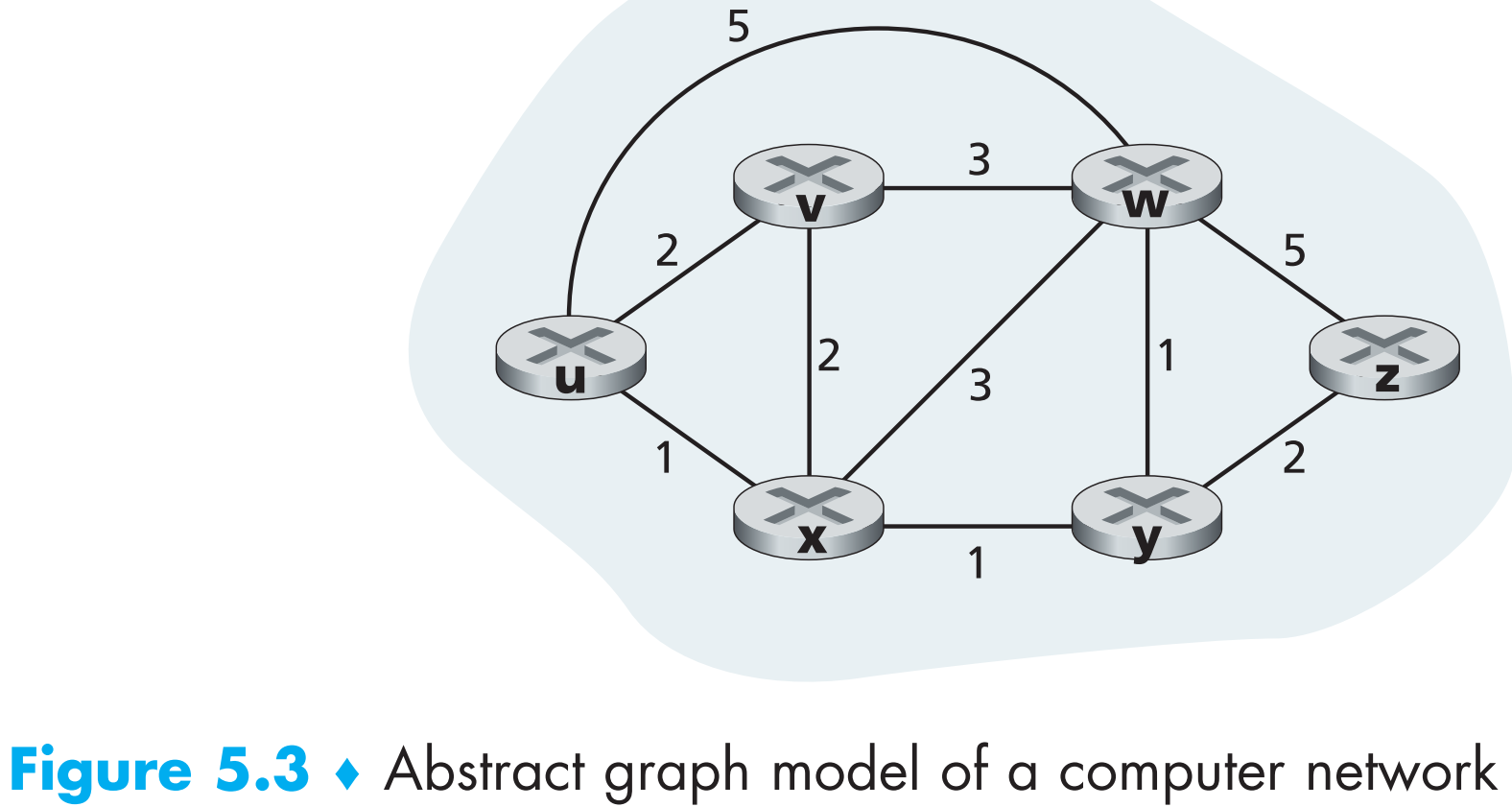
图论中通常每条边会有权重,对应地,网络中每条链路同样有权重(如上图)。网络图中边的权重通常可能代表这条链路物理上的长度,也可能是链路带宽,还可能是这条链路的造价。
对任意一条边$(x, y)\in E$,以后用$c(x,;y)$ 来代表这条链路的权重,如果$(x,; y)$这条边不存在,即$(x,;y)\notin E$,那么规定$c(x,;y) = \infty$ 。且之后我们讨论的都是无向图(但方向不同cost可能不同)——符合网络拓扑的实际情况,因此$(x,;y) = (y,;x)$ 且 $c(x,;y) = c(y,;x)$ 。如果$(x,;y)\in E$ 那么称x和y互为彼此的 neighbor 。
既然每一条边都有权重,那么我们现在的目标就是对图中任意两个顶点,能找出它们之间的 least-cost path 。比如上图5.3中从u到w的least-cost path为(w, x, y, w),总cost=3。如果一个图中【每条边的权重都相同】,那么least-cost path也叫做 shortest path——即两顶点间边数量最少的路径。
routing algorithms有很多种分类方式:
【按是否去中心化分类】
centralized routing algorithm 通过整个网络的全局完整信息来计算两顶点间的least-cost path,即进行路由计算之前必须要先获取整个网络的信息,之后的路由计算既可以在类似于远端的logically centralized controller上计算,也可以在每一个router上计算。该类算法的特点是它预先知道网络状况(整体拓扑和所有链路的cost),这种拥有全局视野的算法也叫做 link-state(LS)algorithms ,因为该类算法必须时刻关注【网络中所有】链路的状态。
decentrialized routing algorithm 通过所有路由器以迭代的分布式的方式【逐渐地】计算出least-cost path。任意一个路由器一开始只知道它直连的链路信息,之后通过与它的邻居路由器交换链路信息的方式不断更新自己的路由表。这类算法的典型是 distance-vector(DV) algorithm ,因为每一个router都维护了一个vector,这个vector中存储了用【当前】该路由器能够看到的链路信息计算出来的【整个网络中所有链路的costs】
【按算法是静态还是动态分类】
static routing algorithms ,一次性把所有路由器的路由表算清楚,之后通常由网络管理员手动更新路由表。
dynamic routing algorithms,当网络流量或者拓扑发生改变时,路由表随之被软件计算并动态更新。动态路由算法可以每隔一段固定的时间运行一次,也可以在网络拓扑或者链路cost发生变化时运行。显然动态路由算法能够更加及时的响应网络状态的更新,但是却更容易受到 路由环路(routing loops) 和 路由震荡(route oscillation) 的影响。
路由震荡指因为各种问题导致路由状态不断变化,比如某个路由器不断的开关,那么动态路由协议就会不断的更新,占用大量资源。
【按照是否负载敏感分类】
load sensitive algorithm,采用此算法后link cost会不断的动态变化,这个变化反映了链路的拥塞情况。当某条链路的cost过高时,routing就会尽量避免经过这条链路。
load insensitive algorithm, link cost不反映当前链路的拥塞情况,如今的RIP、OSPF和BGP等都属于这类。
5.2.1 The Link-State (LS) Routing Algorithm
link-state algorithm的特点就是它预先知道整个网络的拓扑结构以及所有链路的costs,这一点是通过【让每一个node广播自己的link-state packet(link-state broadcast)给所有邻居,也就是泛洪】来实现的,link-state packet中包含发出它的node知道的与自己直连的所有链路状态信息。当网络中所有nodes都获取到完整的链路状态时(收敛),它们就会【各自】开始运行LS algorithm来计算least-cost paths。
接下来我们要介绍的link-state routing algorithm 是著名的 Dijkstra’s algorithm ,该算法可以计算从任一node出发到图中其他所有nodes的least-cost path。
现在定义出发点为u,D(v)代表从u到v的least-cost path的cost,p(v)代表当前least-cost path上某一顶点v的上一个顶点,N’ 是所有已经计算出的从u出发经过least-cost path到达的终顶点的集合。来看看该算法的具体实现:
1 | /*Initialization*/ |
以下图为例,看看这个算法运行的整个过程(计算从u到其他所有顶点的最短路)

初始化时,当前已知的从u出发的least-cost paths就是u到它的邻居们(v,x,w)的路径,因此初始化完毕后算法当前得到的结果为:
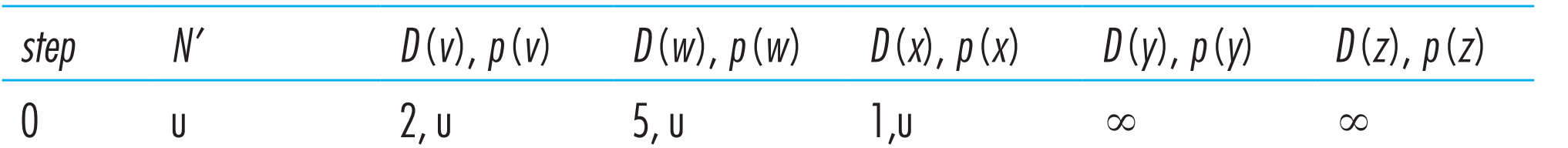
在Calculation的第一个循环中,我们要在【N’中不存在顶点】中选出一个顶点w,使得c(u, w)的path cost最小。因此选择cost=1的x顶点,然后把x加入到N’中。接着更新x的所有不在N’中的邻居:
1 | find w not in N' such that D(w) is a minimum //现在w是图中的x |
现在算法得到的结果为:
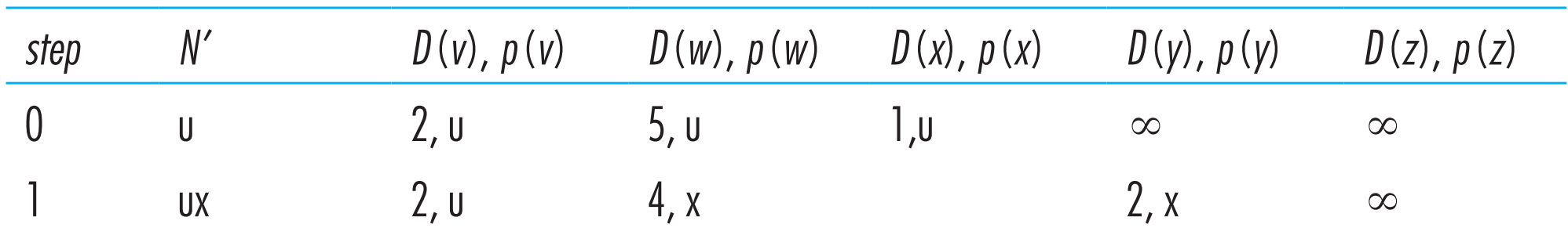
Calculation的第二次循环,与第一次类似:在【N’中不存在顶点】中选出一个顶点w,使得c(u, w)最小。有两个顶点可选——v和y,碰到这种情况就从它们中随机挑选一个,假如选定y,那么将y加入到N’中,接着更新y的所有不在N’中的邻居——w和z,得到如下结果:

不断重复Calculation,直到N’中包含了所有顶点,算法结束,总的结果如下:

此时D(w)就是从u出发到任一其他顶点w的least-cost path的cost,并且我们也知道每条least-cost path上任意顶点的前驱顶点,利用这些信息就可以构造路由表了
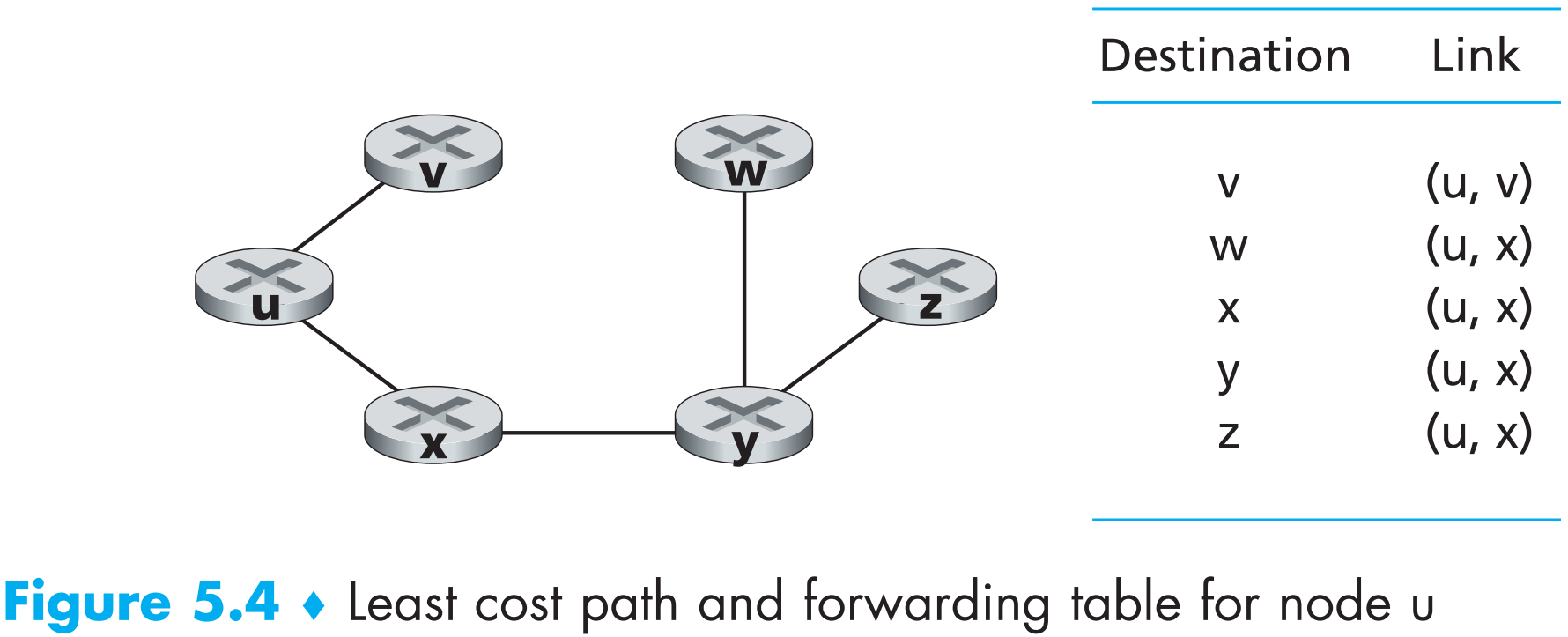
该算法时间复杂度为O(N^2)。
在结束本节之前再讨论一下这个算法可能会引起的问题。假如一个网络拓扑中所有的链路costs反映了它本身的拥塞状况。这时链路的cost就不一定“对称”了——c(u, v)不一定等于c(v, u),如下图
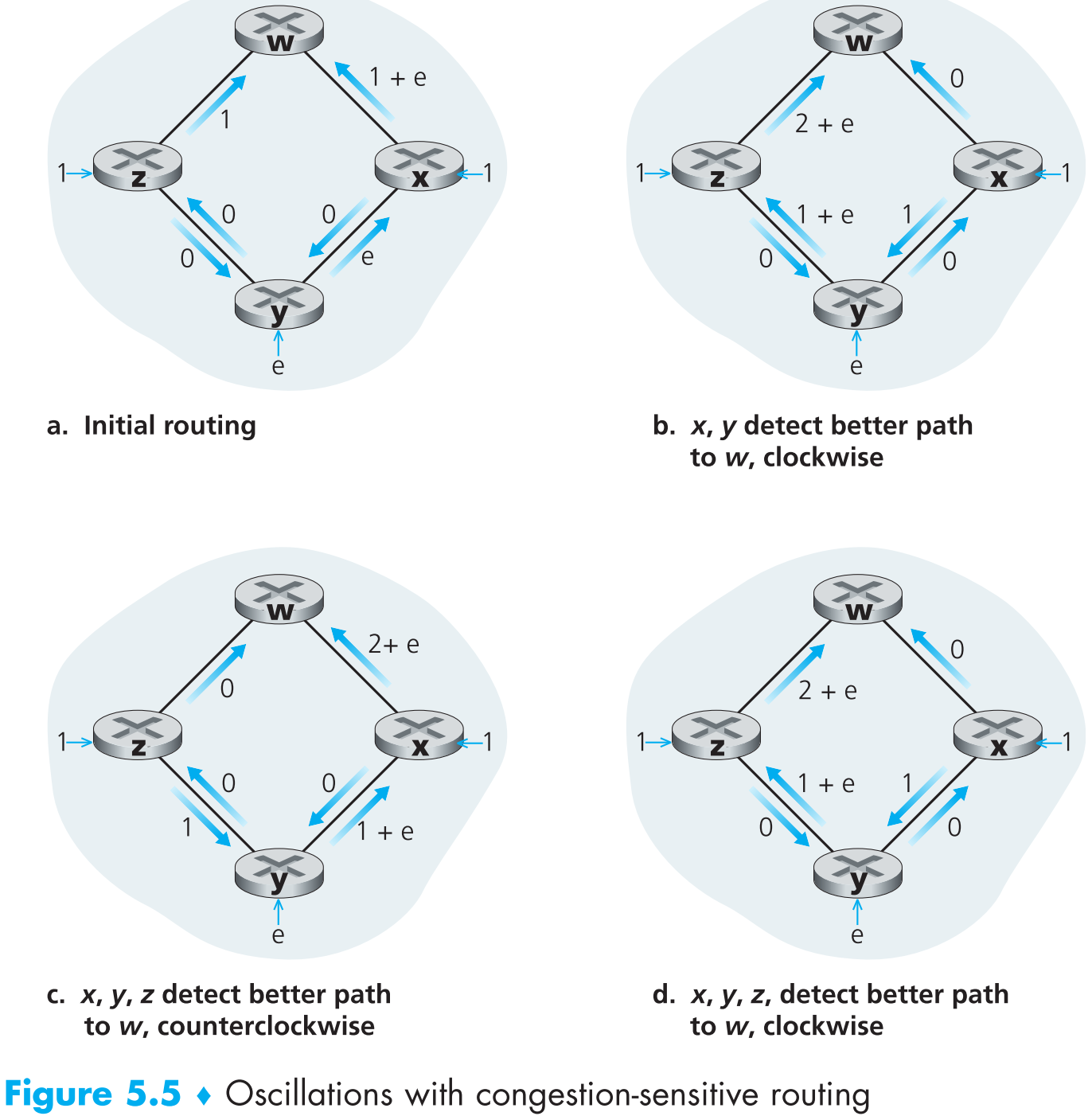
假设z和x各发送一个单位流量给w,y发送e个单位流量给w,那么刚开始的链路状况如上图(a)。
当LS algorithm开始运作时,计算得到y到w(顺时针)的cost=1,y到w(逆时针)的cost=1+e,那么算法当前计算出y到w的least-cost path为顺时针方向。类似地,x到w的least-cost path也为顺时针。计算完成后,将计算结果更新到每一个router的路由表,此时链路状况如上图(b)。
链路状态开始新一轮泛洪,这次收敛后顶点x、y和z都会发现自己从逆时针方向到w的cost为0,那么经过LS algorithm的计算后得到它们的least-cost paths全部变成逆时针,下一轮计算它们又发现顺时针方向到w的cost为0,又全部把least-cost paths变为顺时针…. 循环往复…如图(c)(d)。
这种“震荡”的情况在所有【使用链路拥塞情况作为链路cost】的算法中均会存在,如何避免呢?
一种方法是完全不将链路拥塞情况作为link cost。但是这种方法太走极端了,因为routing的一个目标就是避免链路拥塞。
另外一种方法是不让所有routers同步地运行LS algorithm,这好像可行,但是研究发现运行LS algorithm的网络中的router会self-synchronize,这就意味着即使刚开始让它们在不同的时间点运行LS algorithm,最终它们还是会自动把运行的时间点同步起来(lol)。后来通过实验发现了解决方法:让每一个router【向邻居广播链路状态packet的时间点】随机可以避免这个问题。
5.2.2 The Distance-Vector (DV) Routing Algorithm
distance现在可以理解为等同于cost
与LS algorithm用全局信息来计算路由不同,distance-vector(DV) algorithm的计算具有以下特点:
- 分布式的。DV algorithm中每一个顶点都只从【与它直连的邻居】处获取信息并计算,然后将计算结果反馈给它的邻居。
- 迭代式的。DV algorithm的计算会一直持续,直到任意两个邻居之间没有新信息可以交换。
- 不同步的。不会让所有nodes同时开始运行DV algorithm。
定义$d_x(y)$ 是从node x到node y的least-cost path的cost,那么可以通过Bellman-Ford方程(一种动态规划方程)计算最短路径:
$$
d_x(y) = min_v{c(x,;v)+d_v(y)}
$$
其中v代表x的所有邻居。该方程的含义为:在x所有邻居v中,找到这么一个邻居v*,使得 $c(x,v^{*})+d_{v^{*}}(y)$ 最小,且这个最小值就是x到y的least-cost path的总权值。
以如下拓扑为例,用Bellman-Ford方程计算从u到z的least-cost path:
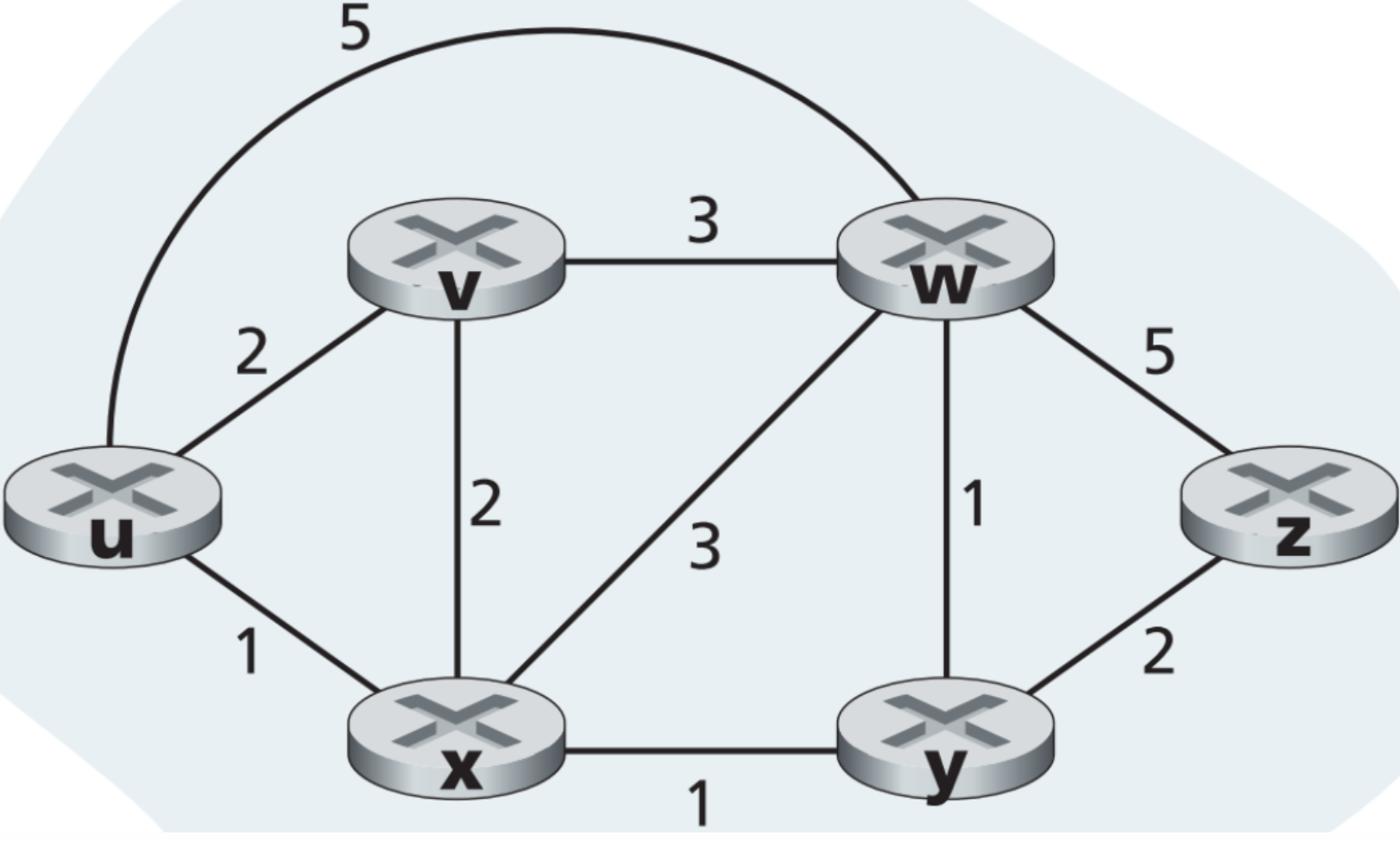
u有三个邻居v,x和w,且假设现在已知$d_v(z) = 5,;d_x(z)=3,;d_w(z)=3$ ,那么只要再根据$c(u,v)=2,;c(u,x)=1,;c(u,w)=5$,利用Bellman-Ford方程可计算得到$d_u(z)=min{2+5,5+3,1+3}=4$ ,与之前Dijstra计算的结果相同。
因此,Bellman-Ford方程的一个重要应用就是计算网络拓扑中某个node的所有路由表条目:假定x的任意邻居为v,v*代表Bellman-Ford方程在所有v中已经找到的x的“最小”邻居。现在如果x想通过least-cost path给y发数据包,那么数据包必然要先发到v* ,因此x的路由表中终点为y的条目的next hop就是v* 。
在DV algorithm中,每一个node x都维护以下路由信息:
- 从x到其所有邻居v的cost
- node x自己的distance vector ,里面存储了node x到所有其他所有顶点node y的cost
- x的所有邻居v的distance vectors(因为要与邻居交换链路信息)
启用DV algorithm后,网络中每个node会时不时的将自己的distance vector广播给自己的邻居,当一个node x收到它的某个邻居node w发来的【新】distance vector时,会先将其保存,然后利用Bellman-Ford equation更新自己的distance vector,如果自己的distance vector确实被更新了,那么node x会立即将自己更新后的distance vector广播给所有邻居。上述步骤不断重复,最终网络中所有nodes自己的distance vector会趋于相同,routing完成。
5.2.2.1 Distance vector(DV)algorithm
下面来看看DV algorithm的具体实现(其中N代表除了node x之外的所有nodes,$D_x$代表node x的distance vector,$D_x(y)$代表distance vector中存储的从x到y的least-distance path的cost):
对每一个node x:
1 | /*Initialization*/ |
从上述伪码中可以看到DV algorithm中,当某node x察觉到它到某一个邻居的cost改变——即【收到neighbor发来的新distance-vector】时,它就会利用这个新distance-vector中的信息通过Bellman-Ford equation计算得到并更新自己的distance-vector,如果这一步骤中能计算出一条新的least-cost path,就会立即将自己更新后的distance-vector广播给邻居。
如果node x想要更新路由表条目(比如到y的路由条目),那么它仅仅需要知道v* ——即到y点cost最低的邻居——是自己的next hop(如果有多个则随机选一个)即可,而非自己到y的完整最短路径。
回忆一下LS algorithm属于centralized algorithm,因为它要求每一个node在运行路由算法前必须获取到网络拓扑中所有链路的完整信息;而DV algorithm被归类为decentralized algorithm,因为它并不要求每一个node都必须获取到完整的网络信息再开始计算路由表,相反,每一个node都只需要与自己直连的所有邻居提供的链路信息即可计算出当前路由表,然后不断通过邻居提供的新信息来更新自己的路由表,并且将自己的路由表也广播给所有邻居来向它们提供自己所看到的网络拓扑信息。
下图是一个使用DV algorithm的网络示例:
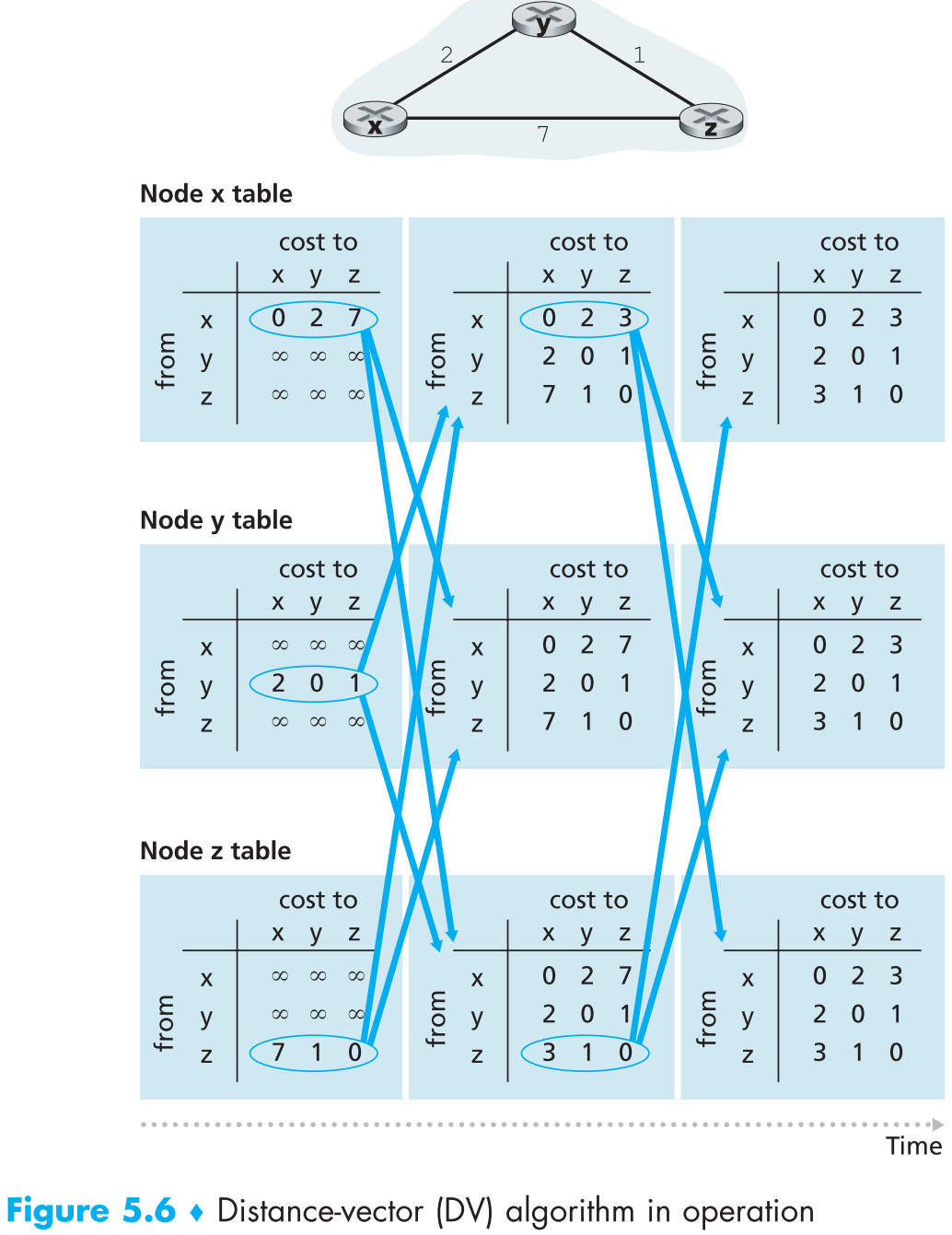
5.2.2.2 Distance-Vector Algorithm: Link-Cost Changes and Link Failure
上一节我们学习到,当一个运行DV algorithm的node察觉到直连链路的cost变更时,会更新自己的distance vector,如果更新后发现有least-cost path改变,就会将更新后distance vector广播给自己的邻居。
现在给出这个过程的实际例子,如下图,假如y到x的link cost从4变成了1
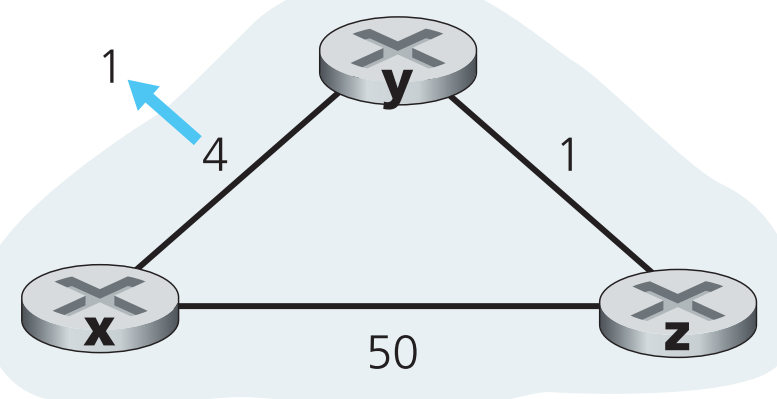
DV algorithm会引发以下事件:
- 在t0时,y觉察到了直连的link-cost发生变化(4→1),随即更新它的distance vector,然后将其广播给所有邻居
- t1时,z收到了y的distance vector并用它更新了自己的distance vector,发现自己到x的least cost path可以更新了(从原来cost=50降到2),因此将least cost path更新并将新信息广播给所有邻居
- t2时,y收到了z的更新信息并用它更新自己的distance vector,不过更新后y并没有发现任何新的least cost path,算法进入quiesecent state。与此同时,【x到y的link cost降低】的这个好消息在网络中扩散
这种情况下,一切正常。
现在假定y到x的cost不是下降,而是上升(从4增长到60),如下图:
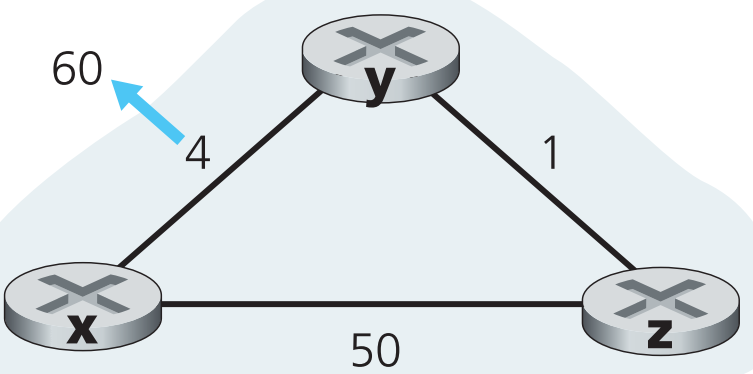
这时DV algorithm会引发如下事件:
假定在link cost变更之前:
$$
D_y(x)=4,;D_y(z)=1,;D_z(y)=1,;D_z(x)=5
$$
在t0时,y察觉到link-cost变更,这时它会更新自己的distance vector,并且尝试计算有没有新的least-cost path。
$$
D_y(x) = min{c(y,x)+D_x(x),c(y,z)+D_z(x)}=min{60+0, 1+5}=6
$$
站在上帝视角来看,这个新的path显然是错的,但是现在y只知道它直连到x的链路cost=60,而在最近一次z发给y的distance vector中z表示自己到x的cost=5,因此y现在会选择先经过z再到y。现在我们就碰到了一个DV algorithm引发的问题:routing loop——【为了去x,y的发出的流量会先经过z,但是z的流量去x又要经过y】,这时(t1)所有目标为x的流量只要经过y或者z,就会一直在y和z之间反复横跳。
下一次链路信息泛洪收敛时,z会收到y提供的新信息(y到x的cost=6),计算出最小的到x的新路径
$$
D_z(x) = min{50+0, 1+6}=7
$$
然后把新信息广播出去。在收到z的新distance vector后,y又会算出它到x的新路径cost为8,并将其广播,z收到后算出自己到x的新路径cost为9,然后将新信息广播,一直循环下去….也就是说每一次链路信息泛洪收敛时,y经过z到x以及x经过y到x的最短路cost就会++,这就是DV algorithm会引发的另一类 count-to-infinity 问题(这里手动模拟下更好理解)。
当z经过y到x的最短路cost累加超过50时,z到x的最短路cost就会更新成50(直连到x的链路),它会将这个新路径信息广播到y,y收到后计算出新的path到x(cost为51),终于,我们从上帝视角可以看到这次计算出的最短路结果是正确的。
本例中仅仅将link cost从4变为了60,如果变成了10000,且z直连到x的cost变为9999呢?y和z之间要进行多少次无用的信息交换才能使算法继续正常运行?
(最好自己在上图模拟算法走一遍方便理解)
5.2.2.3 Distance-Vector Algorithm: Adding Poisoned Reverse
解决5.2.2.2中routing loop问题的一种方法是 poisoned reverse ,它具体的策略是(以5.2.2.2拓扑图为例):
只要当前z所记录的自己到x的least-distance path要经过y,那么z在之后的链路信息泛洪中就一直会“欺骗y”自己与x直连路径的距离为无穷大(事实上c(z, x)=5),直到什么时候z到x不用经过y了,z才会把真话告诉y。该方法能解决路由环路的关键在于【只要z到x要经过y,那么y到x就不会经过z】
但是该方法并【不能解决】三个或三个以上nodes形成的路由环路问题,而且也无法解决count-to-infinity问题。感兴趣的同学可自行搜索这些问题的解决方案。
5.2.2.4 A Comparison of LS and DV Routing Algorithms
定义N是所有routers/nodes的集合,E是所有links/edges的集合,接下来对两种算法进行对比:
Message complexity
LS需要每一个node获取全网链路的信息,那么每一条传播链路状态的信息的空间复杂度为$O(|N||E|)$ ,且只要一条link的cost发生改变,那么这个变更的信息就需要泛洪到所有其他nodes。
而DV仅仅需要每一个node获取自己邻居的信息,而且当某一条link的cost改变后,变更信息仅仅需要发送给那些【因为这条link的cost改变导致计算出新的least-cost path】的nodes。
Speed of convergence
LS拥有明确的收敛时间复杂度$O(|N|^2)$ ,DV的收敛时间复杂度不确定——但是肯定比LS慢很多,而且DV还会出现很多问题比如routing loop、count-to-infinity等。
Robustness
LS中每个node单独计算它们的路由表,因此即使发生错误(比如router广播了bit错误的链路信息给邻居),也因为路由计算是分隔开的所以不会被传播的太远,因此健壮性较好。
DV中一个node可能会把计算错误的链路信息散播到另外一个或多个节点,因此一个node的计算错误会扩散式的传播。1997年就曾因为一个小ISP的路由的错误计算导致整个互联网的大部分区域瘫痪几个小时。
LS和DV各有各的长处和缺点,如今两种算法都在被广泛使用。
5.3 Intra-AS Routing in the Internet: OSPF
现实情况中,不管是LS还是DV都不可能被直接应用在整个互联网范围,原因有二:
- Scale 。像Internet这种规模的网络,如果直接对其整体应用LS算法,那么每个路由要存储全网的链路信息,这完全是不可能的;对应的,如果直接对其整体应用DV算法,由于规模过于庞大,链路信息根本就不可能收敛。
- Administrative autonomy。第一章中我们提到过互联网其实可以看作是一个由ISPs组成的网络,其中每一个ISP又拥有它自己的网络,那么每个ISP对自己的网络需求不一定相同(比如自己的网络用RIP还是OSPF算法)。
这两个问题都可以通过 autonomous system(ASs) 的结构组织网络来解决:每一个AS【由多个routers组成】并且它们【受到统一的管理和控制】(比如都运行RIP协议)。一个ISP通常会将自己的网络组织成一个AS,不过也有些ISP会将自己的网络划分为多个互联的ASs。一个AS通常由一个全球唯一的 autonomous system number(ASN) 标识,类似于IP地址,ASN也是由ICANN regional registries统一分配的。
一个AS中的所有routers运行相同的routing algorithm,这种在AS【内部】运行的routing algorithm被称为 intra-autonomous system routing protocol 。
Open Shortest Path First(OSPF)
OSPF和它的“表兄弟”IS-IS协议在互联网的intra-AS routing中使用非常广泛。OSPF中的O=open代表这个协议是开源的(与之相对的EIGRP协议则是思科的私有intra-AS 路由协议——不过2013年也已经开源了)。
OSPF属于LS协议——泛洪链路状态信息且采用Dijkstra’s最短路径算法。运行OSPF的每一个router都会:
- 维护其所属AS所有的链路状态信息
- 运行Dijkstra’s least-cost path algorithm来计算以它自身为root到当前AS中所有子网(所有其他路由器的所有接口)的最短路径树
OSPF中所有的link costs都由网络管理员指定。比如可以将所有link costs都设置为1来实现minimum-hop routing,或者让所有link costs反比于该链路的带宽来避免流量拥挤,这提供了很大的灵活性。
在运行OSPF的AS中,每当一个router发现自己直连的链路状态发生改变(link cost改变或者链路up/down),或者一段固定时间间隔(最少30分钟)后,它就会将自己的routing information(OSPF advertisement)广播给AS中所有其他的routers(而非仅仅广播给它的邻居)。
OSPF advertisement被封装在OSPF message中,由IP协议直接封装并运输,上层协议的端口号为89(这意味着OSPF message并不使用UDP或者TCP作为传输层协议,而是自立门派),因此OSPF协议自己要实现一些运输层的功能比如可靠传输等。OSPF router可以通过发送HELLO message检查自己与邻居的链路情况以及获取邻居的全AS链路状态数据库。
OSPF的特点如下:
Security。OSPF routers之间交换信息(比如链路状态信息)之前要先认证,只有被信任的router才有资格加入到本AS的OSPF拓扑中,这样就可以避免一些恶意行为。不过要注意的是OSPF默认不启用认证。
认证的方法有两种:【simple】,每个路由器上存储相同的密码,发包时将该密码明文放在数据包中一起传输,这种方法不是很安全。【MD5】具体工作原理可自行搜索。
Multiple same-cost paths。如果到同一个终点的多条链路costs相同,那么数据将通过这些链路【共同】传输,也就是可以实现负载均衡。
Integrated support for unicast and multicast routing。Multicast OSPF(MOSPF)将OSPF功能扩展,其具有多播的功能。
Support for hierarchy within a single AS。一个运行OSPF的AS可以具有【分级areas】的结构,每一个area都独立运行OSPF协议,且每一个area中至少有一个 border router负责与其他areas交换信息,一个area中除了border router的所有其他routers都只与本area中的其他routers交换链路信息(即不同area的路由器不能直接相互交换链路信息)。每个AS中【有且仅有一个】 backbone area 包含了本AS中所有areas的border routers(也可能包含non-border routers)。一个AS中所有inter-area(跨area) 的通信数据必须先通过intra-area(area内) routing发到本area的border router,然后该border router在backbone area中将信息路由到目标area的border router,最后目标area的border router通过intra-area routing再将通信数据路由到目的终端。
5.4 Routing Among the ISPs: BGP
OSPF属于intra-AS路由协议,它只提供AS内的路由,那如果想让不同的AS之间相互通信呢?使用inter-AS routing protocol 。目前互联网统一使用的inter-AS routing protocol是 BGP(Border Gateway Protocol) ,它是Internet中最重要的协议之一。
BGP同时属于我们之前介绍的decentralized、asynchronous以及DV协议。
5.4.1 The Role of BGP
我们知道对于一个AS内部的任意destination,这个AS中任一路由器上运行的intra-routing protocol一定可以计算出它到这个destination的least-cost path。那如果destination不属于本AS呢?这时就需要BGP出场了。
在BGP中,数据包不是被route到一个指定的destination address,而是被route到该destination address所属的网段(即CIDR记法的前缀),因此在BGP眼里,IP地址都是类似于【138.16.68/22】这样的形式。
BGP为路由器提供如下功能:
- Obtain prefix reachability information from neighboring ASs。BGP能够将互联网中某一子网A的信息通过邻居广播的方式发送到其他所有子网,以此让Internet中所有路由器都学习到子网A的信息,顺便也能证明子网A的存在性。
- Determine the “best” routes to the prefixes。利用从邻居处获取到的子网可达性信息,每一个路由器都可在本地运行BGP route-selection进程来计算到达目标子网的最佳路径。
5.4.2 Advertising BGP Route Information
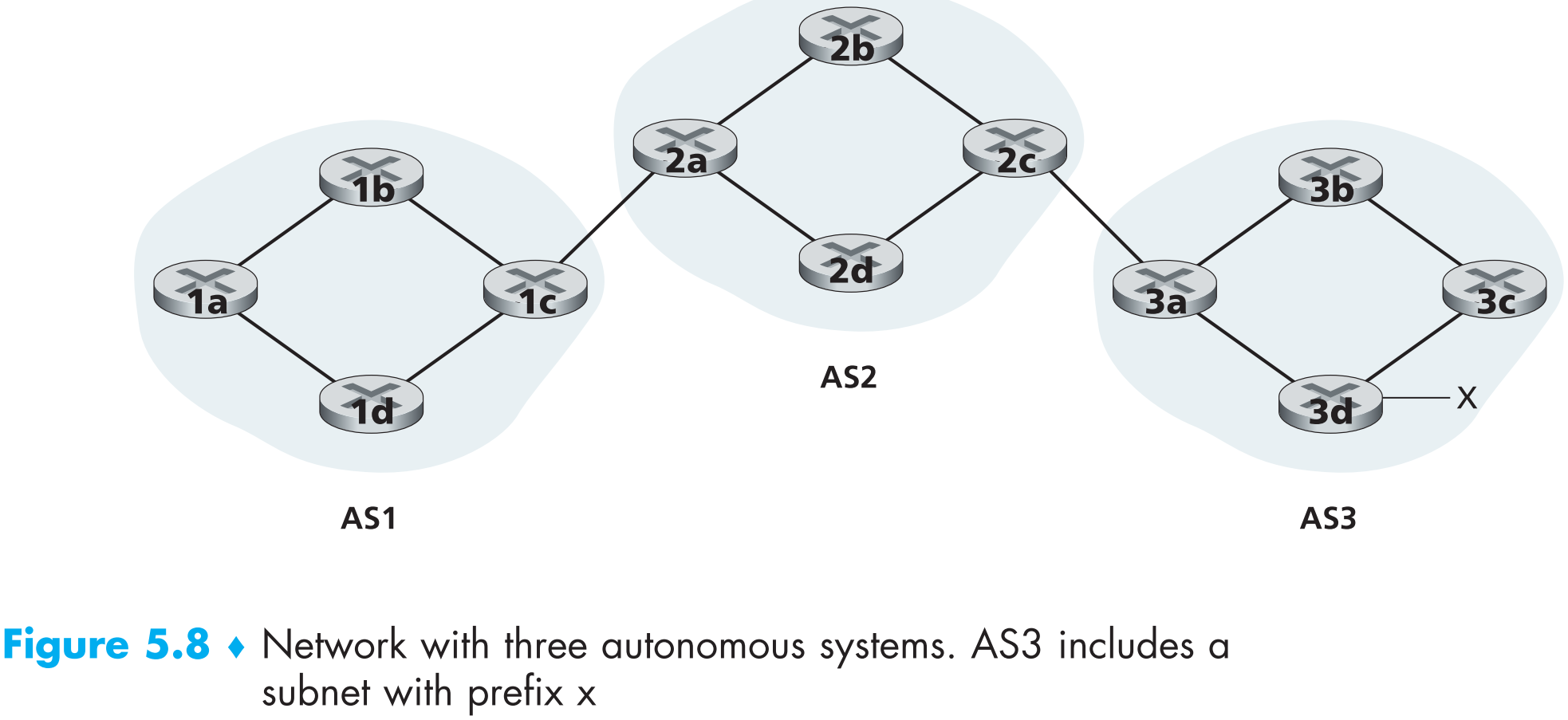
如上图,每一个AS中有4个routers,gateway router是与另一个AS直连的router(如AS1中的1c和AS2中的2a),另外3个都是 internal router (如AS1中的1b)。现在我们看看子网x的信息是如何被advertise到AS3之外所有ASs上的:
- AS3发送包含子网x信息的BGP message到AS2(假定该message的形式为AS3 x),相当于告诉AS2我这里有个子网x。
- AS2发送BGP message = “AS2 AS3 x” 给AS1,相当于告诉AS1:AS3是我邻居,刚才AS3跟我说了x在它那,你要找x的话要先经过我。
完成后AS2和AS1不但子网x存在,还知道子网x在AS3中,也知道了去x该怎么走。但是上述讨论其实是站在非常高层的抽象角度来看的,因为实际上是router而不是AS在发送BGP message,下面来详细讨论。
在BGP中,routers通过端口号为179的【半永久】TCP连接来互相交换路由信息,这种TCP连接叫做 BGP connection。跨AS的BGP connection称为 external BGP(eBGP) ,AS内部的BGP connection称为 internal BGP(iBGP) ,如下图
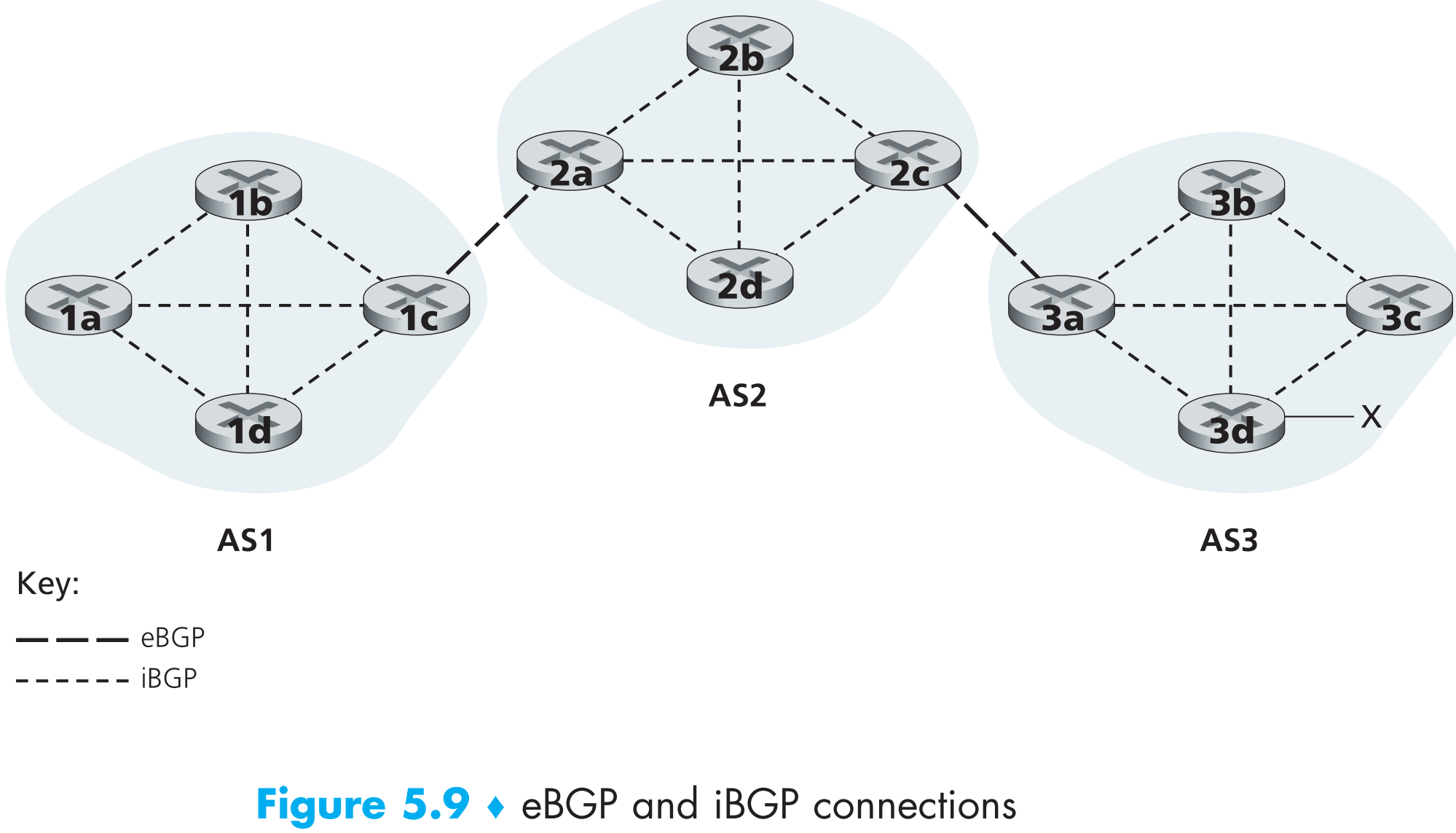
要注意的是iBGP并不总是一条实际存在的物理链路。
现在在来看看子网x的信息(advertisement)是如何被传播出去的。
- gateway router 3a发送 eBGP message = “AS3 x”给AS2的gateway router 2c
- gateway router 2c发送 iBGP message = “AS3 x”给AS2所有internal routers,2a接收到
- gateway router 2a发送 eBGP message = “AS2 AS3 x”给gateway router 1c
- gateway router 1c发送 iBGP message = “AS2 AS3 x”给AS1中所有internal routers
完成后,AS1和AS2中所有routers都知道子网x的存在,且知道去子网x该怎么走了。
5.4.3 Determining the Best Routes
BGP中,从某一个router到某一子网x的路径可能有多条,那么BGP如何从中选择一条最佳路径呢?
当一个router通过BGP connection传播某子网x信息时,这条信息中不光包含子网x的IP地址,还包含了其他一些重要的 BGP attributes,在BGP中这种【子网IP地址+与其对应的BGP attributes】组成的信息也叫做BGP route。
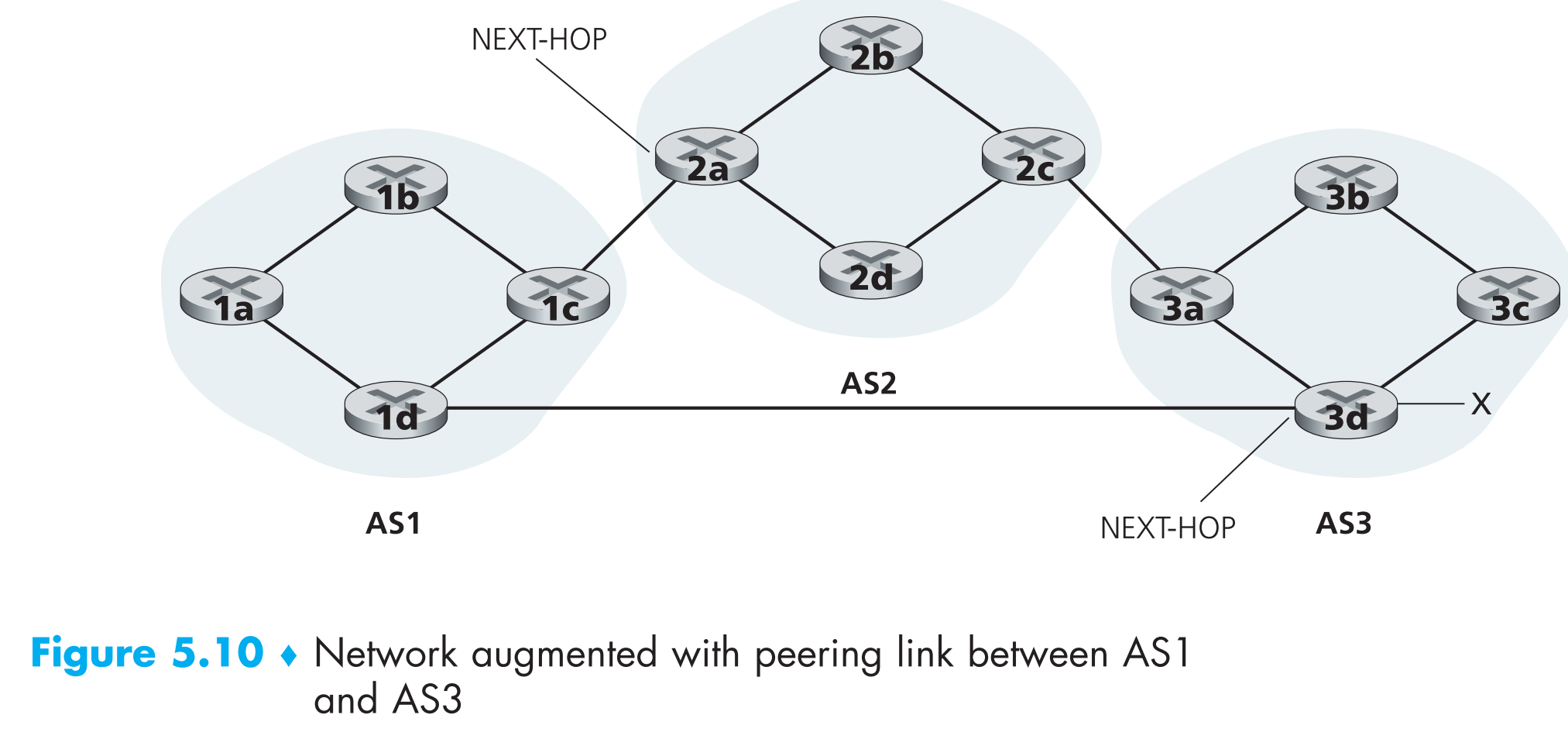
有两个BGP attributes最为重要:
- AS-PATH。其中包含了一个列表,里面存储了本条子网信息运输到此处已经跨越的所有ASs信息。子网信息每到达一个新的AS,就会往AS-PATH中添加这个AS的信息,如上图,从AS1到子网x共有两条routes,一条的AS-PATH = “AS2 AS3”,另一条的AS-PATH = “A3”。除此之外,AS-PATH还被BGP用来防止looping advertisements——如果一个router在一个刚收到的子网信息的AS-PATH中看到了自己所属的AS(也就是说自己去其他AS必须经过自己,那必然是环路了),就会将该子网信息丢弃。
- NEXT-HOP。它是开始计算AS-PATH的路由器接口IP地址。看上图,从AS1到子网x的route = “AS2 AS3 x”中的NEXT-HOP参数就是路由器2a左侧的接口;从AS1到子网x的route = “AS3 x”中的NEXT-HOP参数就是路由器3d左侧的接口。本例中,AS1内所有的routers都记录了到子网x的上述这两条routes。
5.4.3.1 Hot Potato Routing
继续以这张图为例讨论:
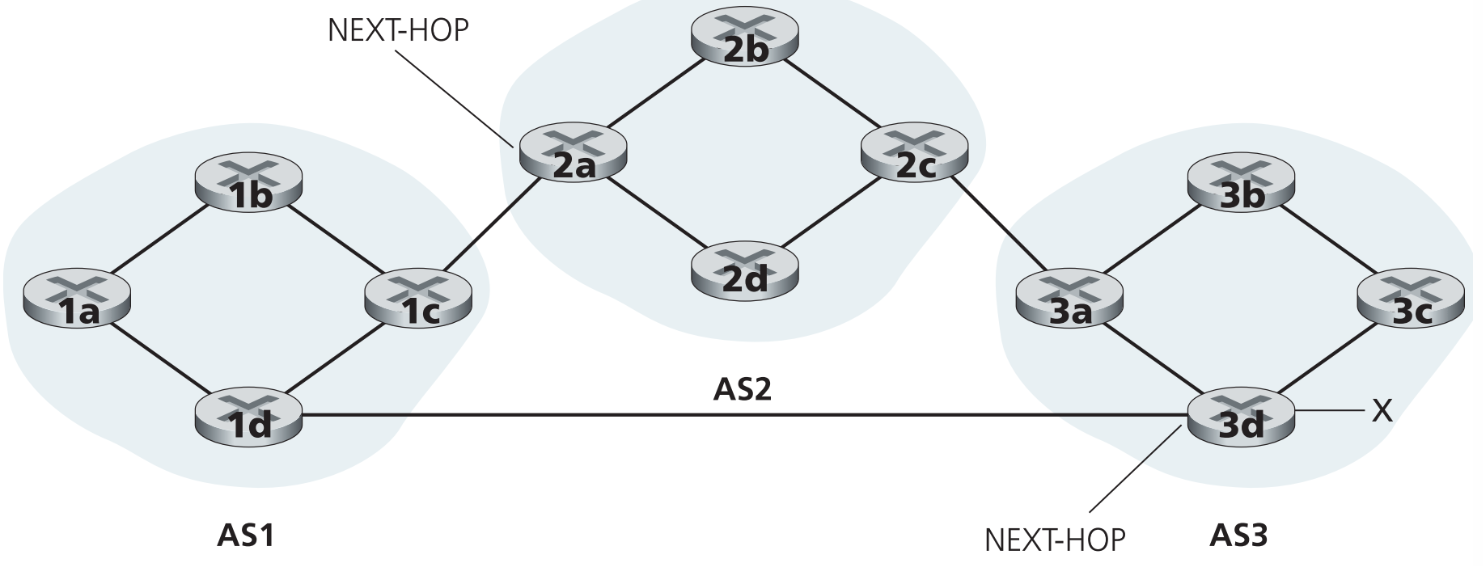
接着前面的,AS1中的路由器1b已经学习到去子网x的两条BGP routes。这时1b上如果运行hot-potato routing算法,那么该算法就会从所有这两条BGP routes中选择一条到达NEXT-HOP开销最小的那条route:1b首先查询本AS1内的所有路由信息,分别找到去往2a和去3d(的NEXT-HOP接口)的最短路(通过intra-AS路由算法比如OSPF计算得到),然后从这两条AS内的最短路中选择一条最短的作为最终route,最后1b将这条route=(x, I)加入自己的BGP路由表中。(I为1b在最终route上的出接口)
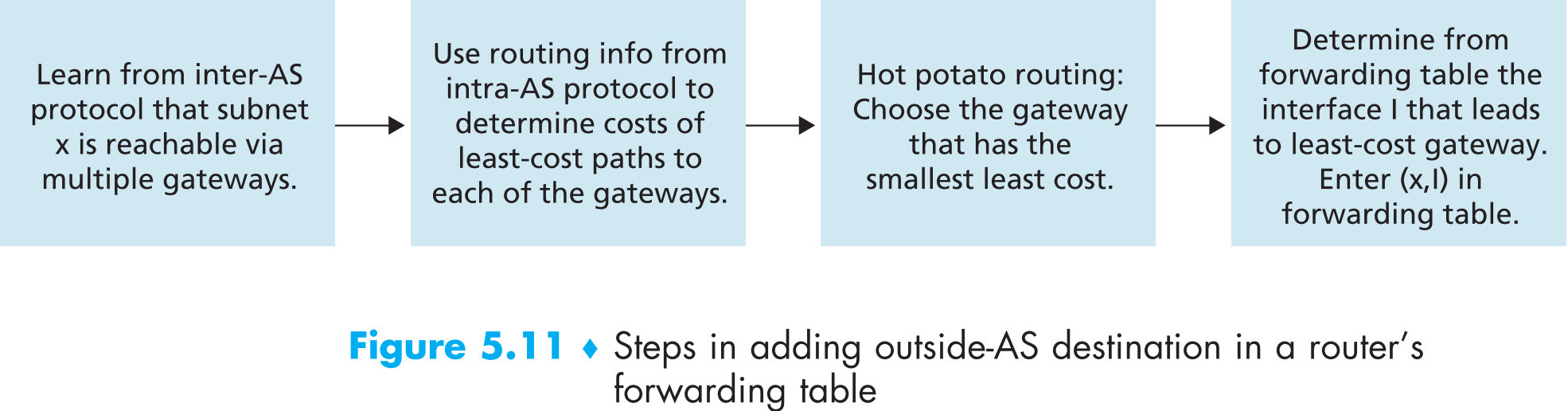
hot-potato算法的特点就是让1b尽快的将自己的数据送出本AS,数据在AS外如何传输它毫不关心——就像玩传递hot-potato的游戏,一个玩家拿到后只想尽快把它传递给下一个人。显然使用hot-potato算法时同一个AS中的两个router最终选择的去子网x的route可能不同,比如本例中1b向x发出的数据包会经过AS2再到达AS3,而1d则会直接发到AS3,因为该算法只求将数据送出本AS的速度最大化。
hot-potato算法的缺陷很明显,它只考虑了本AS内如何传输快,却没有”顾全大局”考虑AS间的传输方案,如本例中显然1b不经过AS2而是直达AS3传输距离最短,但是hot-potato根本考虑不到这一点。
5.4.3.2 Route-Selection Algorithm
现实中BGP并没有采用hot-potato算法,而是另一种类似的route-selection algorithm。
当一个router到某一子网的routes大于一条时,该算法会顺序执行以下步骤不断挑选route,剩余一条时停止:
route中还有一种BGP attributes:local preference 。路由器可以设置自己的local preference,也可以从本AS中其他路由器学习到,这个参数的取值完全取决于本AS的网络管理员。
第一步,将所有local preference最高的routes选出(选完后可能有多条local preference相同的routes)。
第二步,在第一步选出的routes中选出AS-PATH最小的routes(选完后可能多条routes的AS-PATH相等)。
第三步,在第二步选出的routes中使用hot-potato算法选择挑选routes(也可能选出多条)。也就是说,如果大家AS-PATH都一样,那么就选本AS中传输最快的routes。
如果还剩余多条routes,通过BGP identifier选择一条最终route
还是以这张图为例:

还是1b,它已经学习到去x的两条routes,如果用hot-potato算法,它最终会选择经过AS2的route。但是在route-selection算法中,运行hot-potato算法前会先执行步骤2——选出AS-PATH最小的route,那么在步骤2时经过AS2到达AS3这条route就已经被剔除了。
route-selection算法弥补了hot-potato算法的缺点。它先求整体,再求局部,避免了hot-potato可能造成的端到端延迟过高(即使本AS内传输很快,但跨越AS过多)问题。
BGP俨然已是互联网inter-AS routing算法的标准了,现实中BGP routing table是非常大的,一般tier-1的ISP路由器中包含routes的数量是百万级的。
5.4.4 IP-Anycast
做为inter-AS routing protocol,BGP也经常被用来提供IP-anycast服务。
有哪些场景需要用到IP-anycast呢:分发一段【相同】的数据到位于不同地理位置的多台服务器上,让用户从距离它最近的服务器上获取数据
比如CDN可以将一个视频复制多份分发到地址位置不同的多个服务器上,DNS system可以将DNS records复制多份分发到世界各地的DNS server上,用户可以从最近的服务上获取这种重复的内容。且这些任务很自然的可以通过BGP来完成。
通过一个实例来看看CDN如何使用IP-anycast:
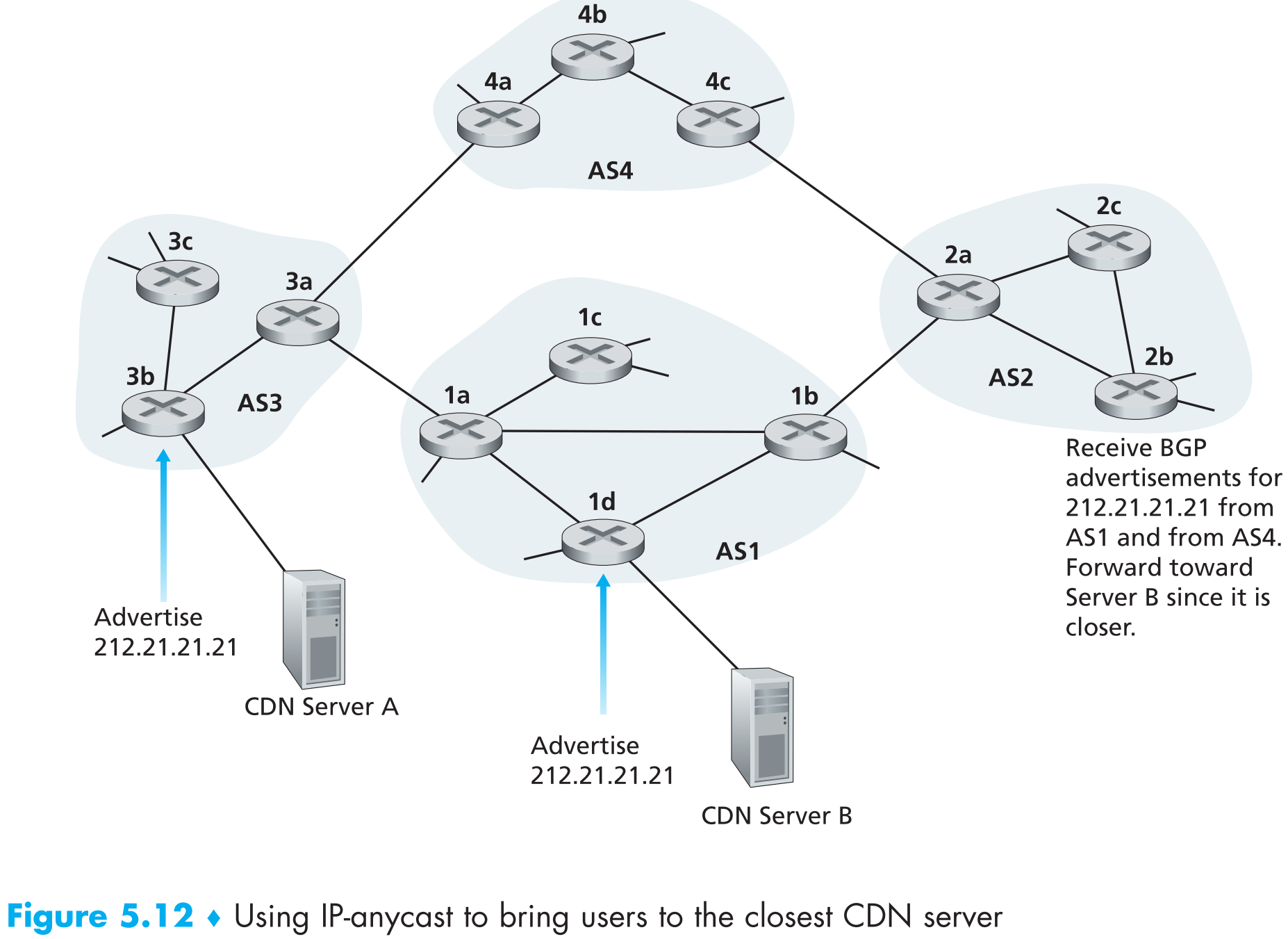
在IP-anycast的配置阶段,使用CDN的公司给所有server规划一个相同的IP地址,并使用标准BGP将该IP地址信息分发给所有servers:CDN首先泛洪多条(等于server总数)destination IP地址相同的BGP advertisements,当任意BGP router收到多个IP地址相同的routes时,它还以为这些routes提供了到同一个物理地点的多条路径(其实每条route都是到不同的物理地点),这时该router会在本地运行BGP route-selection算法从这些routes中选择一条最佳的(比如AS-HOP最少的route)插入自己的BGP路由表。
配置阶段完成后,每个router的BGP 路由表中都会存储一个去往距离它最近的CDN server的route。现在CDN就可以开始分发内容了。当一个client请求内容时,CDN会回复给client所有CDN servers的公共IP,然后client向这个IP地址发起请求,请求数据包经过BGP routers时它会“自动”将这个请求数据包递交到最近的一个server(通过route-selection算法得出)。
不过现实中CDN并不使用IP-anycast,因为BGP路由表的变化可能会导致一个TCP connection中传输的packets被分发到不同web server实例上。但是现实中DNS system在大量使用IP-anycast来将DNS queries递交到最近的root DNS server。
5.4.5 Routing Policy
以下图6个相互连接的AS为例:
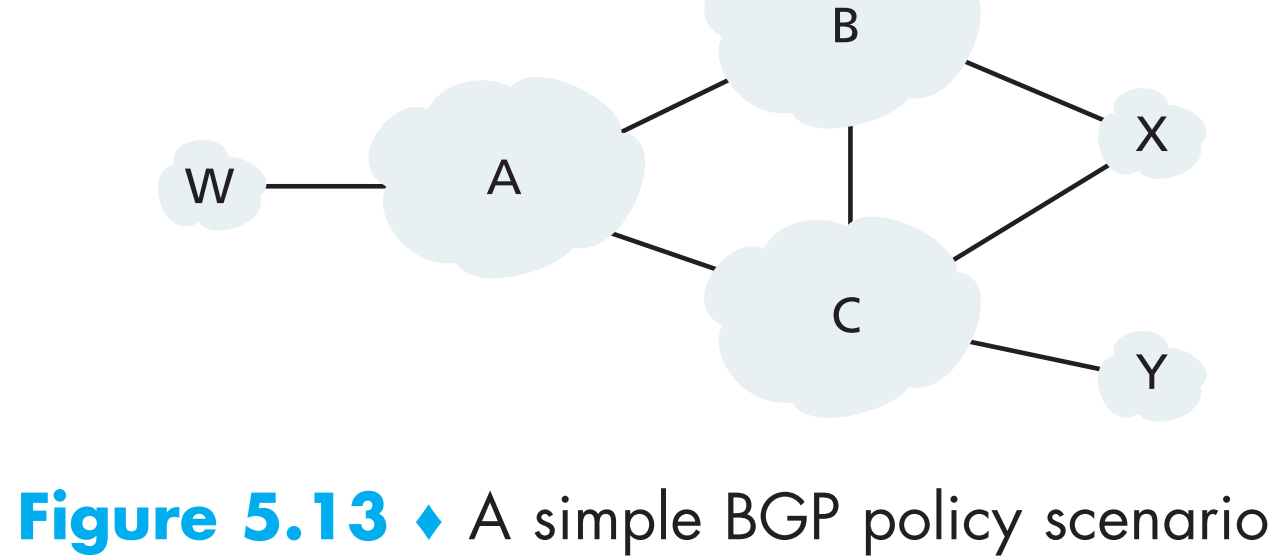
其中W、X、Y均为接入层ISP(access ISP)的AS,A、B、C均为骨干ISP(backbone provider network)的AS。A、B、C之间可以相互直接通信,且它们各自内部的routers都具有全网完整的BGP信息。
关于接入层ISP的定义:所有终点为接入层ISP的流量才能够进入接入层ISP,所有流出接入层ISP的流量只能源自于该接入层ISP——即接入层ISP一定位于网络的边缘位置。
W和Y显然都是access ISPs,而X因为连接了两个骨干ISPs,因此也被称作 multi-homed acccess ISP (在现实中这种情况很常见)。不过究其根本,X的定义为access ISP,那么它必须满足access ISP的定义,但是它又连接到了两个骨干ISPs,那么为了满足它为access ISP这个条件,必须避免让它转发B和C之间的流量,如何做到呢?可以通过控制BGP routes advertisement的方式来做到——X在自己advertise(给B和C)的BGP routes中谎称自己是一个存根网络,即在给B的advertisement中表示它只能跟B通信,在给C的advertisement中表示它只能跟C通信。这样B和C之间的流量就永远不会经过X了。这个例子说明了改变route advertisement policy可以用来定制接入网络和骨干网络之间的路由关系。
现在关于【backbone ISPs之间】如何路由并没有一个统一的标准,不过现实中各大(商业性质的)骨干ISPs都会要求所有经过自己的流量的【目的地或者源地址或两者】必须属于与自己直连的接入层网络,否则这些流量就是在白嫖自己的带宽。一些情况下两个骨干ISP可能会达成某些协议,那么流量如何在它们之间路由就是由它们定制了。
5.4.6 Putting the Pieces Together: Obtaining Internet Presence
假设现在你创立了一个小公司,拥有几台servers(如web server来宣传你的公司,mail server以及DNS server等),现在你想让全世界都能访问你的web server和mail server,需要进行以下步骤:
与当地的ISP联系来获取网络连接。ISP会给你安装一个gateway router,这个gateway router会连接(可能通过建立在有线电话基础上的DSL connection或者在Introduction章节中提到过的其他方式)到ISP内部的某router。此外ISP还会给你一个IP地址池(就是ISP通过其上层ISP给其分配的IP地址划分后的子网IP),就是gateway router连接到的ISP内部router的接口的IP地址代表的子网。
以上步骤完成后,你就要给自己公司内部的web server、mail server、DNS server、gateway router上的各个接口以及所有其他网络设备分配特定的IP地址。
与Internet registrar联系获取自己公司的域名。比如你的公司名字叫“Wudaokou Vocation and Technic College”,假定你想要申请的域名为“wudaokou.com”,那么你必须联系registrar注册这个域名(给它提供你DNS server的IP地址和想要注册的域名),来让外界可以通过域名访问你的DNS server进而获取你公司内其他servers的IP地址。registerar会将你申请的【域名-(DNS server的)IP地址】作为一个条目写入到.com的顶级域名服务器中。
现在外界可以用域名:wudaokou.com,通过DNS解析,获取到你公司DNS server的IP地址了。接下来,你要做的就是在自己的DNS server中插入想要添加的映射条目(比如www.wudaokou.com映射到公司内部web server的IP地址,mail.wudaokou.com映射到mail server的IP地址)。
现在假如Alice想要访问你的web server,它会在浏览器中输入www.wudaokou.com,接着DNS system会通过域名wudaokou.com对应的IP地址访问到你的DNS server,向你的DNS server请求www.wudaokou.com对应的IP地址,取得后将该IP地址回复给Alice,然后Alice就可以向这个IP地址发起TCP请求来获取网页内容了。
但是如果Alice(在地球的另一边)直接知道你公司web server的IP地址,然后不通过域名而是直接通过IP地址访问你的web server呢?
首先这个请求的数据包会在Internet不断的被路由转发,经过很多个ASs中的很多routers,最终到达你的web server。在这个过程中,当该数据包到达某一个router时,该router会查表来决定接下来将这个数据包发往哪个端口,因此每一个路由器都需要“知道”你公司的网络(local ISP给你分配的IP地址池)的存在,这是如何做到的呢?
当你联系local ISP并获取了一个IP地址池后,你的local ISP会用BGP advertisement将你申请的这个地址池(网络/网段)泛洪给它所有的邻居ISPs,如之前在BGP章节所述,这些ISPs收到你local ISP advertise的BGP route后,又会将该route信息advertise给它们各自的邻居…. 最终你公司的网络被“全网”(不考虑封锁的情况)的路由器都学习到了。
5.5 The SDN Control Plane
下面我们来学习SDN设备的routing、configuration以及management的逻辑。
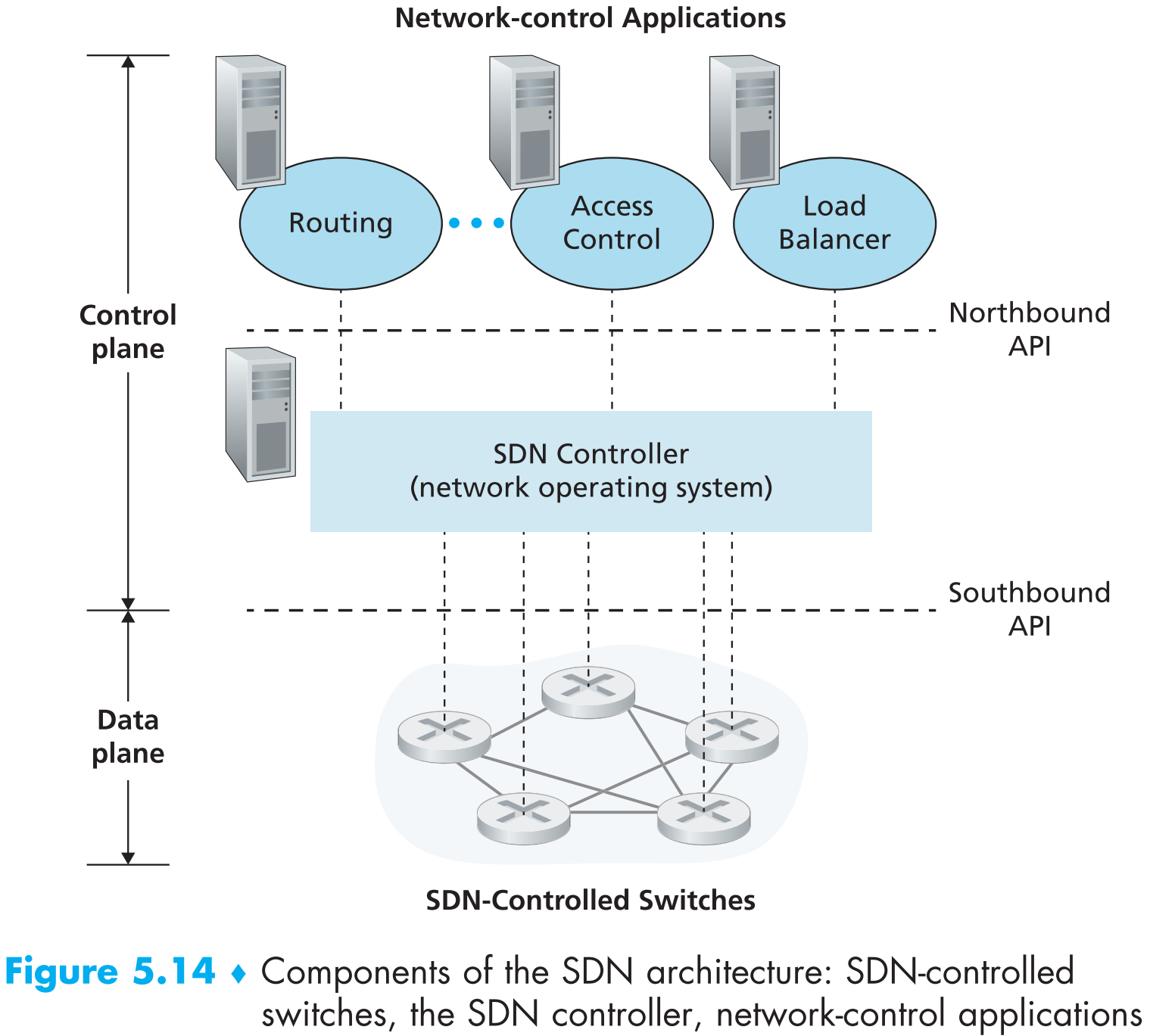
SDN架构的4个特点:
- Flow-based forwarding。启动了SDN的包交换机(广义)可以forward传输层、网络层或者链路层的数据包。比如之前我们学习的OpenFlow1.0就可以forward十一种不同的数据包
- Separation of data plane and control plane。data plane由所有启动了SDN的包交换机组成(执行match plus action功能);control plane由服务器集群和软件组成,决定并控制每一个SDN包交换机的flow tables。
- Network control functions:external to data-plane switches。SDN中的S就是software的意思,也就是说SDN的control plane就是用软件来实现的,这些软件运行在(相对SDN包交换机的)远端服务器集群上。如上图,control plane由两个部分组成:SDN controller(network operating system)和一组network-control applications。SDN controller负责维护网络状态信息,并为network-control applications提供监控和控制底层网络设备的方法。
- A programmable network。改动运行在SDN control plane上的network-control applications的代码可以改变整个网络的运作逻辑。这些apps就相当于SDN control plane的大脑,通过SDN controller提供的API来控制SDN data plane上的物理网络设备。比如routing network-control application可以决定两hosts之间通信的逻辑链路。
可以看出SDN的各个部分非常独立(unbundling):data plane switches、SDN controllers和network-control application这几个部分都是相互独立的,因此每个部分都可以由不同的机构提供不同的服务。
那么flow tables究竟是如何被计算的?当SDN switches状态变化时这些tables是如何被更新的?不同SDN switches各自的flow tables是如何同步的?
5.5.1 The SDN Control Plane: SDN Controller and SDN Network-control Applications
回顾上一小节,SDN control plane由SDN controller和SDN network-control applications组成。
controller的功能可以被分为三层,我们以自底向上的方式来看:
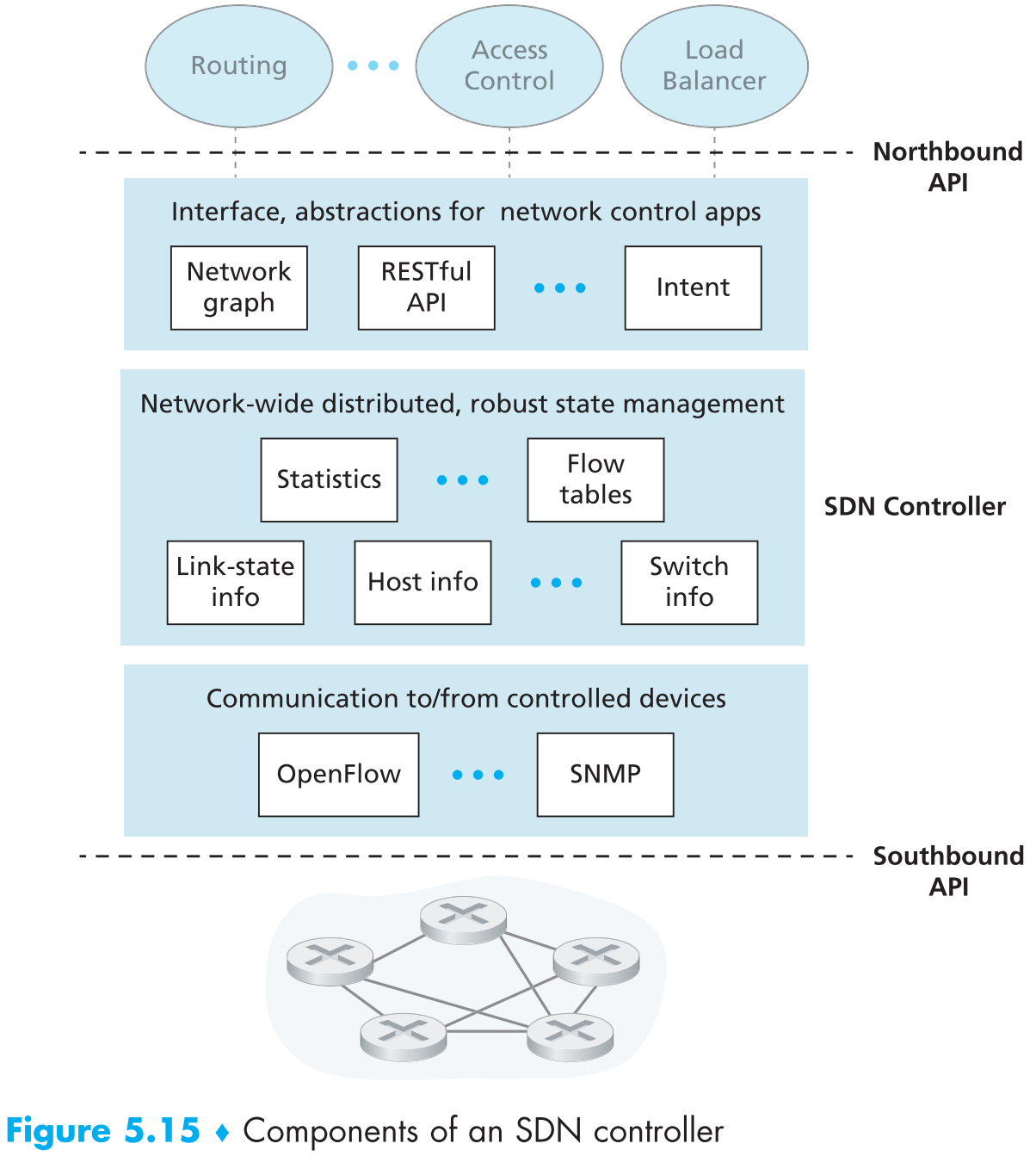
A communication layer: communicating between the SDN controller and controlled network devices。SDN controller和remote SDN devices之间存在数据交换,这个交换的过程肯定要使用某种通信协议,这样SDN controller才能够控制远端的SDN devices,且SDN devices才能够将自身状态的情况告知给远端的SDN controller。如上图中OpenFlow就属于这种通信协议,controller和SDN devices之间通过controller的 “southbound” 接口交换数据。
A network-wide state-management layer。SDN control plane做出控制行为(比如给所有SDN devices分发计算好的flow tables;负载均衡;访问控制)的前提是SDN controller能够 实时地 获取到网络中所有hosts、links、swiches以及SDN-controlled devices的状态信息。
The interface to the network-control application layer。controller通过 “northbound” 提供网络接口给network-control applications调用。network-control applications可以通过northbound接口读写state-management layer中的网络状态信息以及flow tables,network-control apps也可以向controller申请在网络状态发生变化时通知它们一下。
SDN controller在逻辑上可以被看作是“中心化”的,但实际上它是由分布式的服务器集群组成。
5.5.2 OpenFlow Protocol
OpenFlow协议运行在SDN controller和SDN controlled devices之间,基于TCP,端口号为6653。
controller发往SDN devices的信息包括:
- Configuration。读写SDN devices的配置参数
- Modify-State。添加、删除或修改SDN devices的flow table中某些字段,也可以设置SDN devices的接口属性。
- Read-State。从SDN devices的flow table和接口处收集数据统计信息。
- Send-Packet。让某SDN device从一个特定接口发送一个特定的数据包。
SDN devices发往controller的信息包括:
- Flow-Removed。告知controller自己flow table中某一条目已经被删除了。
- Port-status。告知controller自己某个接口状态发生改变。
- Packet-in。在上一章data-plane中我们提到过,如果一个packet到达SDN switch后没有match到任何flow table条目,这个包就会被发送到controller做进一步处理。其实即使packet成功match了也可能会被发送到controller,来执行match后的功能。Packet-in的作用就是将这个packet发送给controller。
5.5.3 Data and Control Plane Interaction: An Example
需要先说明的是,SDN网络与普通网络有很大的区别(以采用Dijkstra算法计算路由为例):
- 普通网络中每个router上都要运行Dijkstra算法,且每个router上都要维护当前区域所有的链路状态信息。而在SDN网络中,Dijkstra算法作为一个独立的network-control app在远端服务器集群中运行
- 普通网络中链路信息以泛洪的方式在路由器之间传播,而SDN网络中所有SDN switches都会把自己当前获取到的链路信息直接发送给controller。
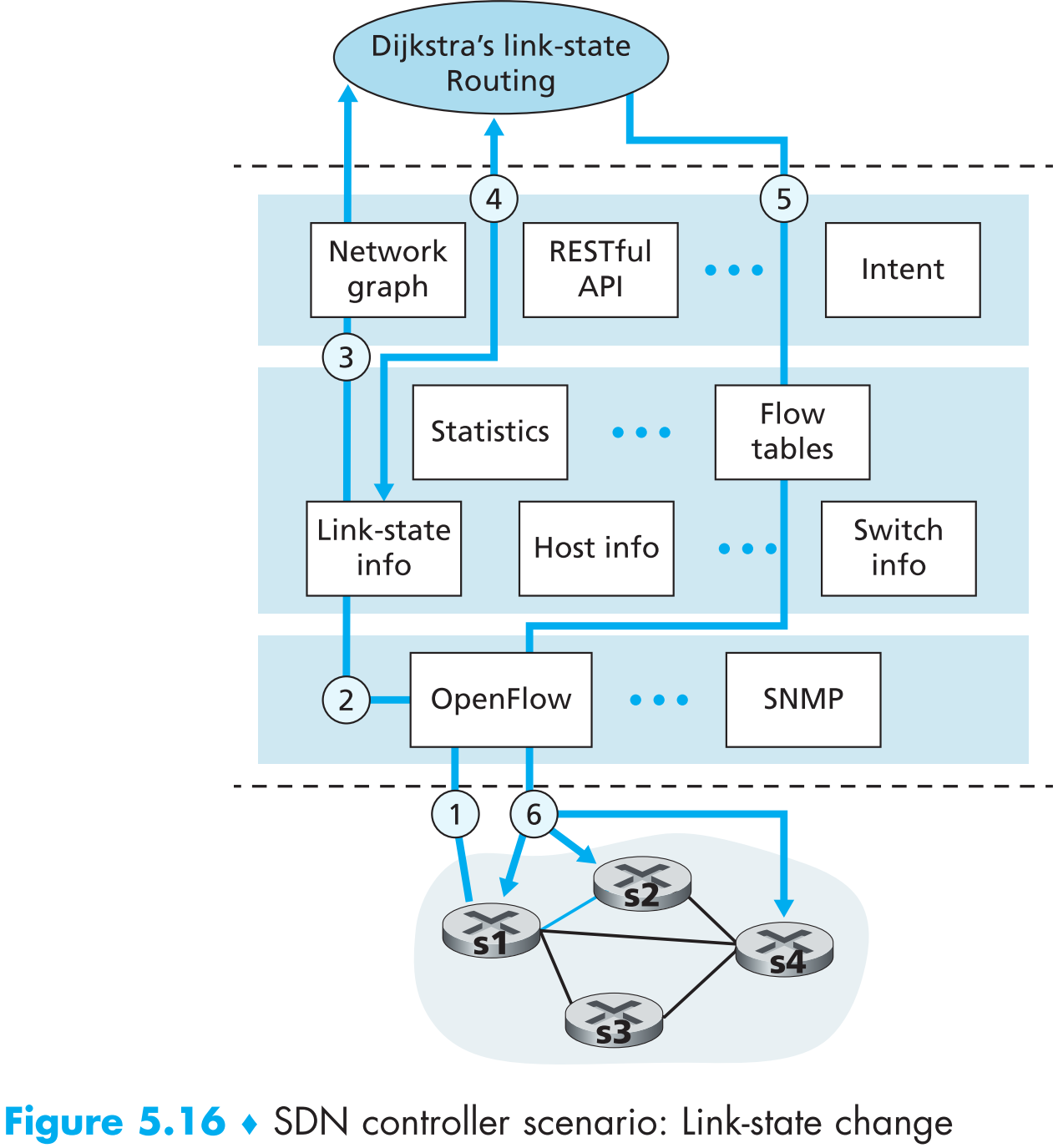
以上图为例。假设s1和s2之间的链路状态现在变为down,那么接下来:
- s1察觉到自己与s2之间的链路状态变为down,那么s1会发送OpenFlow协议中的port-status message来将该事件告诉controller。
- SDN controller收到该message后,更新它的链路状态数据库(link-state datavase)
- 假定运行Dijkstra算法的network-control app之前已经向controller申请好了如果链路状态发生变化会通知它。因此Dijkstra app收到链路状态变化的通知。
- 接着Dijkstra app与link-state manager以及state-management layer的其他部件交互来获取刚才链路状态变化的具体信息(即s1和s2之间的链路状态变为down),随后计算新的最短路径。
- Dijkstra app接着会与flow table manager交互,将刚计算出的新的最短路径发送给它。然后flow table manager会通过OpenFlow协议将所有此次链路状态变化影响到的SDN switches的flow table条目更新:s1现在到s2要经过s4,s2现在到s1要经过s4,s4现在要中转s1与s2互相通信的流量。
从上述的过程中可以看出,SDN网络的可扩展性非常强,而且非常方便,因为只要修改或者更换network-control application就可以改变网络运行逻辑。反过来,如果在传统网络中想要把一个AS的OSPF更换为RIP协议,那必须一台一台的手动更改路由器配置。
5.6 ICMP: The Internet Control Message Protocol
互联网中的hosts和routers通过ICMP来交换【网络层信息】,ICMP最典型的应用就是故障检测(当然除此之外还有其他应用)。比如当我们运行HTTP session时,可能会收到错误报告 “Destination network unreachable”,这条错误报告实际上就是由ICMP发出的:当我们的HTTP数据包传输到某一个路由器时,如果该HTTP数据包的destination address无法match到路由表的任一条目,那么该路由器就会生成ICMP message回复给我们来报告这个错误。
ICMP通常被认为是IP协议的一部分,但实际上在TCP/IP 5层模型中它位于IP协议之上,因为ICMP是作为payload被封装为IP数据包传输的(就像TCP和UDP被封装在IP datagram中传输一样)。当host接收到一个封装了ICMP的IP datagram(上层协议端口号为1)时,它会像处理TCP和UDP一样将其demultiplex。
ICMP报文包含了出错IP datagram的header和其payload的开头8 bytes(这样host收到后就知道是哪个IP datagram出错了)。除此之外,还有一个type和一个code字段,指出了该ICMP报文的类型,如下表所示
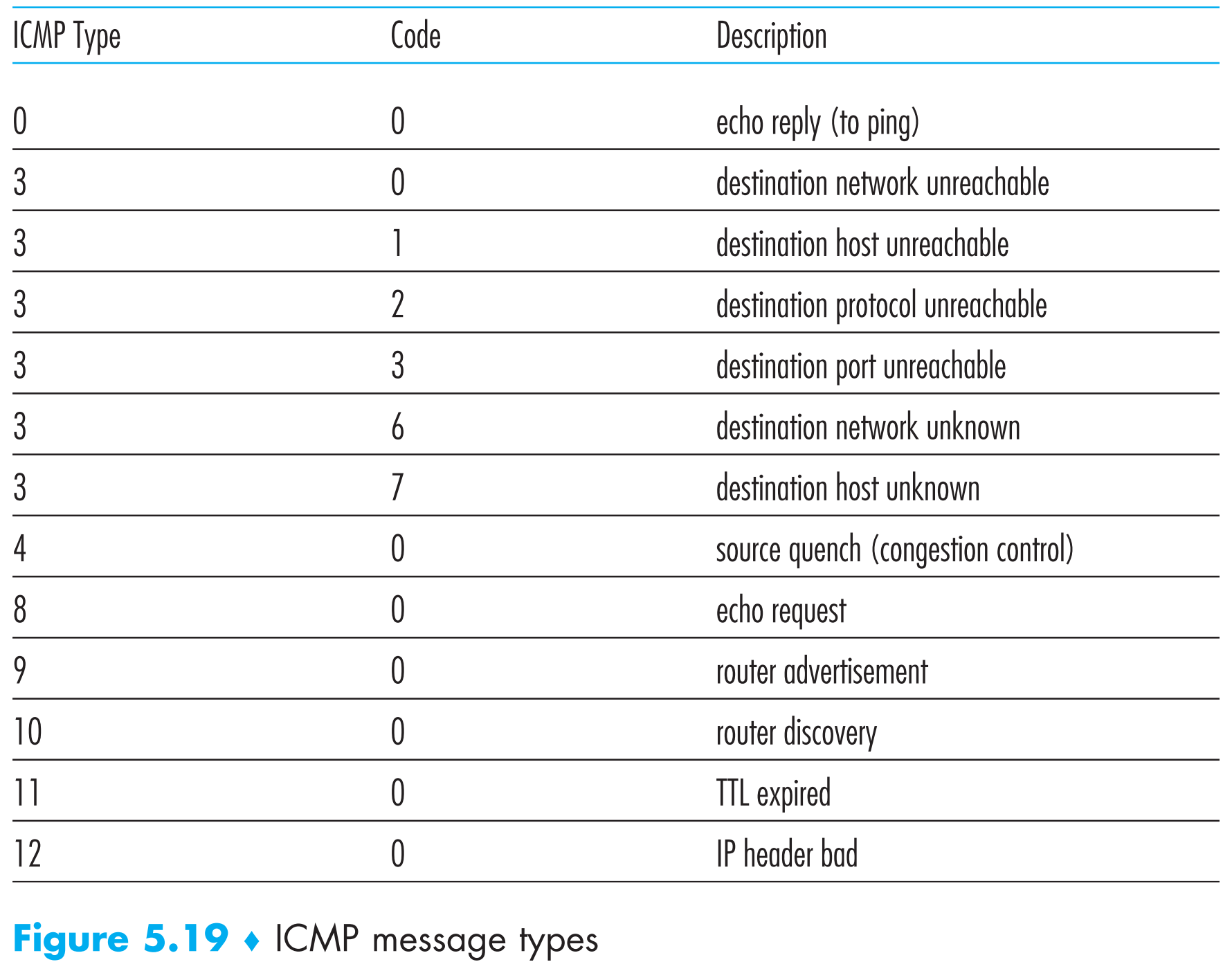
著名的ping命令就是发送type=8,code=0的ICMP报文到指定的host,当host收到这个ICMP报文后,就会回复一个type=0,code=0的ICMP报文给发送端。
著名的traceroute也是通过ICMP实现的。为了确定sender到receiver之间逻辑链路上所有的routers的名字和IP地址,traceroute发送一系列“普通”的IP datagrams,每一个IP datagram都携带了一个端口号错误的UDP segment,且第一个发出的datagram的TTL=1,第二个TTL=2,第三个TTL=3…… 。datagrams发出的同时,sender也会用timer分别为它们启动重传计时。当第n个datagram到达第n个router时,第n个router发现该datagram的TTL已经为0了,那么根据IP协议的规定,这个router会丢弃该datagram并回复一个ICMP(type=11, code=0)给sender,这个ICMP报文中就包含了该router的名字和IP地址。当sender接收到这个ICMP回复报文后,就可以停止对该报文的重传计时,得到自己到第n个router的往返时间(round-trip time),并且将该往返时间以及router的名字和IP地址打印到终端上。
但是traceroute并不能预知sender到receiver会经过多少个routers,那么该何时停止发包呢?因为sender每发出一个“普通”datagram就会令TTL++,因此最后总有一个datagram会到达receiver,不过因为它携带的UDP segment的端口号是错误的,所以receiver会回复给sender一个port unreachable ICMP message(type=3, code=3),sender收到后就会停止发包。
现实中traceroute会在同一个TTL下发送一组三个“普通”datagrams,因此每经过一个router我们会收到三个回复。
为了服务于IPv6,ICMPv6被开发出来,其中加入了一些新的type和code用来适配IPv6比如“Packet Too Big” 。
5.7 Network Management and SNMP
一个网络中的元素太多了,即使是小型机构的网络,也得由成百上千的硬件和软件组成,那么网络管理员如何管理这些元素就成了一个问题。显然SDN网络中可以用network-control application通过SDN controller做到这一点,但是在SDN诞生之前,人们是如何管理的呢?
网络管理的定义:
Network management includes the deployment, integration, and coordination of the hardware, software, and human elements to monitor, test, poll, configure, analyze, evaluate, and control the network and element resources to meet the real-time, operational performance, and Quality of Service requirements at a reasonable cost.
5.7.1 The Network Management Framework
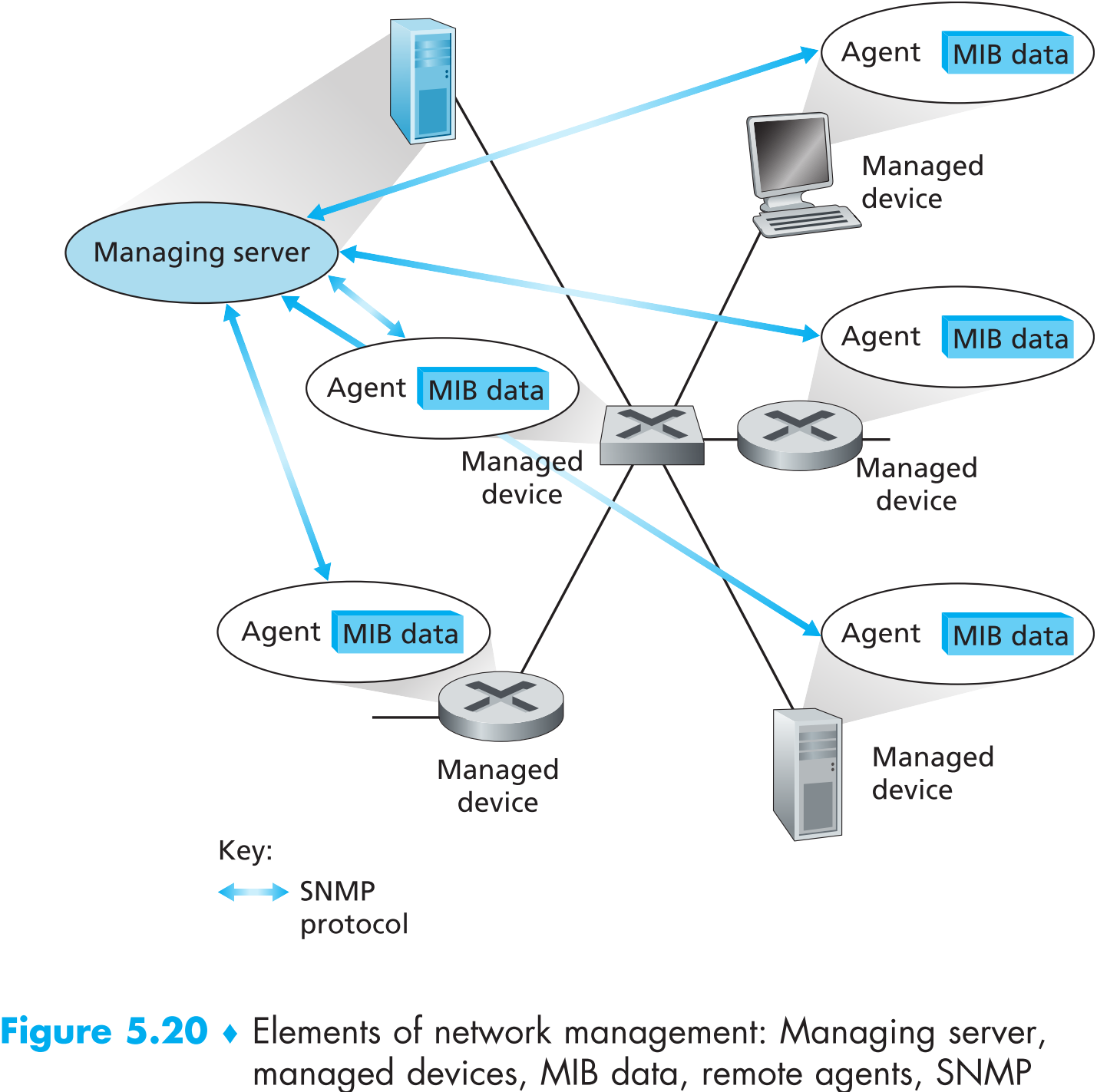
如上图,网络管理的几大部件:
Managing server是一个app,一般运行在network operations center(NOC)内部的网络管理中心,由专门的工程师进行维护管理。managing server是网络管理的核心部件:它可以收集、处理、分析以及可视化网络管理信息。网络管理员就是通过它来与网络设备交互,控制网络行为。
Managed device是被网络管理的网络设备,包括host、router、switch、middlebox、modem、thermometer等一切data plane中联网的设备。一个managed device中包含一个或几个 managed objects,它们可以是硬件——比如host中的network interface card,也可以是软件的参数——比如路由协议的参数为OSPF。
Management Information Base (MIB) 存在于所有managed devices中,里面记录了该device中的managed objects的相关信息。MIB可能仅仅是一个计数器,比如记录某一个router因为检查出bit错误而丢了多少个包;某一个host接收到了多少个UDP segments。也可以记录状态信息,比如某一个设备是否在正常运行。还可以记录协议相关的信息,比如某两个hosts之间的逻辑链路。
MIB objects通过Structure of Management Information(SMI)语言来描述,同一类型的MIB objects一般被归类到一个MIB modules中,MIB module有RFC官方定义的,也有销售商自己定义的。
Network management agent是运行在每一个managed device中的软件,它的作用就是与managing server交互,接收managing server传来的指令并在本设备上执行。
Network management protocol运行在managing server和managed devices之间,使得它们能够互相通信——managing server能够询问managed devices的状态并且间接的通过运行在它内部的network management agent来控制managed device,同时agent也能够在设备发生异常时通知managing server(比如设备断电或者设备的运行状态不正确)。
注意,network management protocol自己并不管理网络,而是为网络管理员提供了一系列网络管理的功能——monitor、test、poll、configure、analyze和control等。
5.7.2 The Simple Network Management Protocol (SNMP)
我们将要介绍的Simple Network Management Protocol v2是一个应用层的协议,它的作用就是为managing server和agent提供信息交换服务。
SNMP的第一个典型应用就是SNMP managing server发送request给SNMP agent,agent收到后在本设备上执行该request,然后回复给server执行的结果情况。第二个典型应用就是agent通过SNMP发送trap message给managing server主动报告本managed device上【引起MIB条目改变】的异常信息(比如链路状态改变)。
协议传递的消息被称为Protocol data unit(PDU),SNMP协议传递的消息被称为SNMP PDU
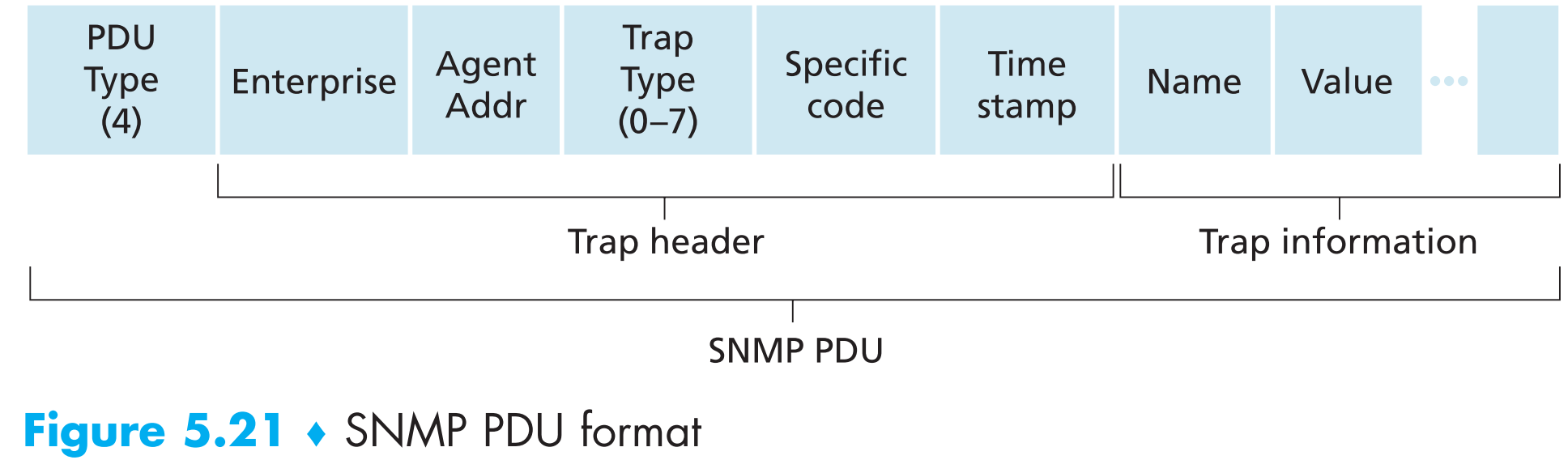
SNMPv2定义了7种消息类型

虽然SNMP PDUs能够通过不同的运输层协议传输,但是一般情况约定使用UDP进行传输,那么UDP协议不可靠的问题该怎么解决呢?SNMP PDU中的request ID字段是managing server用来标识该PDU属于哪一个agent的,对应的agent等会回复给该managing server的response PDU中的request ID与之相同。因此request ID可以被managing server用来检测是否发生丢包(就像TCP中的序列号),长时间没收到agent的回复会被认为是丢包,然后managing server会重传该包。