《计网》Network-Layer-DataPlane
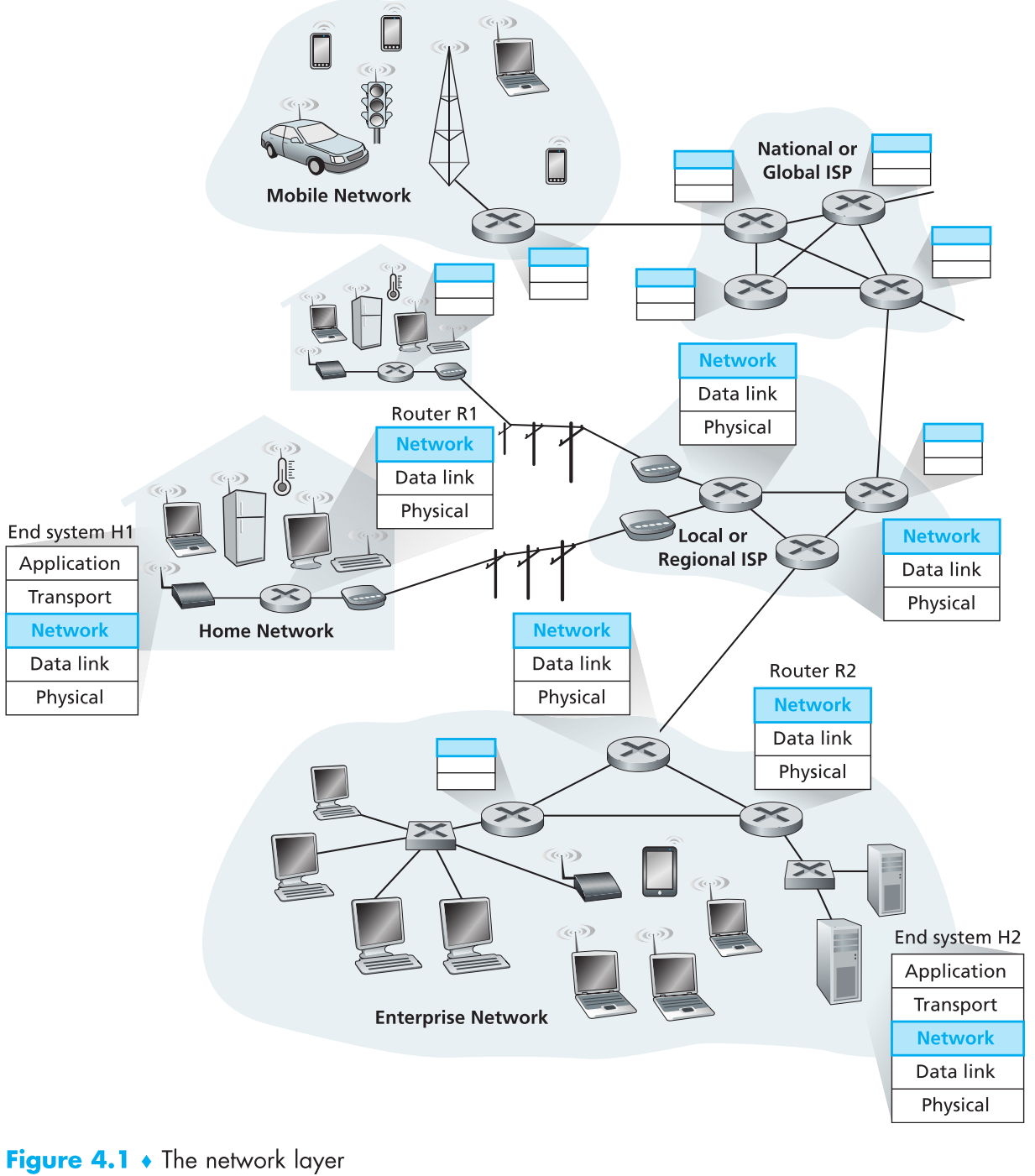
网络层可以被划分为两部分:data plane和control plane。本章我们主要讨论data plane。
4.1 Overview of Network Layer
网络data-plane的主要功能是转发datagram(forwarding);网络control-plane的主要功能是协调数据包在routers之间的转发策略(routing),使得数据包能够在正确的逻辑链路上被不断的路由转发最终抵达目的终端。
注意上图中router最高层就是网络层,因为它只需要执行转发datagrams这个功能,不需要用到上层的功能。
4.1.1 Forwarding and Routing: The Data and Control Planes
网络层的功能似乎很简单:把datagram从sender发送到receiver。
为了完成这个任务,网络层必须具备两个基本功能:
Forwarding。当一个包达到路由器的input link时,该路由器必须能够将它移动到正确的output link,该功能也是data plane的主要作用。
不过现实情况中,packet可能也会被路由器挡在门外(比如当该packet来自一个黑名单终端,或者该packet的目的地禁止被访问),也可能会被复制多份然后被分发到多个output links(广播或者多播)。
Routing。网络层必须确定每个packet的行进路线,用于确定行进路线的算法叫做 routing algorithms ,该功能是control plane的主要作用。
routing和forwarding在某些教材中被用作一个意思,实际上它们有本质上的区别:【Forwarding】是router自身的动作:将packet从input link port移动到正确的output link port。该动作只需要非常短的时间即可完成,一般是用硬件实现的。而【Routing】是整个网络范围的动作:决定一个packet从起点到终点的行进路线。该动作可能需要很长的时间才能完成,一般用软件实现。
以开车从贵阳到上海为例。routing就像是【出发之前,先用高德地图规划行进路线】,forwarding就像是【到了交叉路口,根据高德地图语音提示选择其中一条路前进】。
路由器的一个重要组成部分是 forwarding table(提供端口与IP地址的映射关系), 把一个packet从input link给forward到哪条output link就是由forwarding table决定的:先取出从input link接收到的packet的header中的目标IP,在路由表中一一比对,比对成功后从目标IP对应的output link port发出。
4.1.2 Network Service Model
当一个segment从传输层发送到网络层并被封装成datagram后,它之后被传输的方式、传输的时间等等这些特性就都由网络层提供的服务来决定了。现在来看看网络层【可能】提供哪些服务:
- Guaranteed delivery。保证了datagram一定能够被传输到目的地。
- Guaranteed delivery with bounded delay。不但满足第1点,还能在规定时间内完成传递
- In-order packet deliver。保证datagrams能够按序到达目的地。
- Guaranteed minimal bandwidth。规定一个固定的带宽值,只要发包速率低于这个值就可以确保所有datagrams都能达到目的地。
- Security。在所有包被发出之前对它们进行加密,到达终点之后对它们进行解密,这样就提高了安全性。
我们仅列出5个可能的服务,事实上网络层【可能】能够提供的服务排列组合一下可以形成无数种。
然而现实中,TCP/IP的网络层仅仅提供了一种服务:best-effort service。它:
- 无法保证datagram最终能够到达终点
- 无法保证到达终点的datagrams的顺序是正确的
- 无法保证能够在规定时间内完成数据包传输
- 也无法保证规定一个固定的带宽值,只要发包速率低于这个值就可以确保所有datagrams都能达到目的地。
best-effort service跟没有服务似乎没啥差别,但多年的事实证明这种似乎“不提供服务”的服务搭配上适当的带宽足够应付大多数网络应用了。
4.2 What’s Inside a Router?
一般的路由器构造如下图(注意这里所说的port是物理上的端口而非传输层的软件端口):
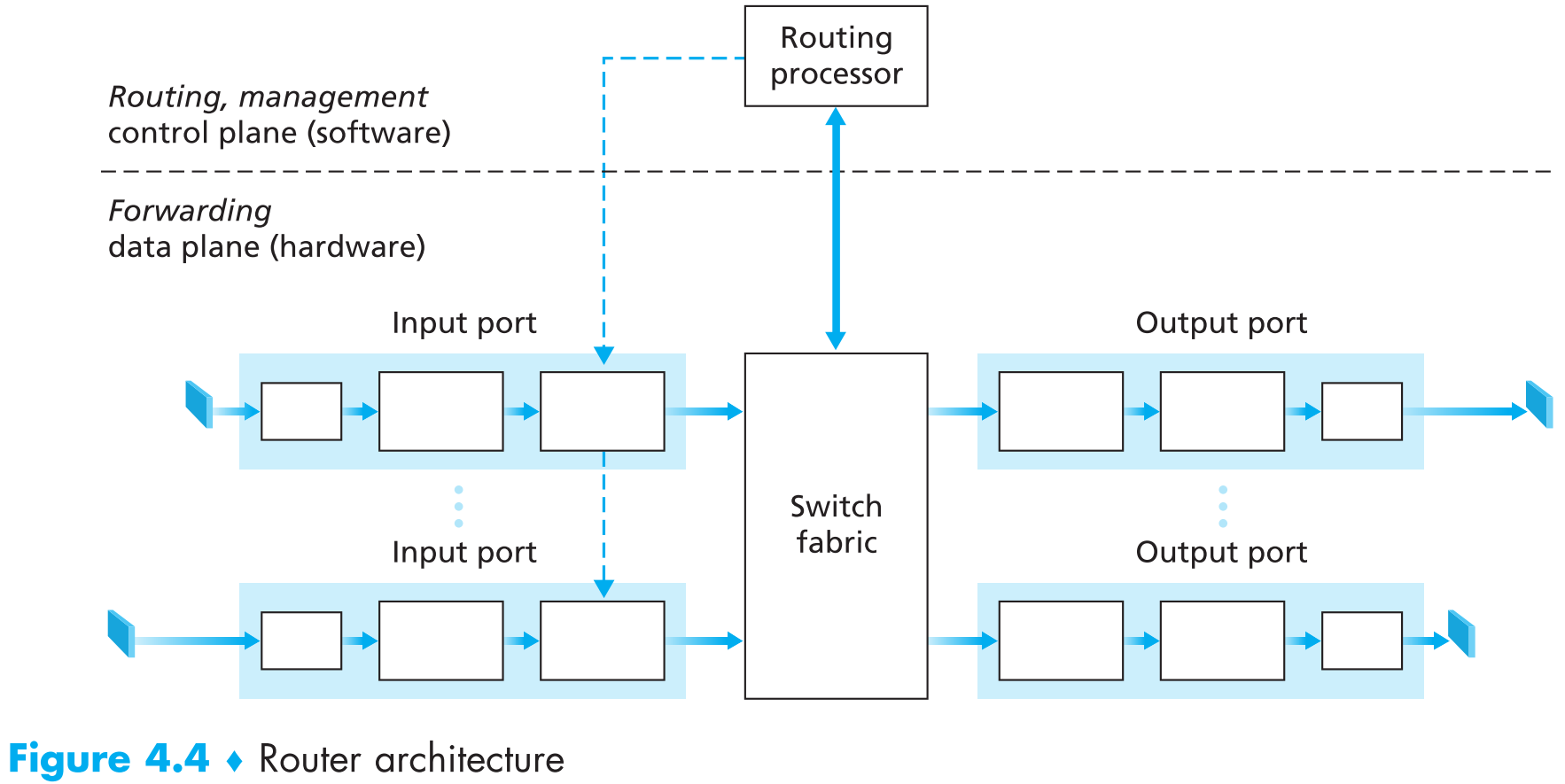
它主要由4个部件组成:
input ports。它实现了几个主要的功能:
a. 实现物理层的功能: 将物理链路与路由器相连(如图中最左侧的input ports,最右侧output ports也一样)
b. 实现链路层的功能: 运行链路层协议,并将数据包封装与解封装(如图中中间的input ports,中间的output ports也一样)
c. 实现网络层的功能: 【查询路由表】 来决定将数据发往哪个output port(如图中最右侧的input ports)
d. 包含路由协议信息的 control packets 会从input port被forward到routing processor
需要说明的是,一个路由器的port可以有几个(如上图为2个ports),甚至也可以有几百个(一般供ISP使用,比如juniper MX2020边缘路由器就支持960个10 Gbps以太网端口)。
Switching fabric。它是完全嵌入在路由器里面的,其主要功能就是将input ports与output ports相连。
Output ports。其功能为存储switching fabric接收到的数据包,然后将它们传输到出口链路上。
Routing processor。其主要提供control-plane的功能,以通用的路由器为例,routing processor会运行路由器协议、维护路由表以及链路状态信息。此外它还提供一些网络管理功能,之后我们会学到。
注意如果物理链路支持双向传输数据,那么output ports和input ports会被捆绑在一起,可以理解为output port也是input port,input port也是output port。
几乎所有路由器的input ports,output ports以及switching fabric都是用硬件实现的。
4.2.1 Input Port Processing and Destination-Based Forwarding
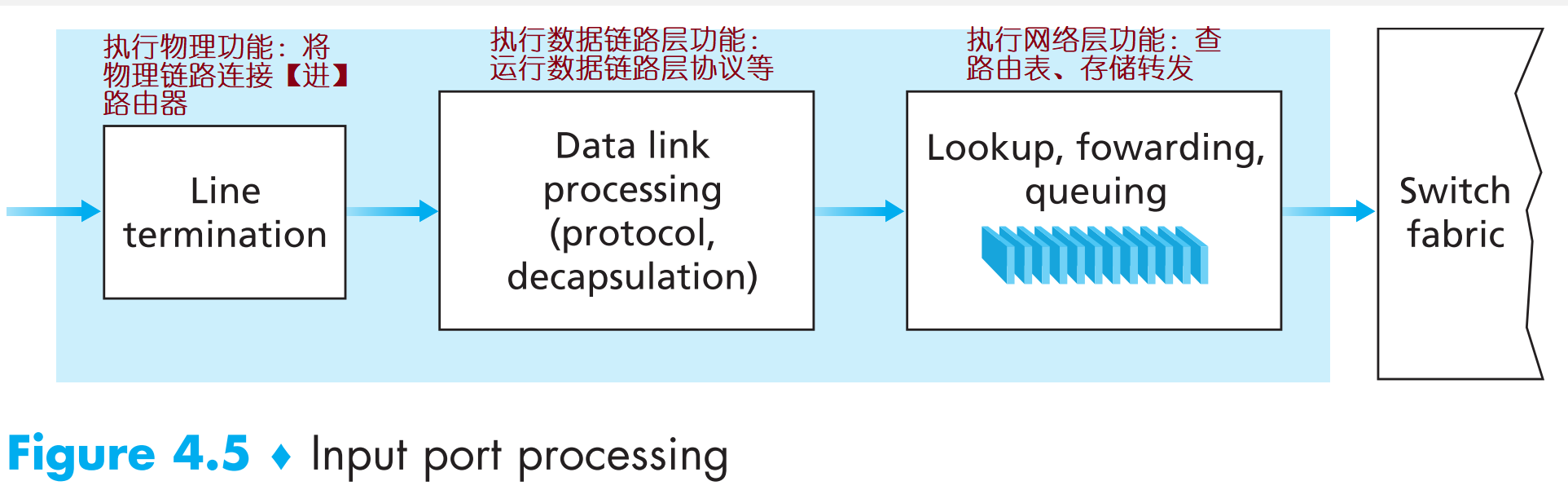
现在先假定一种最简单的场景,假设数据包转发的方向仅由目的IP地址决定(现实中一般还由header中的其他字段决定),IP地址为32-bit。且假定一共有4条链路(0~3号)连接到路由器上,且内部转发的规则如下:

那么我们的路由表条目应该存储为(必须存储地址段与端口的映射,因为如果一个IP对应一个条目的话路由器的存储成本太高):

比如来了一个packet的目的地址为11001000 00010111 00010110 10100001,它属于11001000 00010111 00010这个网段,因此会被转发到0号端口。
但是此处存在一个问题,如果packet的目的地地址为11001000 00010111 00011000 10101010,那么它的前24个bits匹配了路由表的第二个条目,与此同时,它的前21个bits匹配了路由表的第三个条目,那么应该把它转发到哪个端口呢?当一个目的地址匹配了路由表中的多个条目时,路由会采用 longest prefix matching rule——选择前缀匹配最长的条目,因此本例中路由器会将该packet匹配第2个条目,将其转发到1号端口。后面将会解释使用这种匹配方案的原因。
将IP地址匹配路由表的过程在逻辑上很简单:在路由表项中寻找最长前缀匹配。但是当链路带宽非常大时,这个寻找匹配过程的速度必须【非常快】,这就要求查询路由表的功能必须用硬件实现,且要使用特殊的数据结构(不可能用线性查找,甚至连二分查找的时间复杂度都无法容忍)。不光要优化路由查找功能,还要优化路由器的内存硬件设计以降低访问内存的时间(比如使用特殊的内存Content Addressable Memories——TCAMs)。
当路由表查询完毕后,packet将要被转发到的output port也就被决定了,但是它现在无法直接被发送到对应的output port,因为该过程必须由switching fabric完成,因此要先被发送到switching fabric(注意如果有其他input port进来的packet正在使用switching fabric的话,后来的packet就会在input port排队等待进入)。
最后说一下,类似于查表(match),然后将packet发送到switching fabric再转发到正确的端口(action)这整套过程是网络设备中非常常见的一套动作逻辑,叫做 match plus action abstraction 。不仅路由器使用这一套逻辑,交换机、防火墙、NAT等都采用这一套逻辑。
4.2.2 Switching
switching fabric是路由器的核心部件,正是因为它,一个packet才能从input port被移动到对应的output port。switching这个过程有几种实现方式:
Switching via memory 。
最早期的router其实就是普通的电脑,switching操作通过一个特殊的routing processor实现,这时input和output ports对于操作系统来说就是I/O设备。
新来的packet到达input port后先通过中断发送信号给routing processor,接着这个packet的数据就被从input port复制到内存中,routing processor接着就将packet header中的目标地址字段取出,查询路由表,确定最终要转发到的output port,然后将packet复制到output port的buffer中等待发送。
如果内存的带宽为每秒可存/取最多B个packets,那么该方式一台电脑总的转发带宽必定小于B/2(因为即使output port不一样,同一时间也只能转发一个packet,因为shared system bus上同一时间只能完成一个内存操作指令)。
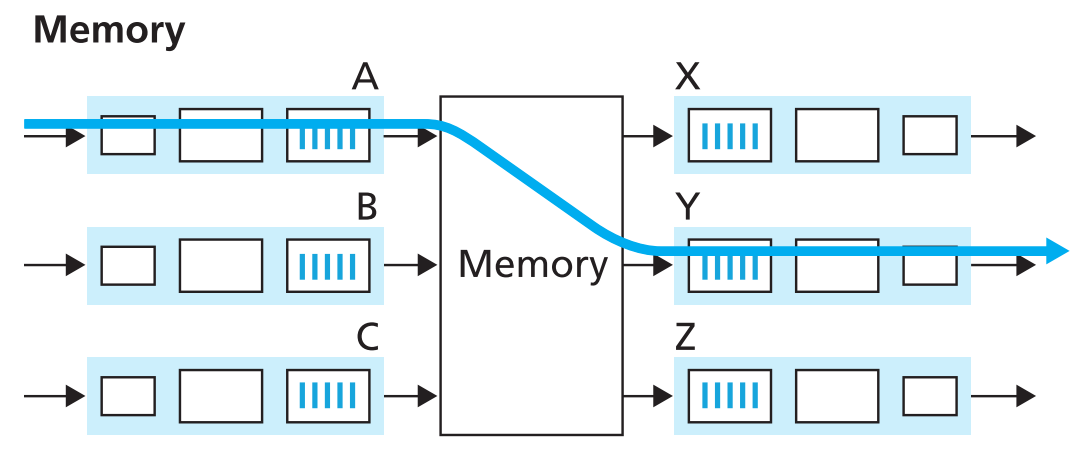
注意CPU(central processing unit)概念上是processor的子集。
Switching via a bus 。
该方案的实现方式为:input port将packet直接通过shared bus传输到output port,中间没有routing processor的干预。这种方案的switching速度取决于shared bus的速度,且同一时间bus上只能处理一个packet,有些对网速要求不高的情况会采用这种方案。
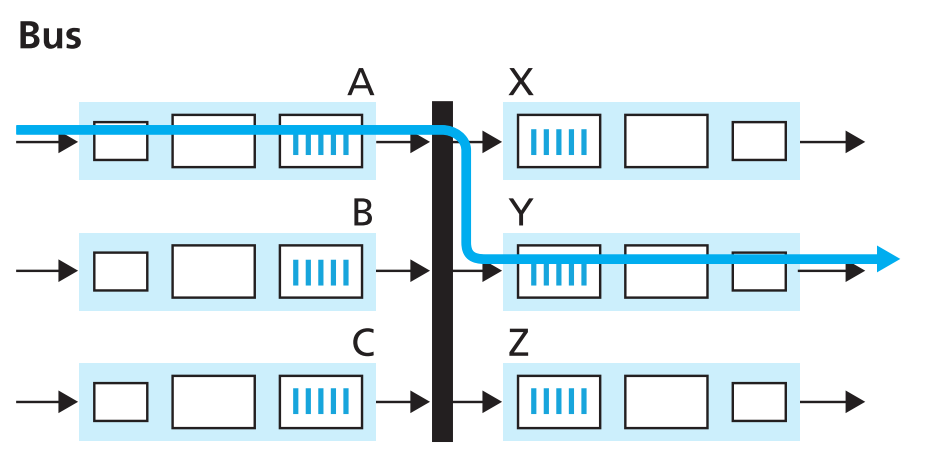
Cisco 6500 router内部就是通过一个32-Gbps-backplane bus来进行switching的。
Switching via an interconnection network
为了突破方案1和2中只能通过一条shared bus进行switching的限制,可以采用一种相对复杂内连接网络。比如crossbar switch就是由2N条buses连接N个input ports和N个output ports组成的内连接网络,如图4.6.
垂直的buses会和水平的buses交叉,这个交叉点可以由switch fabric controller来控制闭合或断开。当从port A接收到一个packet并准备发往port Y时,switch controller会闭合总线A和Y的交叉点,接着A将packet通过唯一一条bus通路发送到port Y。与此同时,从port B收到的packet也能往port X发送。因为它们用的是不同的总线,这样就实现了并行的switching,效率大大提高。
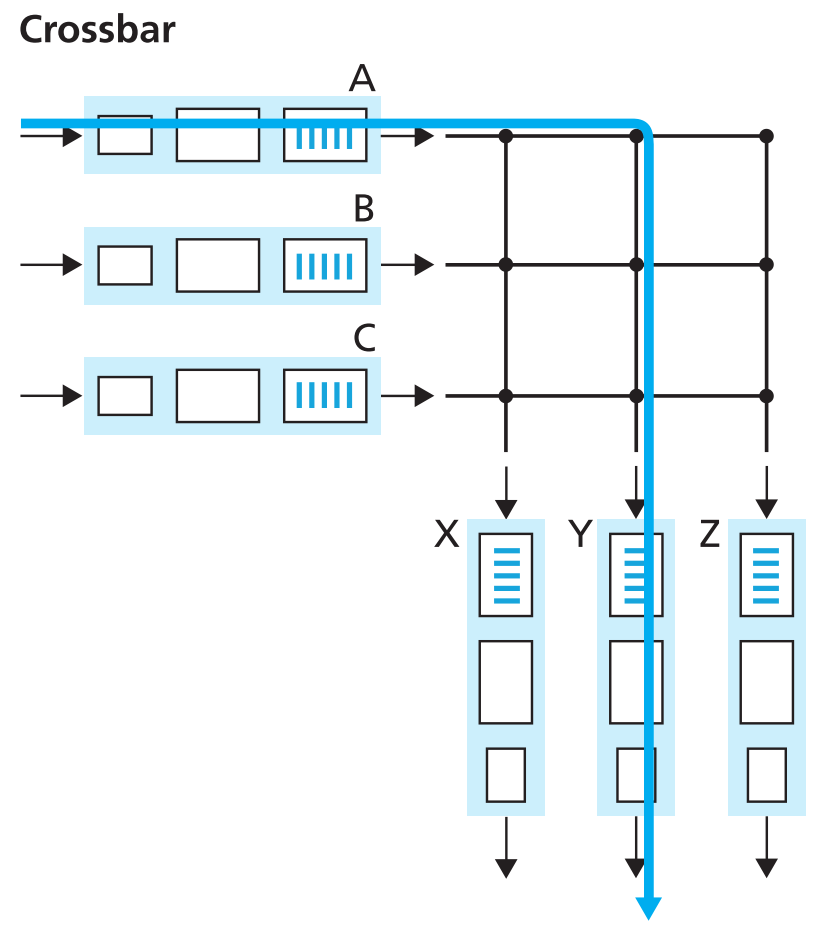
Cisco 12000系列都使用crossbar switching network。
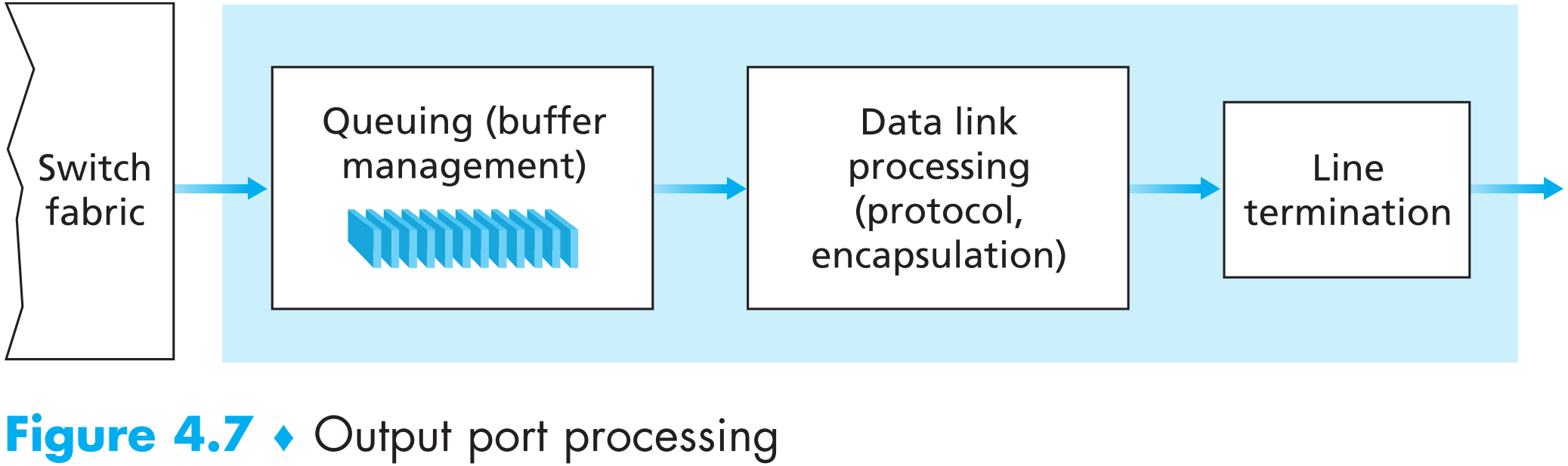
4.2.3 Output Port Processing
Output port的主要工作就是把【switching fabric发送到自己内存中的packets】发送到【自己对应连接的物理出口link上】。整个过程包括packet selecting,packet de-queueing以及执行必要的数据链路层以及物理层的功能。
4.2.4 Where Does Queuing Occur?
假设路由器上共有N个input ports和N个output ports,每一条input和output port线路的带宽都为$R_{line}$个packet每秒。再假定所有packets大小相等,路由器接收和发出packet的速率相等。最后定义switching fabric的转发速率为$R_{switch}$ (即一个packet从input port移动到对应output port需要的时间)。
这种情况下,若$R_{switch} = N \cdot R_{line}$(即switching的速度等于路由器N个input ports同时接收一个packet的速度,这意味着路由器N个input ports全打开的情况下可以无延迟地 不断地 同时把所有N个packets从input ports全部转移到对应的output ports),那么packet在input ports上排队所需要的时间几乎就可以忽略不记了,因为即使在最差情况——所有N个input ports都在接收packets且它们都发往同一个output port,路由器也能够在下N个packets到来之前处理完当前的N个packets。
4.2.4.1 Input Queueing
但是如果switching fabric的速度没有快到能够在一瞬间处理N个packets呢?这种情况下在input ports中就也会产生packet queuing了。
现在我们以crossbar switching fabric结构为例来讨论这种情况带来的问题,假定:
- 所有与路由器相连的链路带宽相同
- input port中排队的packets遵循FCFS(First come First served)的原则
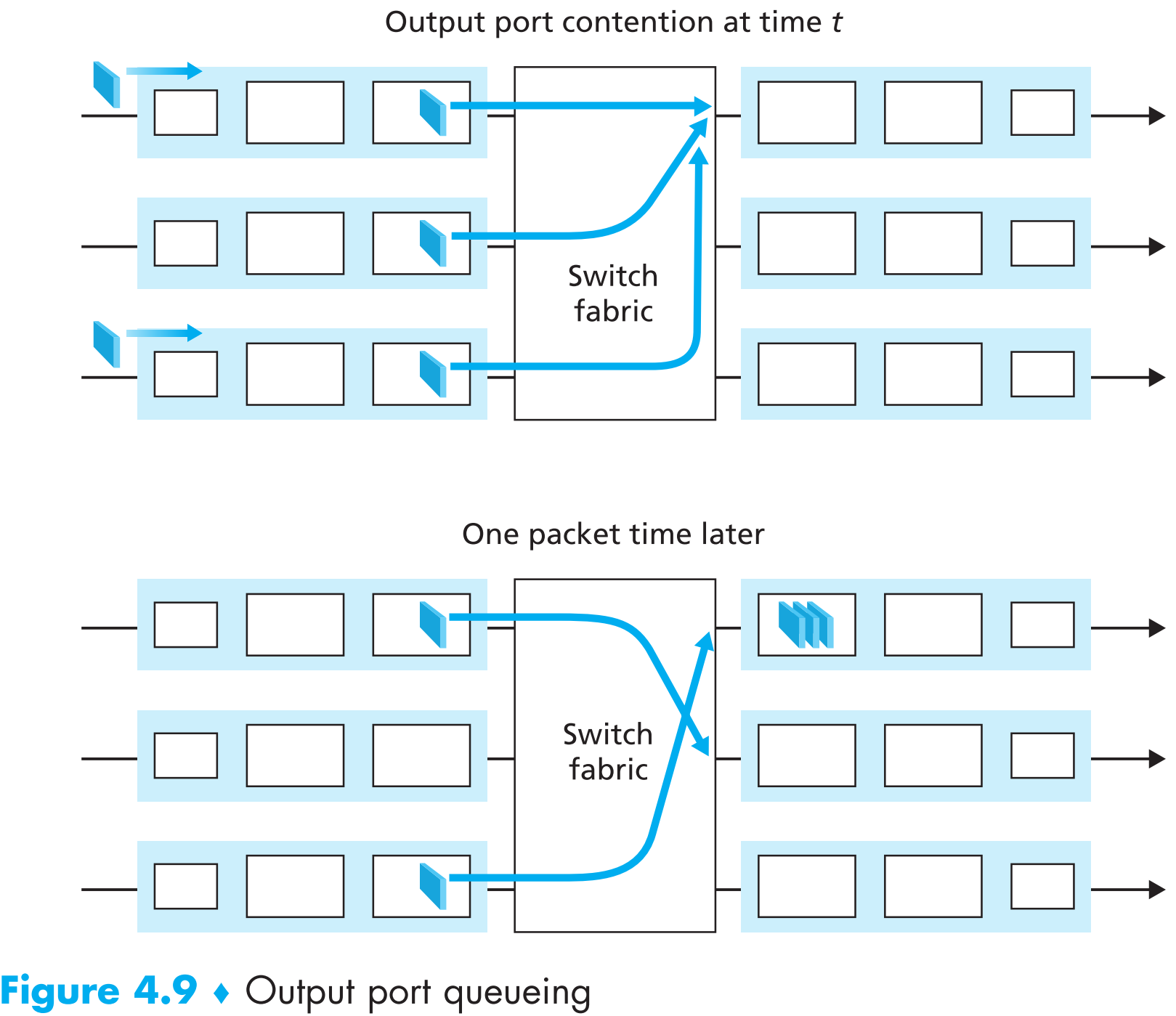
- 只要output port不一样,从不同input ports进来的packets就可以被并行的处理。不过如果output相同,那么一次就只能处理一个input port的packet,其他input ports的packets被阻塞并等待switching fabric将当前packet处理完毕(因为switching fabric同一时间只能处理一个发往特定output port的packet),如下图:
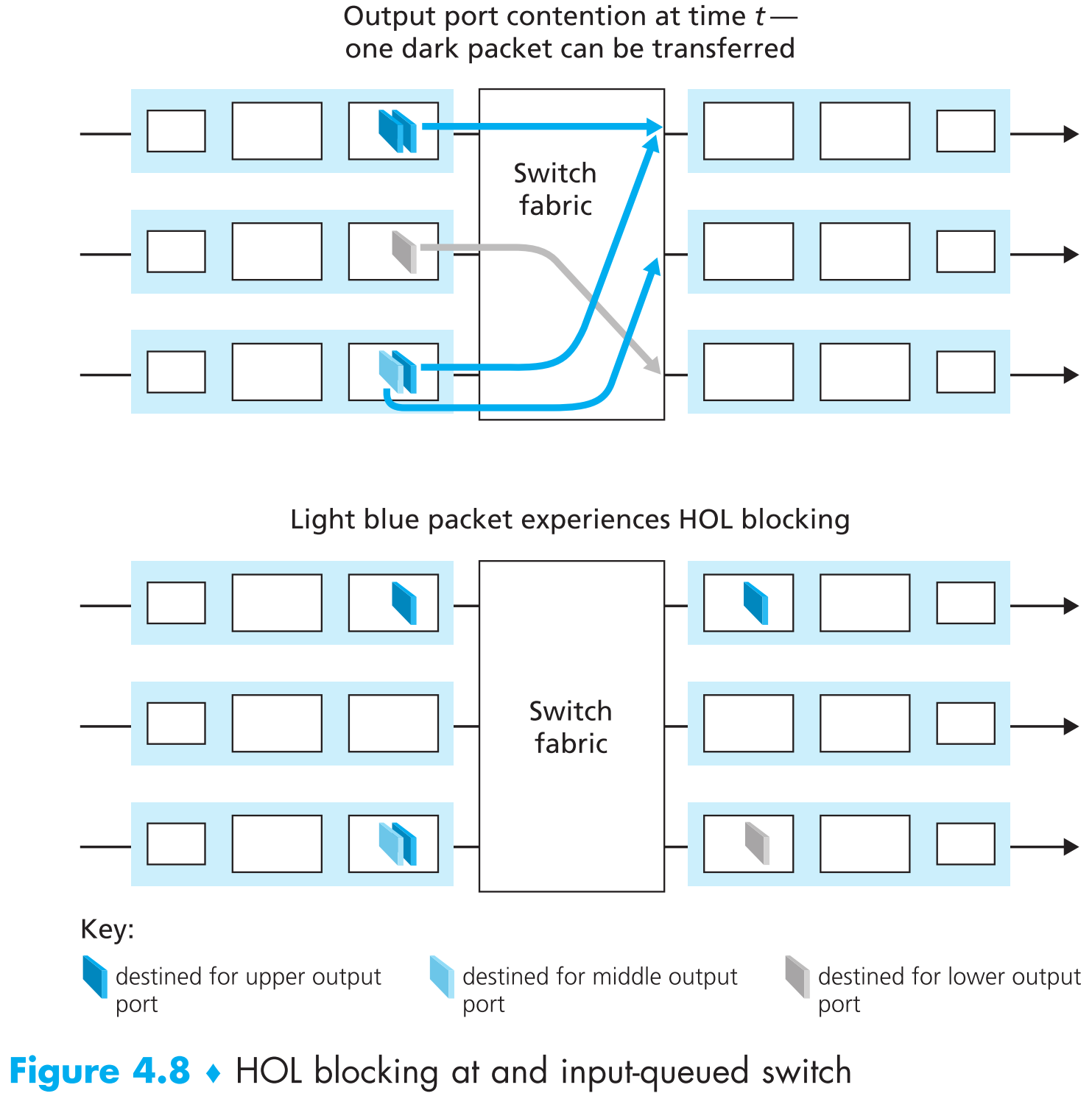
图中示例是input-queued型交换机会出现典型的 head-of-the-line(HOL) blocking 现象:第三道上input ports中最右侧的包和第一道input ports中的包的output port相同,假设第一道的包优先传输,那么第三道上的所有包必须被阻塞等待——即使第三道input ports中最左侧那个包的output port不与其他任何包冲突,且第二道处于闲置状态。
HOL blocking的直接结果就是可能因为某一条input queue的拥挤(其他input queue可能还有很多空闲空间)而产生路由器整体上的丢包——即使包到达路由器的速率可能只有链路带宽的50%。
HOL blocking具体的解决方法感兴趣的同学可以参照McKeown 1997年的论文。
4.2.4.2 Output Queueing
现在我们来考虑下,路由器的output ports中会不会产生排队现象呢?
假定$ R_{switch}=N\cdot R_{line} $ ,且所有packets都被发往同一个output port。这种情况下,如果路由器的N个input ports全部打开,那么一次switching就会有N个packets被传输到output port,又因为output port在一个packet transmission time内只能传输一个packet,因此,其余的N-1个packets必须要排队。紧接着,在这一个packet transmission time内switching fabric可能又运来了N个packets….,随着时间积累packets在output port中排起了长队,最后把buffer塞满,路由器开始丢包。
从这个例子中可以看到,即使switching fabric的处理速度非常快,但如果很多个packets的output port相同的话,output port buffer很快会被塞满,然后路由器还是会产生丢包(即使路由器其他output port的空间还很充裕)。
无论因为什么原因,当路由器中的buffer满了后又收到了新的packet,就要开始做出选择:1. 丢弃新来的packet(称为 drop-tail),2. 把一个或多个正在排队的packets丢弃,然后接收新来的packet。但其实在某些情况下,在buffer【快要满】的时候就提前“故意”丢个包(或者将datagram的ECN bit置1)来提示sender网络拥塞是一个比较好的选择,这一类先发制人的算法被统称为 active queue management(AQM) algorithms,其中最常被使用的是 Random Early Detection(RED) algorithm 。
下面看看output port queuing的过程:
在t时,每一个input ports都接收到了一个packet,且它们对应的output port都为同一个(最上面的)。这里假定packet从input port接收的速度等于从output port发出的速度,且switching fabric的处理速度为三倍的packet从input port接收的速度。在t+1时,所有三个packets都被switching处理完毕并放到了output port中排队等待发送,在t+2时,排队的三个packets之一(由packet scheduler根据某种算法选择,不一定是队头)在链路上被发送完毕了,在本例中这时路由器又接收到两个新来的packets,其中一个的目标output port为最上面的,这时最上面的output port的 packet scheduler 又会从正在排队的packets中选择一个进行传输(packet scheduler下一节会详细介绍)。
因为路由器的buffer必须要能够承受住一定程度的网络流量波动,所以现在我们必须考虑一个问题:【buffer设置为多大比较合适?】。从网络运行这么多年的实际数据上来看,buffer的大小B应该设置为链路的平均RTT乘以链路带宽C:
$$
B = \text{average RTT}\times C
$$
比如平均RTT=250msec,链路带宽为10 Gbps时,buffer的大小应该为$ 250 msec\cdot 10Gbps=2.5Gbits $。
4.2.5 Packet Scheduling
现在我们来看看从在output port中排队的packets中挑选一个发出到output link的几种挑选策略。
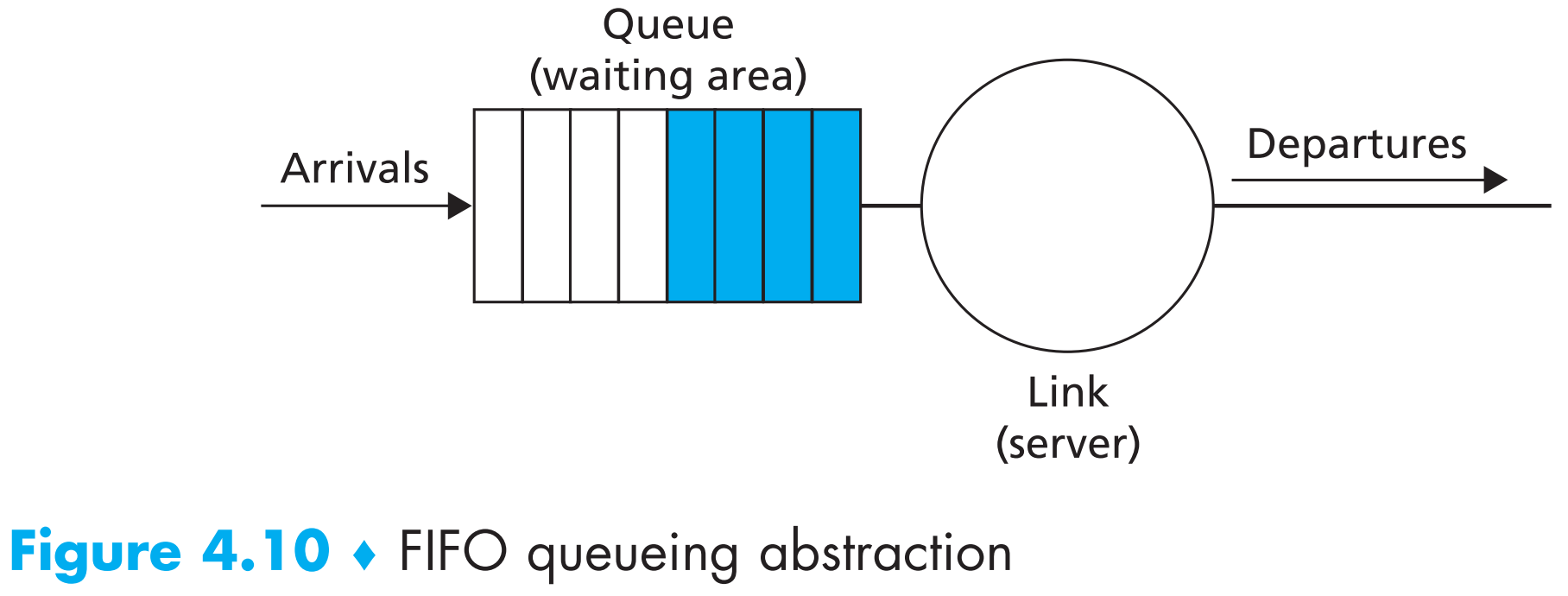
4.2.5.1 First-in-First-Out(FIFO)
回顾一下,当output port的buffer满了之后,如果这时有新的packet到来,那么port就要决定是【丢掉新来的】还是【从buffer中丢弃一些旧的packets然后接收新的packet】。接下来的讨论中我们将默认output port的buffer无限大——即不会发生丢包。
先来先服务的策略就是哪个包先进到output port中,哪个包就会被优先选中并从output link发出
下面再看看一个实际的例子:
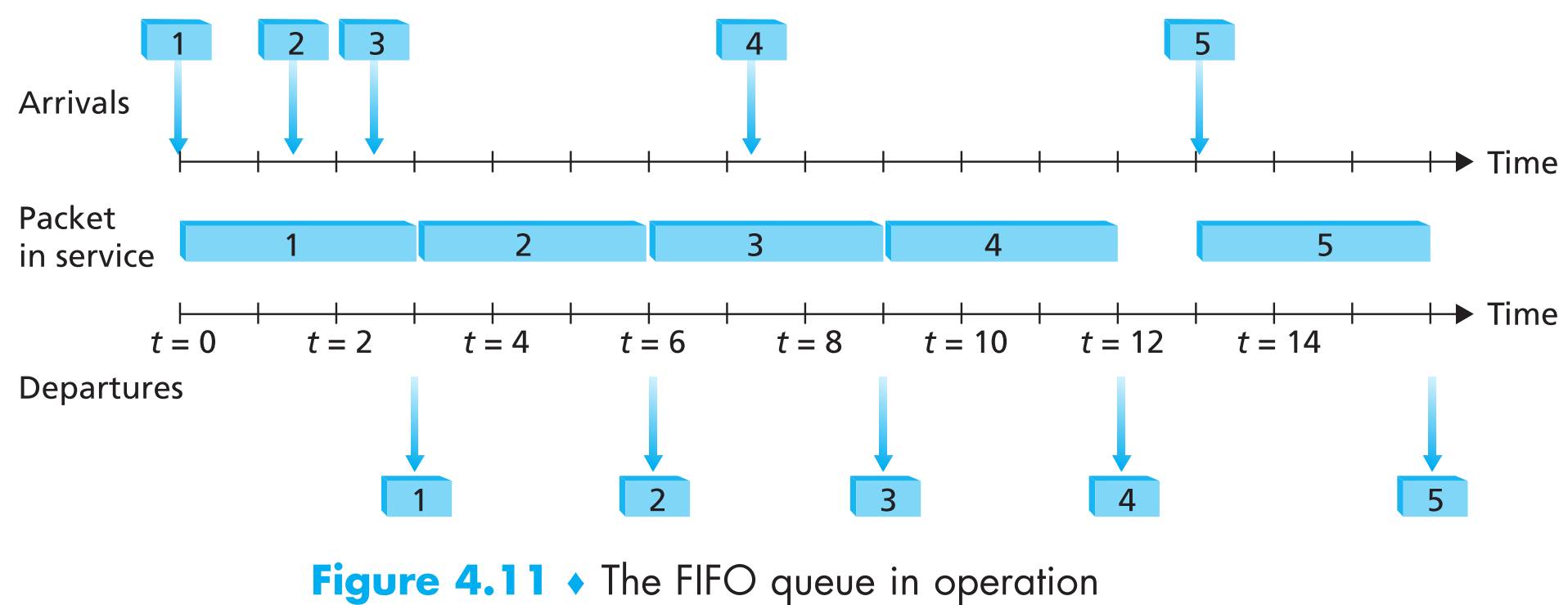
最上方的标号1,2…的方块代表到达output port的包,标号代表了它们到达的顺序;最下方标号1,2…的方块代表从output port发出并在output link上传输完毕的包,同样标号代表它们离开的顺序。中间的长方块代表某一个包在output link上传输完成所需要的时间。本例中我们假设每一个packet等长且都可以在output link上花费3t传输完毕。
采用FIFO方案,可以看到包离开的顺序与它们到达output port的顺序相同。需要注意的是在4号packet离开后,在5号packet到来之前链路会处于空闲状态。
4.2.5.2 Priority Queuing
本方案会将output port的buffer中所有packets放在不同优先级的队列(非抢占)中,如下图
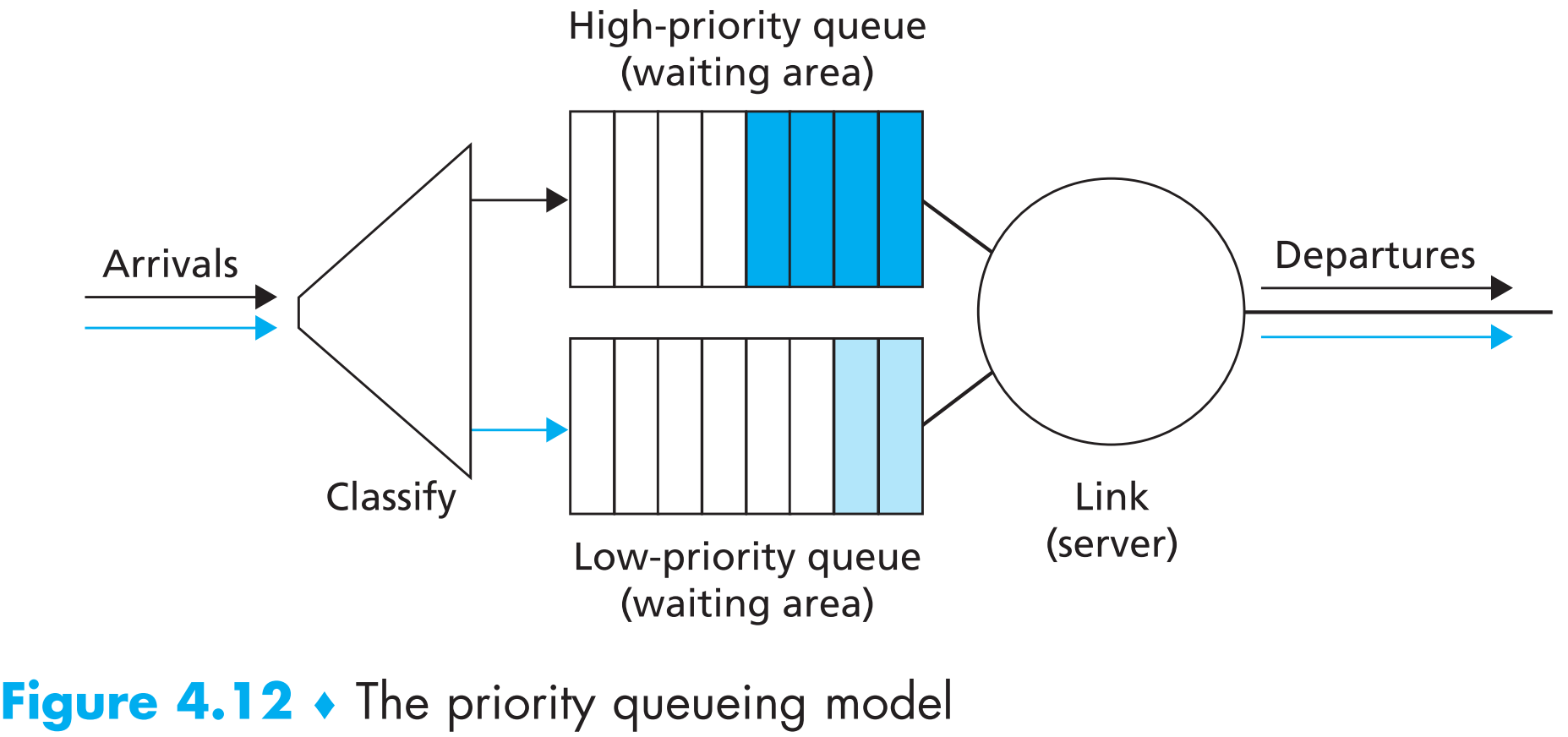
output port每次都会去优先级最高的非空queue里面选择一个packet(通常按照FIFO的方式)发出。
下面来看一个实际采用这种方案的例子(假设只有两类优先级队列):
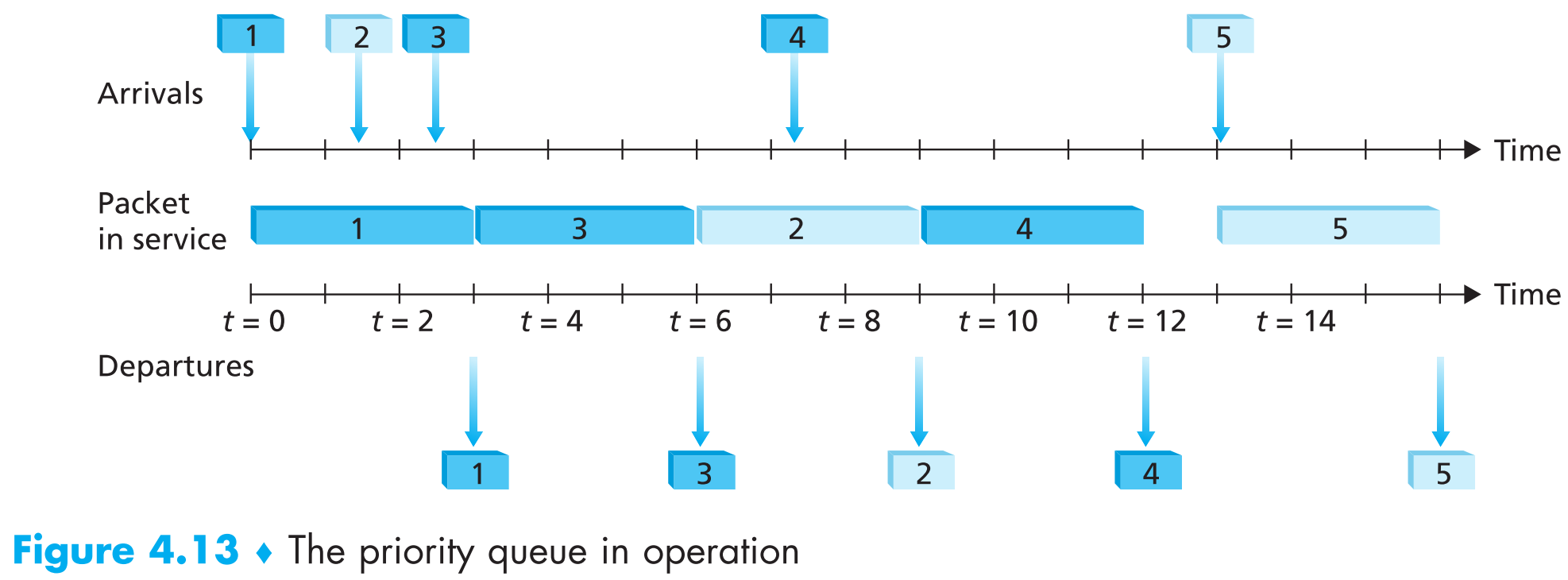
1、3和4号packets属于高优先级,2、5号属于低优先级。当1号packet到达output port时发现链路处于空闲状态,就会直接开始传输,在1号传输的过程中,2、3号到达并且被放到对应的优先级队列中等待。当1号传输完成后,优先级较高的3号会被选择传输。3号传输完毕后链路空闲,因此轮到2号传输。因为我们使用的优先级队列是非抢占式的,因此任何一个包在传输过程中是不会被打断的(即使在传输低优先级packet的过程中新来了一个高优先级的packet),所以即使2号传输时4号到达了,4号也必须等待2号传完自己才能传输。
4.2.5.3 Round Robin and Weighted Fair Queuing (WFQ)
该方案中packets同样会被分组(但不是按照优先级,而是按数量均分),每次从不同的组中选择一个packet发送。
一般在路由器中使用的广义round-robin-queuing算法叫做 weighted fair queuing(WFQ) discipline ,如下图
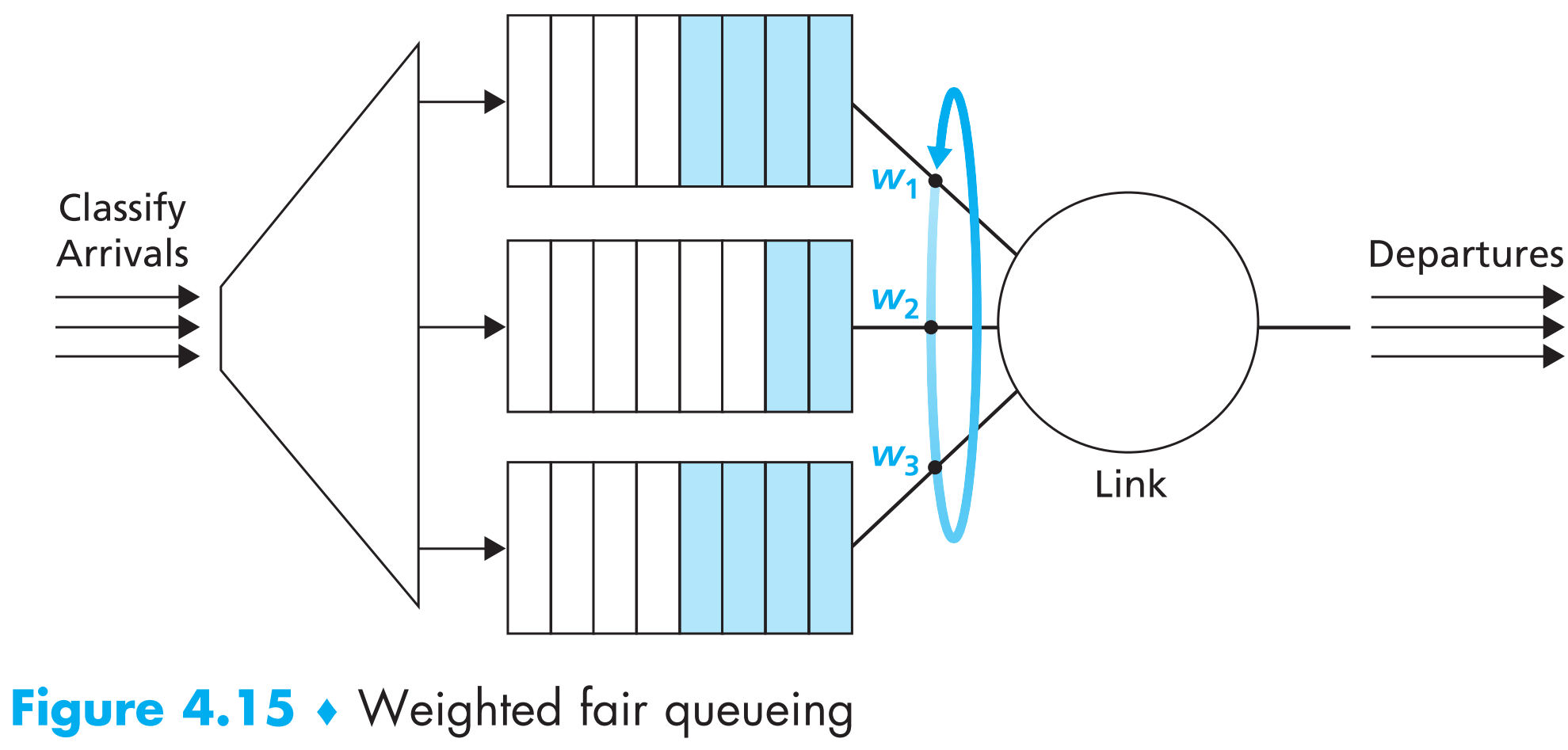
关于WFQ更详细的知识读者感兴趣可自行搜索学习。
4.3 The Internet Protocol (IP): IPv4, Addressing, IPv6, and More
4.3.1 IPv4 Datagram Format
网络层的packet被称为 datagram,我们先来看看IPv4 datagram的格式。

Version number ,这个4-bit字段指明了该datagram的版本,router必须知道版本才能正确的解析报文。
Header length ,IPv4的datagram header中有一个可变长度的options字段,因此必须要明确报文头部总长度。
Type of service(TOS) ,datagram按照提供服务的类型可被分为几种,比如用于网络电话应用的real-time datagrams和用于FTP的non-real-time datagrams,还有传输层我们曾经讨论过的用于Explicit Congestion Notification的datagram类型。具体datagram的类型是由路由器的管理员决定的。
Datagram length ,指明了本datagram的总长度,即header+payload,单位为bytes。因为这个字段共16个bits,因此理论上IP datagram的最大长度为65535 bytes。但是事实上datagram很少会大于1500 bytes,因为链路层的frame携带payload的最大值通常为1500 bytes,而datagram到链路层后是要被封装到frame的payload中进行传输的。
Identifier, flags, fragmentation offset ,这三个字段都与之后我们将要讨论的【 IP fragmentation 】有关。需要注意的是IPv6已经取消了fragmentation功能。
Time-to-live(TTL) ,该字段保证了datagram在经过TTL个路由器后自毁——被下一个路由器丢弃。即每经过一个路由器TTL减一,TTL为0时自毁。这样做的目的是防止datagram在【路由环路】中无限存活导致网络资源持续被占用。
Protocol ,这个字段只在datagram到达end system时才有用,其中的值代表本datagram携带的payload应该对应使用【哪个传输层协议】进行传输。比如protocol=6代表应该使用TCP传输,protocol=17代表使用UDP传输(还有其他可能,因为传输层不止两个协议)。该字段非常重要,因为它【联系了网络层和传输层】,功能上有点类似于传输层协议中的port number——【联系了传输层和具体的应用】。之后学习链路层时我们也会看到frame中同样有个字段联系数据链路层和网络层。
Header checksum ,该字段帮助路由器检查接收到的datagram的【header】是否存在bit error,当确认某datagram的header确实存在bit error后路由器通常会直接将其丢弃。要注意的是因为datagram中比如TTL字段和options字段会在传输过程中动态改变,因此路由器必须要提供存储和计算checksum的功能,checksum每经过一个路由器都要被重新计算。
为什么传输层提供了checksum功能,网络层还要提供?
- 网络层仅仅对datagram的header进行数据校验,而TCP/UDP会对segment整体进行校验
- TCP/UDP和IP不一定属于同一个协议栈,比如TCP可以在非IP协议上运行,而IP协议同样也可以将数据传递给非TCP/UDP协议。
Source and destination IP addresses ,当发送端创建一个datagram时,它会同时设置好其中的source/destination IP address。
发送端一般通过DNS lookup来获取destination IP address
Options ,该字段使得IP header具备可拓展性,很少会被使用到,但现实情况中却因为options这个字段的存在,使得很多事情变得复杂了。
因为options字段的存在所以datagram的header是变长的,这让终端无法提前预知payload到底从datagram的哪个位置开始,因此必须要消耗算力去找;而且因为一些情况下datagram确实要用到option来拓展一些功能,但其他大多数datagram都用不到,这就使得路由器处理不同datagram的时间可能相差很多,而这个问题在高性能网络应用中非常致命,因此IPv6也把options字段砍了。
Data(payload) ,这里面存放datagram携带的数据,大多数情况下为一个完整的运输层segment,也可能是ICMP message等其它类型的数据。
IP datagram的header总长为20 bytes(不包含options)。
4.3.2 IPv4 Datagram Fragmentation
并不是所有的链路层协议都像Ethernet一样定义frame的payload为1500 bytes,另外一些广域网链路的frame可能只能携带最多576 bytes的payload。
链路层frame可以携带payload的最大量被称为 maximum transmission unit(MTU) 。
因为IP datagram必须被封装成链路层frame才可以被放到链路上传输,因此【MTU的大小决定了datagram的大小】。
通信双方之间逻辑链路包含的每一段子链路(两个路由器之间)使用的协议可能并不相同
如果一个路由器准备发出的datagram大小超过了对应output link的MTU怎么办呢?IP协议采取的办法是 fragmentation (分片),将datagram中的payload拆分为多个部分,再每个部分各自封装成新的datagrams,这些新的datagrams被称为 fragments 。
fragment是特殊的datagram
fragments到达接收端的运输层之前必须要【先被组装(reassembling)好】,因为TCP和UDP都必须要接收完整的datagram才能正常运作。
reassembling的工作由end system完成。当终端收到来自同一个IP的一串datagrams时,它会检查这些datagrams是不是属于某个大datagram的fragments,假如这些datagrams中确实存在一些fragments,则它还要判断自己是否接收完毕了属于某一个大datagram的所有fragments,最后考虑如何将它们重组。
IP datagram header中的 identification flag、identifier和 fragmentation offset 就是用来实现datagram重组的。发送端每发送一个datagram,其中的identifier字段就会加一,当传输途中某router对某大datagram进行分片后,分好的所有小datagrams(fragments)的identifier字段与大datagram相同。这样一来当接收端收到一串datagrams时,检查identifier字段就知道它们是不是fragment了(identifier相同的都是fragments)
因为IP是不可靠的协议,所以一个datagram的某些fragments可能无法到达接收端,为了让接收端能够明确的知道自己收到了某一个datagram拆分而成的所有fragments,采用以下方法:
- 用fragmentation offset字段代表某一个fragment应该被放在重组datagram中的哪个位置
- 用flag字段(3-bit,不过现在只用到2 bits)中的DF(Don’t Fragment)位标识是否允许分片——0允许,1不允许;flag中的MF(More Fragment)位表示是否接收到了某datagram的最后一个分片——0代表当前fragment是最后一块,1代表不是。
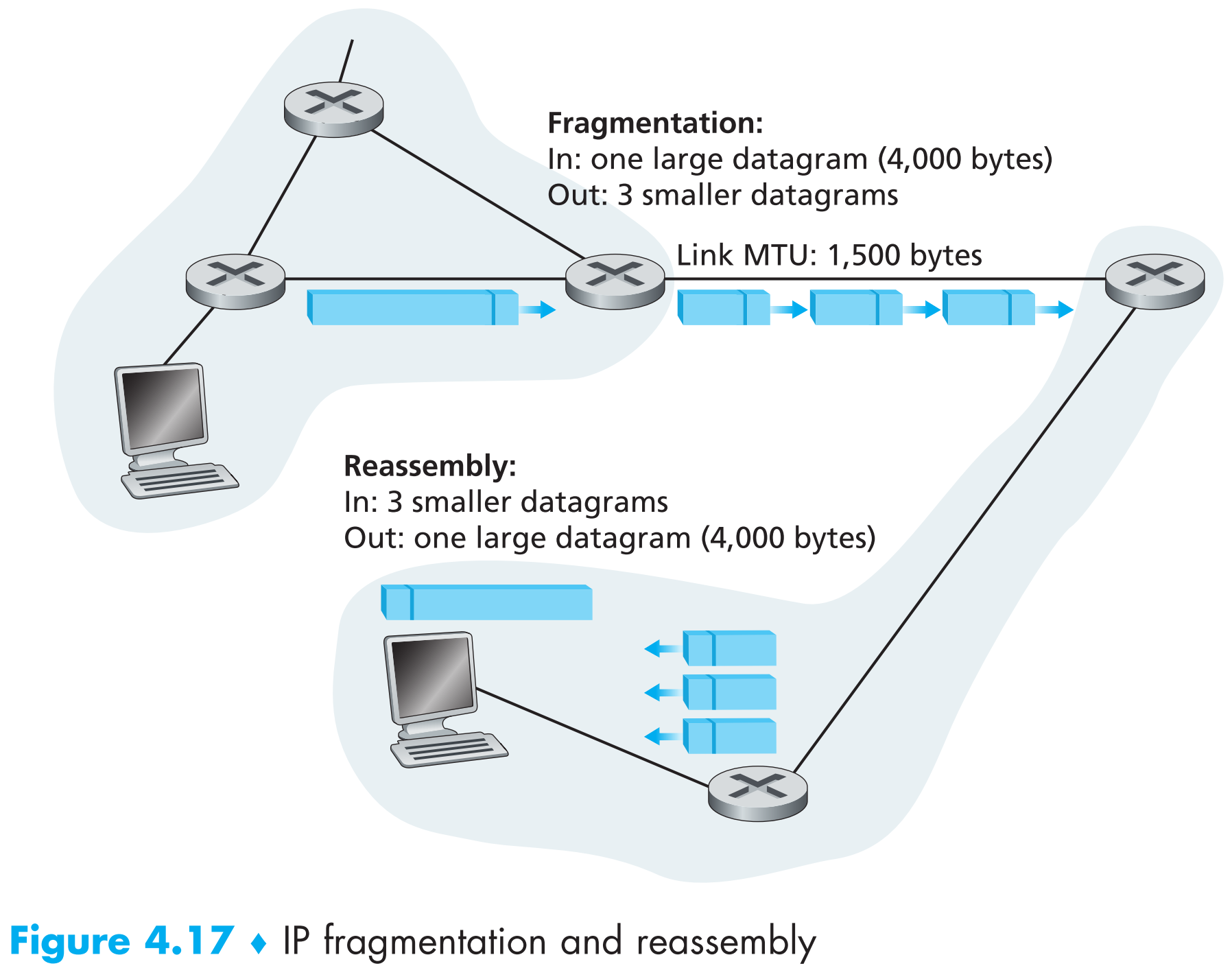
下面是一个fragmentation的示例,一个4000 bytes的datagramd到达路由器后,发现它对应output link的MTU = 1500 bytes,也就是说,它必须被拆分成3个fragments发送。
4.3.3 IPv4 Addressing
因为所有的终端和router都通过【物理接口】收发IP datagrams,IP协议规定所有这些接口都必须拥有自己的IP地址,因此IP地址本质上是与接口绑定而非与终端或者路由器绑定。
一个IP地址长度为32-bit,因此理论上总共有$ 2^{32} $(4亿)个IP地址,这些地址通常以 dotted-decimal notation 的形式写出,每个byte用点分隔,如192.32.216.9;另外还有 binary notation 形式,每8个bits用点分隔,如192.32.216.9的binary notation为 11000001 00100000 11011000 00001001 。
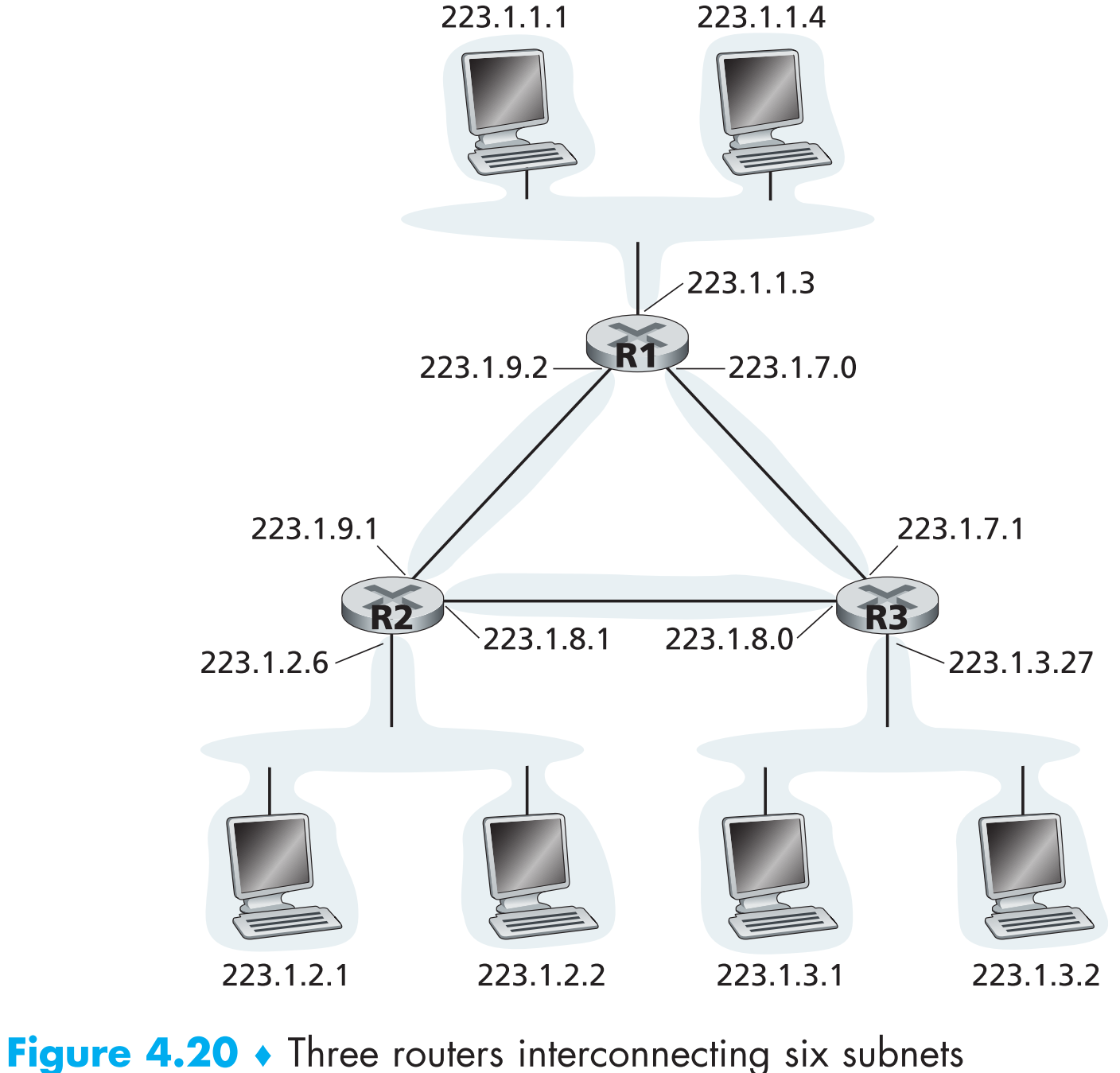
国际互联网中host与router上的每一个网络接口都必须有一个国际上独一无二的IP地址。IP地址与接口的示例图:
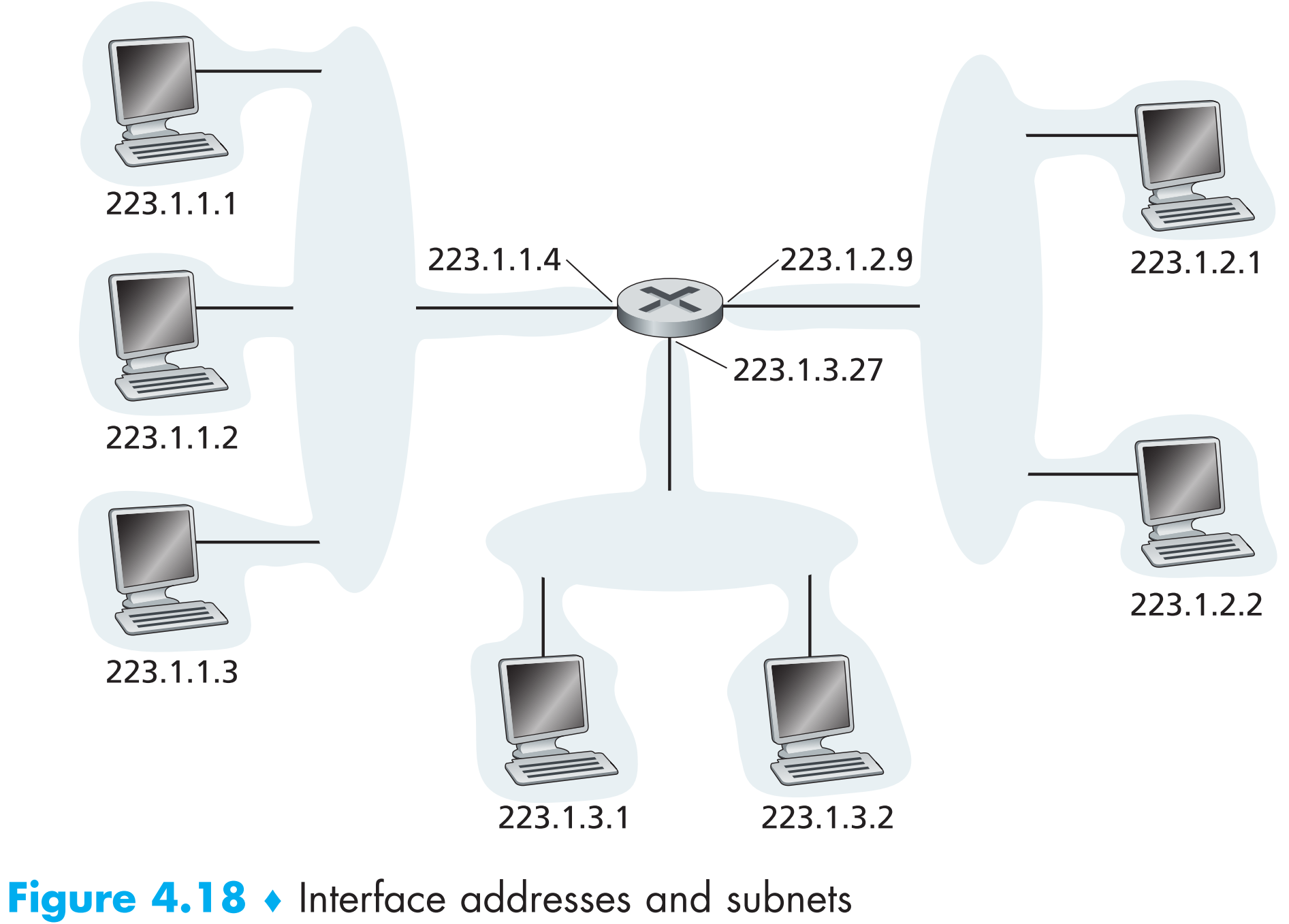
注意左上方的三个hosts以及它们最终连接到的路由器接口IP地址都是223.1.1.xxx这样的形式,即它们IP地址左侧24位相同,只有右侧8位不同。路由器接口和三个hosts之间通过一个或者几个二层设备如【Ethernet switch】或者【wireless access point】相连,这些二层设备也组成一个小网络,称为 subnet(子网) ,每一个subnet都有一个IP地址形如: 223.1.1.0/24,该写法被称为Classless Interdomain Routing(CIDR),尾部的“/24”代表 subnet mask(子网掩码) ,“/24”意味着这个subnet中的IP地址范围为223.1.1.0~223.1.1.255(即固定的前24位代表这个subnet本身,后8位形成的IP地址空间在这个子网中可任意分配),比如本例223.1.1.0/24这个子网中所有网络接口的IP地址都为223.1.1.xxx这样的形式。
现在使用的CIDR极大的增加了网络分配的灵活性,因为其subnet mask可以为任意位。而采用CIDR之前一直在使用的 classful addressing 则将subnet mask限制为8位(A类网络)、16位(B类网络)以及24位(C类网络),该策略的问题在于,如果某个机构想要购买一些IP地址,最小也得买C类网络的IP地址——一个足够$ 2^8-2 $ 个主机(其中1个为广播地址,另一个为回环地址,不算做可用IP)使用的网络,但其实很多小型机构根本不需要这么多IP地址,而对于很多中型机构C类又不够用,而B类又太多了——$ 2^{16}-2 $个地址,这就会造成极大的IP地址资源浪费。
不过路由器的接口也不总是连接到一个由二层设备组成的子网,因为有可能两个路由器的接口(即两个子网)直接相连,如下图
现在给出subnet的定义:
To determine the subnets, detach each interface from its host or router, creating islands of isolated networks, with interfaces terminating the end points of the isolated networks. Each of these isolated networks is called a subnet.
【255.255.255.255】为广播地址。如果sender发送了一个目的地址为255.255.255.255的datagram,那么这个datagram将会被发送到与sender在同一子网下的所有hosts。
4.3.3.1 Obtaining a Block of Addresses
如何为公司或学校获取一个subnet?
首先要联系ISP,ISP一般持有某一个较大的子网(如200.23.16.0/20),将这个大子网划分后,分出来的小子网就可以分配给客户,比如将200.23.16.0/20均分给8个公司,分法如下:

给定一个IP地址,要将其划分为N个子网的步骤:
- 将IP地址写为二进制形式,将掩码到达的最高位标记
- 算出N的二进制,看它占几个二进制位,假设占Y位。那么所有新子网的掩码就是划分前网络掩码往后增加Y位
- 列举这Y位的所有排列组合,则【原IP地址到掩码最右侧一位为止】+【Y位的某个排列组合】就是一个子网。
那么ISP又是如何获取subnet的呢?
管理所有global IP addresses的非盈利机构是 Internet Corporation for Assigned Names and Numbers(ICANN),该机构不光管理IP地址的分配,也管理DNS root servers,另外还负责分配域名和解决域名冲突问题。
ICANN首先将IP地址分配给regional Internet registries(如ARIN,RIPE,APNIC和LACNIC),这些registries共同组成了ICANN的Address Supporting Organization,它们会对各自管辖范围内IP地址进行分配和管理。然后IP地址一步步往下分配,分到ISP后,普通机构的IP地址就可以直接由ISP来分配和管理了。
4.3.3.2 Obtaining a Host Address: The Dynamic Host Configuration Protocol
当一个机构获取到自己的subnet address后,它就可以给自己子网内所有设备的网络接口分配IP地址了,一般情况下路由器接口的IP地址由网络管理员手动配置,而子网中hosts的IP地址大多情况下通过 Dynamic Host Configuration Protocol(DHCP) 来自动分配。通过配置DHCP,使得子网中任意一台host每次连上网后都能从DHCP server处【获取】到IP地址(固定的或者临时的temporary IP address)。给某一台host分配好IP地址后,DHCP server还会给该host提供关于它IP地址的一些必要信息,比如该IP地址的子网掩码,该IP地址连接到的第一个路由器的接口地址(即网关),以及local DNS server的地址。
因为DHCP将【host连接到Internet】的网络层面的操作给自动化了,因此它也被称为 plug-and-play或者 zeroconf(zero-configuration) 协议。DHCP为网络管理员提供了极大的便利,否则为一个子网内所有的hosts手动配置IP地址将是一个非常费时费力的工程,且如果后期网络拓扑发生变化(有host退出子网或者加入子网),管理员也无需手动修改。设想一下,一个学生扛着笔记本从宿舍走到图书馆再走到教室,很有可能这三个地方属于三个不同的subnets,如果没有DHCP的话,每到达一个新的地点该笔记本就需要:1. 网络管理员查询当前可用的IP地址并为该笔记本手动分配可用的IP地址。2. 该学生手动在笔记本上对IP地址做出相应的改变。
DHCP是基于C/S架构的协议,client通常为一个新加入子网的host,其目的是获取该子网中一个可用的IP地址。一般情况下,每一个子网中都会设置一个DHCP server,如果某子网中没有DHCP server,那么就需要 DHCP relay agent(由路由器扮演) 给出其他子网中DHCP server的IP地址,由其他子网中的DHCP server代为当前子网分配IP地址。如下图,中间的路由器就充当DHCP relay agent,当223.1.1和223.1.3这两个子网中新加入了host时,就需要路由器先给出223.1.2子网中DHCP server的IP地址223.1.2.5,由它来代为其他子网中新加入的host分配IP地址。
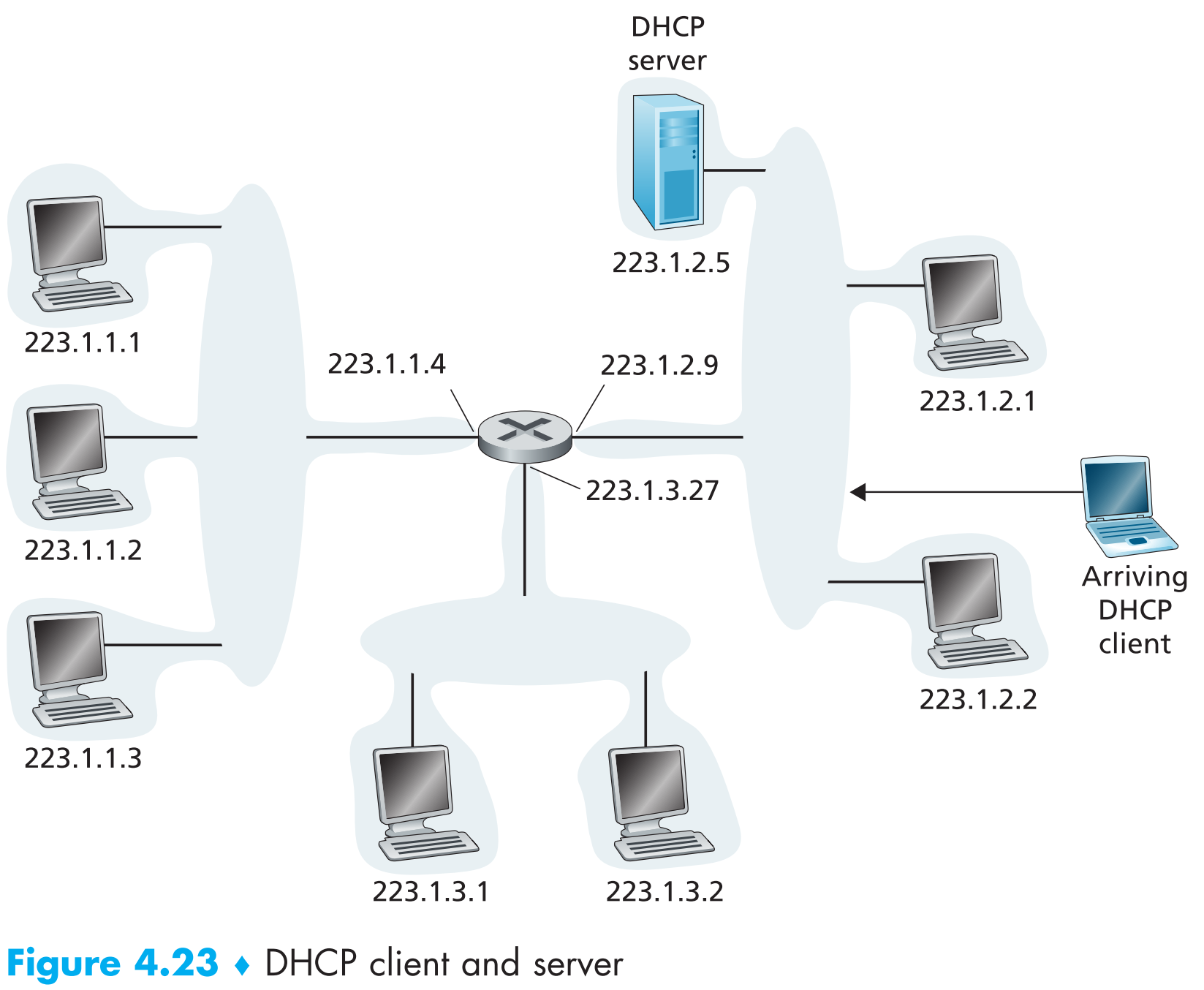
接下来的所有讨论都默认本子网中有DHCP server。
当一个新host加入子网时,DHCP自动分配IP地址的过程分为4步:
DHCP server dicovery
新host(client)进入子网的第一步就是找DHCP server。它会先【广播】一个基于UDP的 DHCP discover message ——即该message到达网络层后被封装成目标地址为255.255.255.255的datagram,其源地址为0.0.0.0。接着该datagram被发送到数据链路层,封装成frame并被复制多份,在本子网中广播。
DHCP server offer(s)
当DHCP server收到DHCP discover message后,会广播一个 DHCP offer message 。因为一个子网中可能存在多个DHCP servers,所以client可能会收到多个offers,每个offer中都包含以下字段:【transaction ID】、【准备为client分配的IP地址以及对应的子网掩码】以及【IP address lease time(本IP地址还剩多久到期)】。
DHCP request
client从所有收到的offer中选择一份,并给提供该offer的DHCP server回复一个 DHCP request message ,里面包含了一些配置参数。
DHCP ACK
DHCP server收到DHCP request message后,回复给client一个 DHCP ACK message 来确认刚刚client请求的配置参数。
client收到DHCP ACK后,就可以开始使用刚刚分配的IP地址了(租期内)

有时候client可能会觉得租期太短了,想要加钟,DHCP也允许这样的请求。
DHCP的缺点在于如果一个host在使用基于TCP的网络应用,那么当该host从一个子网移动到另外一个子网时,TCP连接会断开。因为TCP是面向连接的,切换子网会导致TCP请求端源地址改变。不过之后我们会学习到如何解决这个问题。
4.3.4 Network Address Translation (NAT)
NAT两大作用:1. 隐藏子网信息。2. 节省IP地址。
下图展示了一个启用了NAT的拓扑图,NAT路由器右侧的接口连接了一个家庭网络(10.0.0/24)。事实上10.0.0/24是私有网络,属于三大 private network/realm with private addresses之一的【10.0.0.0/8】,私有网络意味着该网络中的所有IP地址仅在本网络中唯一(或者说有意义)。但是,如果私有网络中的host想要与外界(互联网)通信怎么办呢?因为使用10.0.0.0/8这个私有网络的机构可能有千千万万个,当两个私有网络使用同一个私有IP与外网通信时,互联网该如何分辨哪个IP属于哪个私有网络呢?这时就需要NAT参与了。
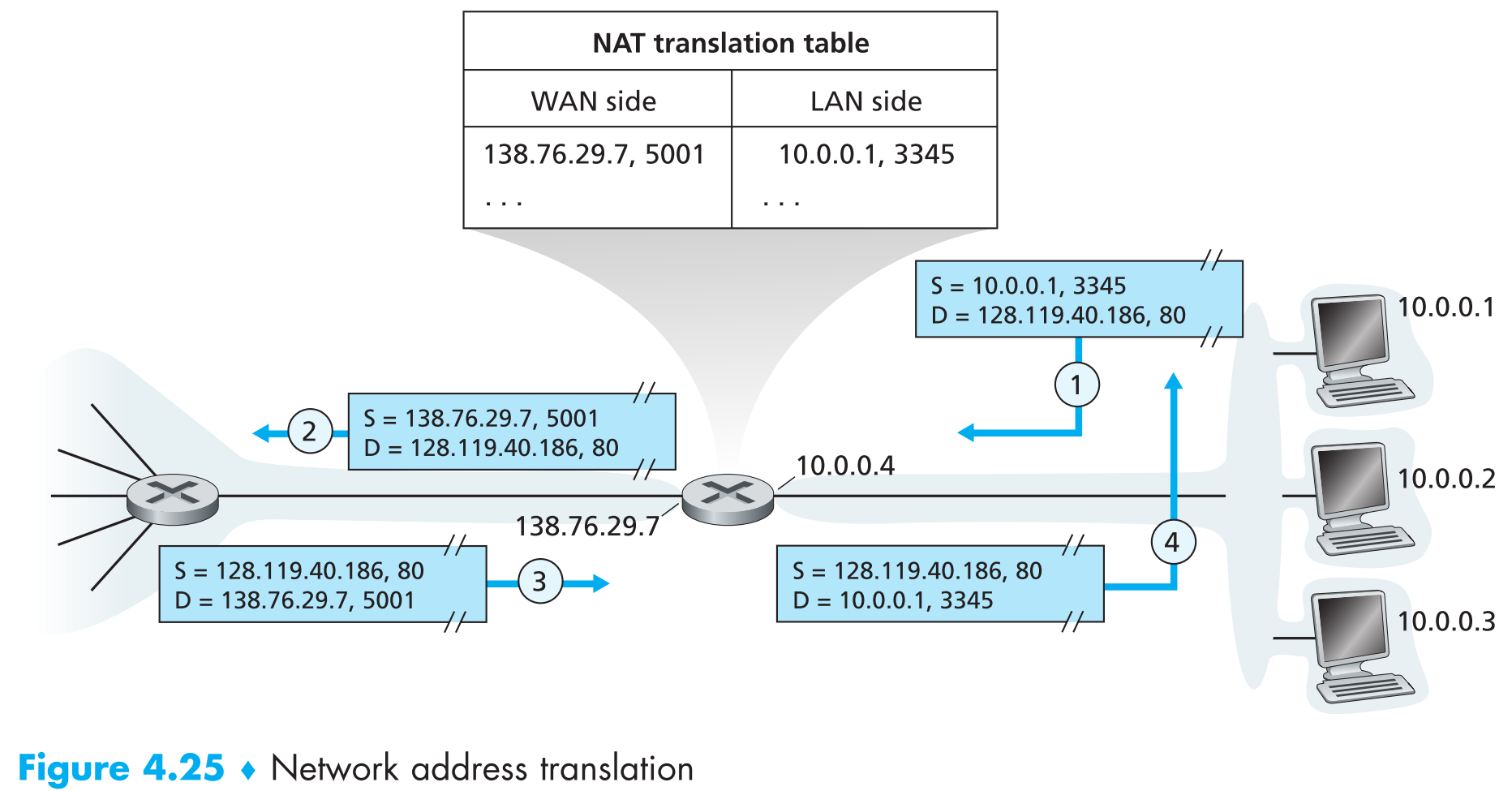
启用了NAT的路由器在外界看来并不像是一台路由器,因为对于外界互联网来说,它仅仅是一个具有某一特定IP地址的设备。 在上图中,右侧家庭网络中的所有流量从路由器出去后都具有相同的源IP地址:138.76.29.8;所有外界从路由器进到家庭网络中的流量也都具有相同的目标IP地址:138.76.29.8 。因此启用NAT后,家庭网络的信息相当于对外界 隐藏 起来了。
那么家庭网络中的hosts是如何获取它们各自的IP地址呢?NAT路由器的IP地址又是从哪里获取的呢?
答案都是DHCP。NAT路由器从【ISP的DHCP server】处获取自己的IP地址,家庭网络中的hosts通过【NAT路由器上内置的DHCP server】来获取自己的IP地址。
既然所有从WAN来到NAT router的datagrams都具有相同的目标IP地址,那么NAT router如何知道具体的哪个datagram应该发送给哪个家庭网络中的host呢?
答案是NAT router中有 **NAT translation table **提供内外网地址转换关系,该table中的每个条目由:公网【IP地址】以及【端口号】+内网【IP地址】以及【端口号】共同组成。以上图为例,假设家庭网络中IP地址为10.0.0.1的host正向互联网中一个IP地址为128.119.40.186的web server请求网页
host先会随机生成一个source port number(假设为3345)放在datagram中发送到LAN,经过一段时间的转发(这部分的内容会在链路层中详细探讨)后到达NAT router
NAT router新生成并替换该datagram中的source port number(假设新的为5001)以及将该datagram的源IP地址改为NAT router的公网地址(本例中为138.76.29.7),并将本次信息【公网IP地址:138.76.29.7,端口号:5001;内网IP地址:10.0.0.1,端口号:3345】记录到NAT转换表中。
注意NAT router生成新source port number的方法:从所有当前不在NAT translation table的(即当前未被使用的)port numbers中随机挑选一个。因为port number字段为16-bit,因此【NAT协议可以用一个公网IP扩展出超过60000个并发的连接】
过了一会web server收到数据包(网页请求),它对NAT地址转换的整个操作并不知情,只知道请求方的IP地址为138.76.29.7,端口号为5001,按这个联系方式把网页发过去就完事了。
当请求的网页以datagrams的形式到达NAT router时,NAT router会先将数据包中的公网地址信息【IP:138.76.29.7,端口号:5001】取出并依据它查询NAT translation table,获得对应的内网地址信息 【IP:10.0.0.1,端口号3345】,然后将数据包的公网地址信息改为内网地址信息,发送到内网中。
从上述过程也可以看出,除非内网主机向外网主动发起通信,否则外网无法主动通信内网中的主机(除非使用静态NAT),这样提高了安全性。
关于NAT技术也有一些反对的声音,理由是端口号应该专用来寻找进程,而非主机,否则可能会存在冲突。比如内网中如果有多台web servers,他们都必须通过80端口收发数据包,这时使用NAT的话就无法区分它们了。所以公共服务器最好使用外网地址,不过这个问题也可以通过 NAT traversal tools 以及 Universal Plug and Play(UPnP)协议 解决,感兴趣的读者可自行查阅资料。
另外一些反对的声音认为router属于第三层设备,它就不应该参与其他层的事务,只负责进行端到端的数据传输,否则就会提高网络层级之间的耦合度,NAT技术可以修改端口号这一点就干涉了运输层的工作。这个观点很有道理,不过NAT本质上并不是互联网运行的重要组成部分,就像现在也有很多工作在网络层的 middleboxs(中间件) 和NAT一样并不仅仅发挥端到端数据传输的作用。类似于NAT的这些中间件虽然不提供传统网络层设备的forwarding功能, 但是它们起到其他很重要的作用,比如load balancing(负载均衡)、traffic firewalling(防火墙)等。因此在我们后面的讨论中,用 generalized forwarding代替传统的forwarding,旨在表示它并不局限于packet forwarding这一个功能,而是包含了许多其他中间件的功能。
4.3.5 IPv6
IPv4的地址空间为32-bit,即全世界最多$ 2^{32} $个IPv4地址,现在已经快要全部用完了,因此具有更大地址空间的IP协议诞生了——IPv6,它不光拥有了更大的地址空间,还顺带修改了IPv4中的一些不合理的设计。
4.3.5.1 IPv6 Datagram Format
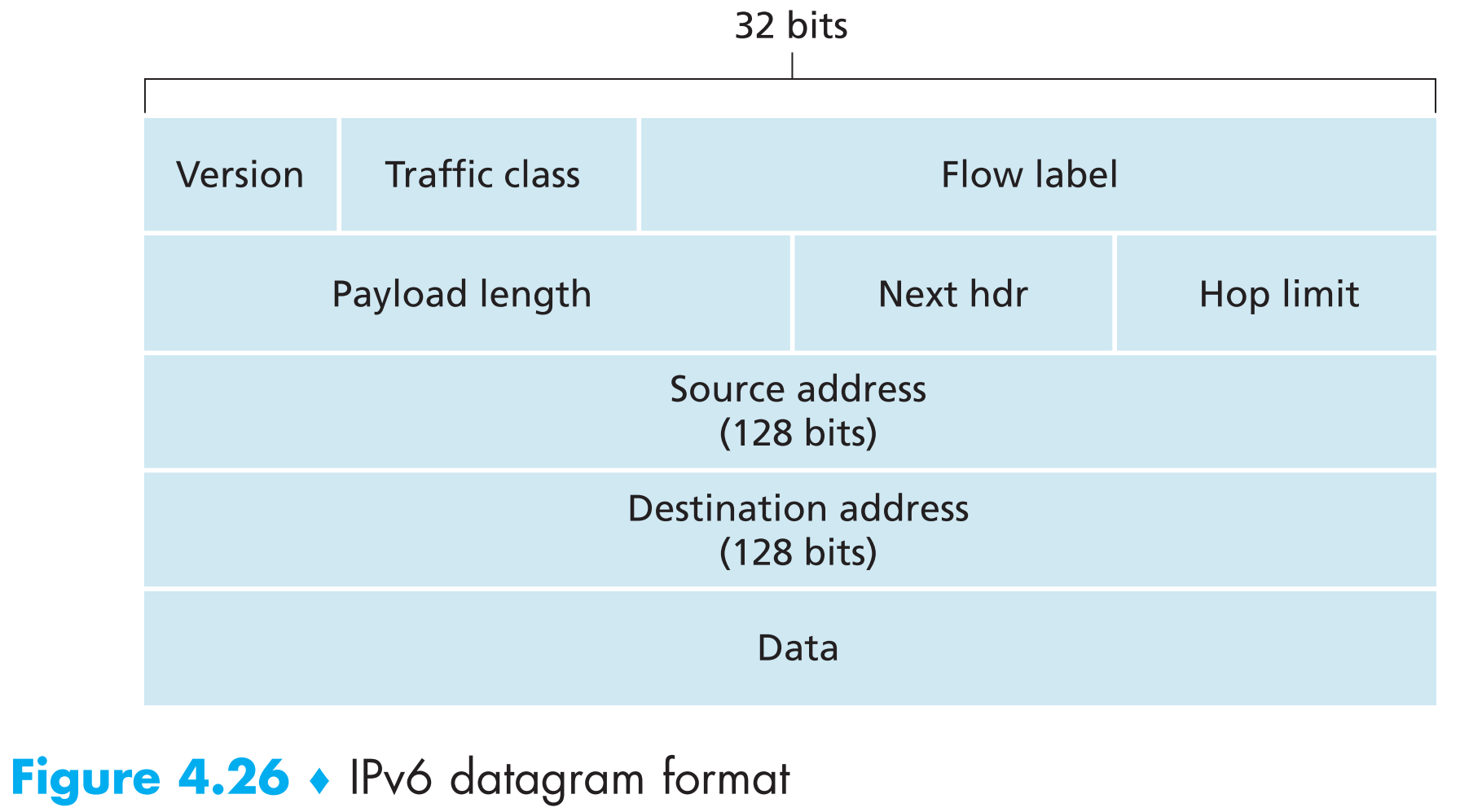
Expanded addressing capabilities。IPv6将地址空间从32-bit增加到了128-bit,这样一来IP地址将不可能耗尽(即使地球上每一粒沙子都有IP地址)。除了unicast(单播)和multicast(多播)地址,IPv6还引入了新的地址类型 anycast address ,使得datagram可以被递交给某一个“host群落”中距离sender最近(基于路由协议度量)的一个host。
A streamlined 40-byte header。IPv6删除或改变了IPv4中的一些字段,使得【header的总长度固定】,这样就使得路由器可以高效的处理IPv6 datagram。
Flow labeling。IPv6可以定义多种flow,当sender请求特殊处理某些数据包时(比如用户要求实时性较强的服务时),IPv6可以将数据包标记为属于不同的flow,这样就可以方便的对不同的用户需求提供不同的服务。比如音频和视频传输的数据被视为flow;文件传输和电子邮件传输的数据被视为另外一种flow;甚至某个人交了很多网费(电信皇冠会员),所有与它相关的数据流量都可以被视为高优先级的flow。
Version。这个4-bit的字段说明了datagram使用的协议版本,IPv6中该字段的值为6。不过要注意的是,即使把该字段改成4,也不能把IPv6数据包改成IPv4.
Traffic class。这个8-bit的字段区分了不同流量的优先级。比如传输音频的流量优先级应该高于传输电子邮件的流量。
Flow label。20-bit长,用来分辨datagram属于哪个flow。
Payload length。16-bit
Next header。说明该datagram中的payload要用运输层的哪个协议递送。与IPv4中的protocol字段相同。
Hop limit。TTL
在看看IPv4中哪些字段在IPv6中不再被使用了。
Fragmentation/reassembly。IPv6不允许路由器对datagram进行分片和重组,【现在只能在终端进行】。如果路由器收到一个过大的IPv6 datagram以至于无法一次性通过某条output link发送,那么路由器就会直接把它丢弃,然后给sender发送一个“Packet Too Big” ICMP error message,sender收到后会将刚才的datagram分片并重新发送。因为分片是一个十分耗时间的操作,因此IPv6的这一改动极大的提升了forwarding的效率。
Header checksum。因为传输层和经常使用的链路层协议都有checksum功能,网络层再加上checksum确实有些冗余,所以IPv6不再提供。而且因为现在的网络环境下快速forwarding才是重中之重,之前学习过IPv4 datagram在传输过程中TTL字段会不断变化,因此checksum每到一个路由器就要被重新计算,再加上路由器还要进行分片之类的操作… 换成IPv6后这些工作路由器都不用做了,forwarding速度进一步提高。
Options。取消掉Options字段使得header长度固定,提高路由器的处理速度。但是Options字段其实并没有完全被取消掉,而是可以作为next header存在,next header指的是一个datagram中header末尾的下一个字节一般是它所携带的segment的header,这个segment的header就称为datagram的next header。就像TCP或者UDP的header可以作为IP datagram的next header,Options可以直接作为IP datagram的next header存在。
4.3.5.2 Transitioning from IPv4 to IPv6
如何让已经广泛使用IPv4协议的互联网变为使用IPv6呢?这个问题的关键点在于如何解决IPv6系统可以向下兼容IPv4,而IPv4却无法兼容IPv6。
一种方案是选择某个时间点(flag day)把所有互联网设备关掉,然后将IPv4升级成IPv6 ,但是考虑到现在全世界网络设备的数量,这种方案是不可行的。
另外一种比较实际的方案利用了 tunneling 技术,如下图:
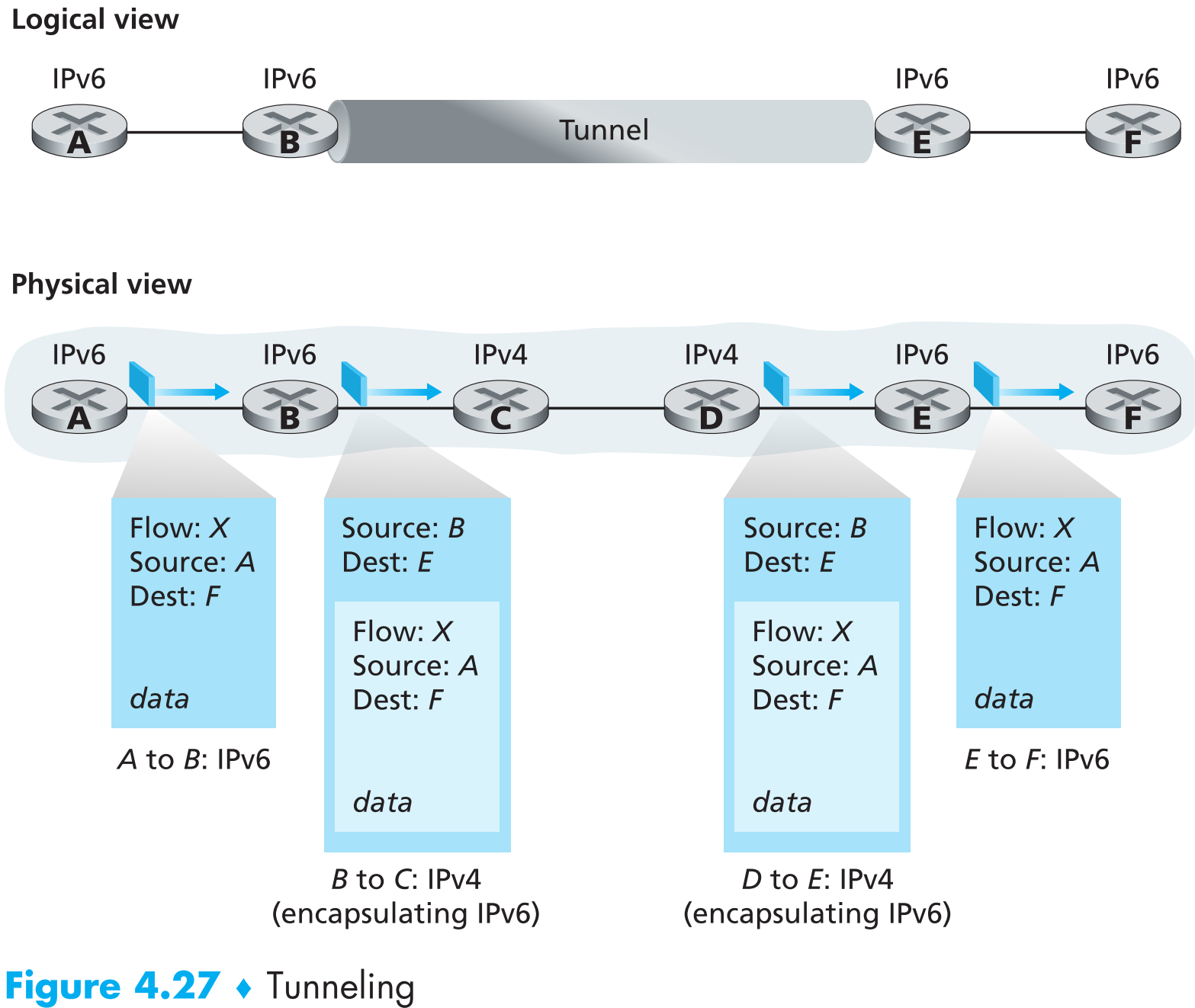
假设两个IPv6节点B和E想要使用IPv6 datagram互相通信,但是它们之间的逻辑链路上存在一些IPv4路由器,我们可以将这些存在于两个IPv6 routers之间的IPv4 routers视为 tunnel 。tunneling这个操作就是发送端的IPv6节点B【将整个IPv6 datagram作为payload放到IPv4 datagram中发送】,这样该datagram就可以顺利的通过tunnel,到达接收端的IPv6节点E,E收到这个特殊的IPv4 datagram后看到它里面包含了一个完整的IPv6 datagram就会将其取出并进行下一步处理。
想要更改网络层协议是非常困难的,因为替换网络层协议就相当于换掉一栋房子的地基,要么就得先把整个房子拆掉,或者至少得让房子里的住户先全部搬出来,后者似乎可行,但当这个房子中的住户为几十亿时,就变得完全不可行了。
4.4 Generalized Forwarding and SDN
从之前的讨论中我们知道路由器将数据包forward到哪条output link上完全是依据数据包中的destination address字段来决定的,不过后来我们也提到过,现如今越来越多的middleboxes可以执行很多网络层的功能,比如NAT可以重写数据包的IP地址字段和端口号字段;防火墙可以根据数据包的头部字段来对数据包进行过滤。这么多的middleboxes,每个都有它们自己的定制的硬件、软件和管理接口,非常不方便网络管理员统一管理,因此 software-defined networking(SDN) 出现了 ,它的作用是将所有middleboxes的功能抽离出来形成统一的管理接口,这样网络管理员可以方便的对它们进行统一的管理,而不用一个个的配置。
传统forwarding的过程分为:查表(match)→转发(action)。SDN将match-plus-action的概念广义化了(即generalized forwarding),在SDN中【match】可以是匹配不同协议的header,而【action】则除了包含forwarding之外,还包含重写header字段(如NAT的功能),主动的阻塞或者丢弃数据包(比如防火墙的功能),将数据包发送到特殊的server来对其进行进一步的处理(比如DPI)。
因此传统的forwarding被广义化后,router table变成了 match-plus-action table,因为forwarding这个动作现在不仅仅取决于数据包的目的IP地址,还可能取决于其他因素。且因为现在forwarding的含义已经被广义化了,所以接下来本节的讨论中没有router,统统都叫packet switch。
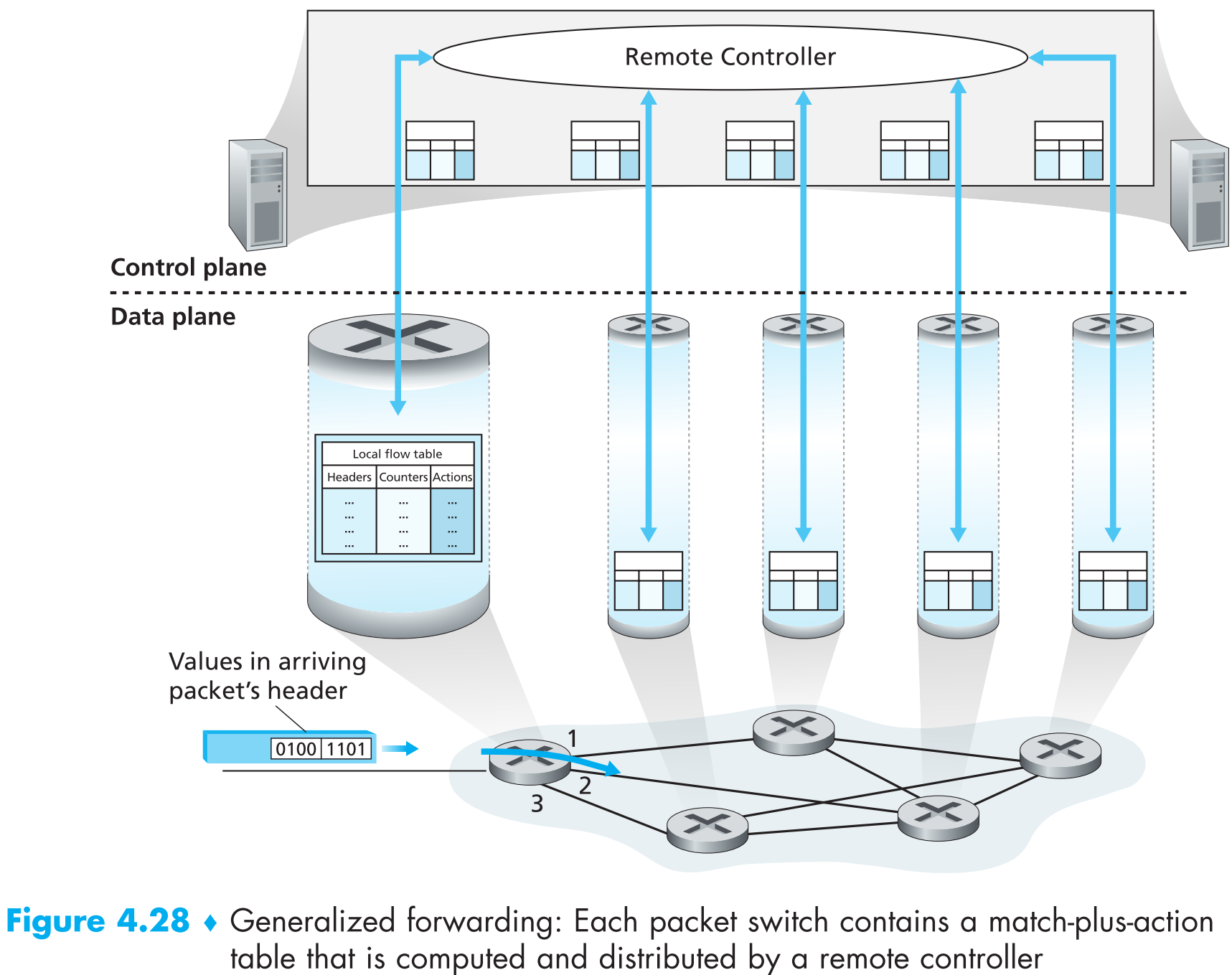
上图展示了一个应用SDN的网络,每一个路由器中的match-plus-action table都由remote contoller来计算和更新。
下面我们以OpenFlow协议为例,讨论广义化的forwarding。
在OpenFlow中match-plus-action table中的每一个条目都被称为一个 flow table,其中包含了一下字段:
A set of header field values(match)。新到达路由器的数据包会用自己的header来match这个字段,如果该数据包与所有flow table的header field都不匹配,就会被丢弃或者被发送给remote contoller做进一步处理。
A set of counters。当数据包与某flow table匹配时,该flow table中的counter就会+1
**A set of actions **。当数据包match了某flow table后,就会执行该字段内对应的动作(比如NAT功能,防火墙功能等)
4.4.1 Match
下图展示了一个flow table entry的所有字段
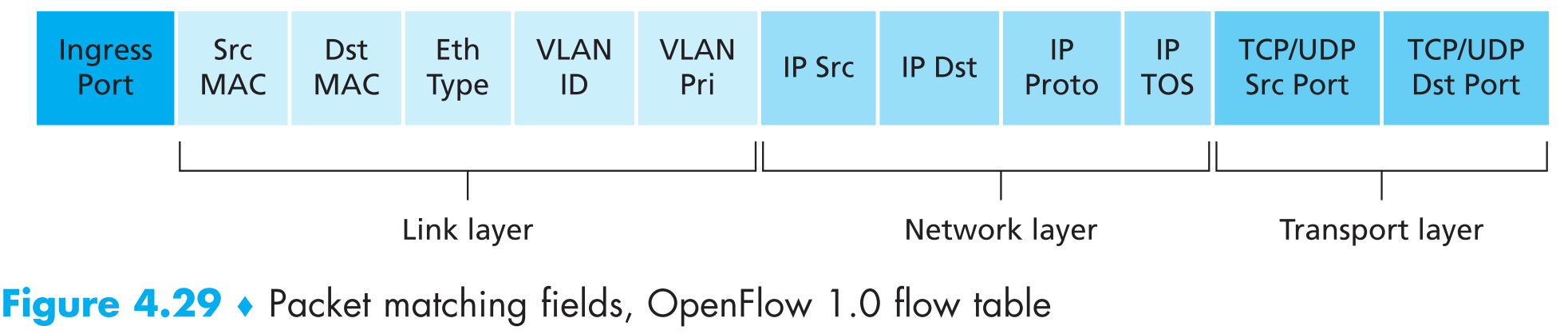
ingress port代表packet switch上用来接收数据包的端口。从图中可以看出SDN中的match-plus-action table可以同时match链路层、网络层以及传输层的数据包,这就意味着启用了OpenFlow的设备不光可以当作路由器来forward datagrams,还可以作为二层交换机来forward frames…
4.4.2 Action
flow table的每一个条目包含了0个或者多个actions,match到这个条目的数据包会按序执行这些actions,action分为以下几种:
- Forwarding。启用OpenFlow的设备接收到数据包后,可能将它forward到某个对应的output port,也可能广播到所有的output ports(除了接收它的port),也可能多播到几个特定的output ports。然后这个数据包可能会被发送到本设备对应的remote controller做进一步处理。
- Dropping。数据包match到一个无action的flow table条目时会被直接丢弃。
- Modify-field。packet被发到指定output port之前个别header字段可能要被修改。
4.4.3 OpenFlow Examples of Match-plus-action in Action
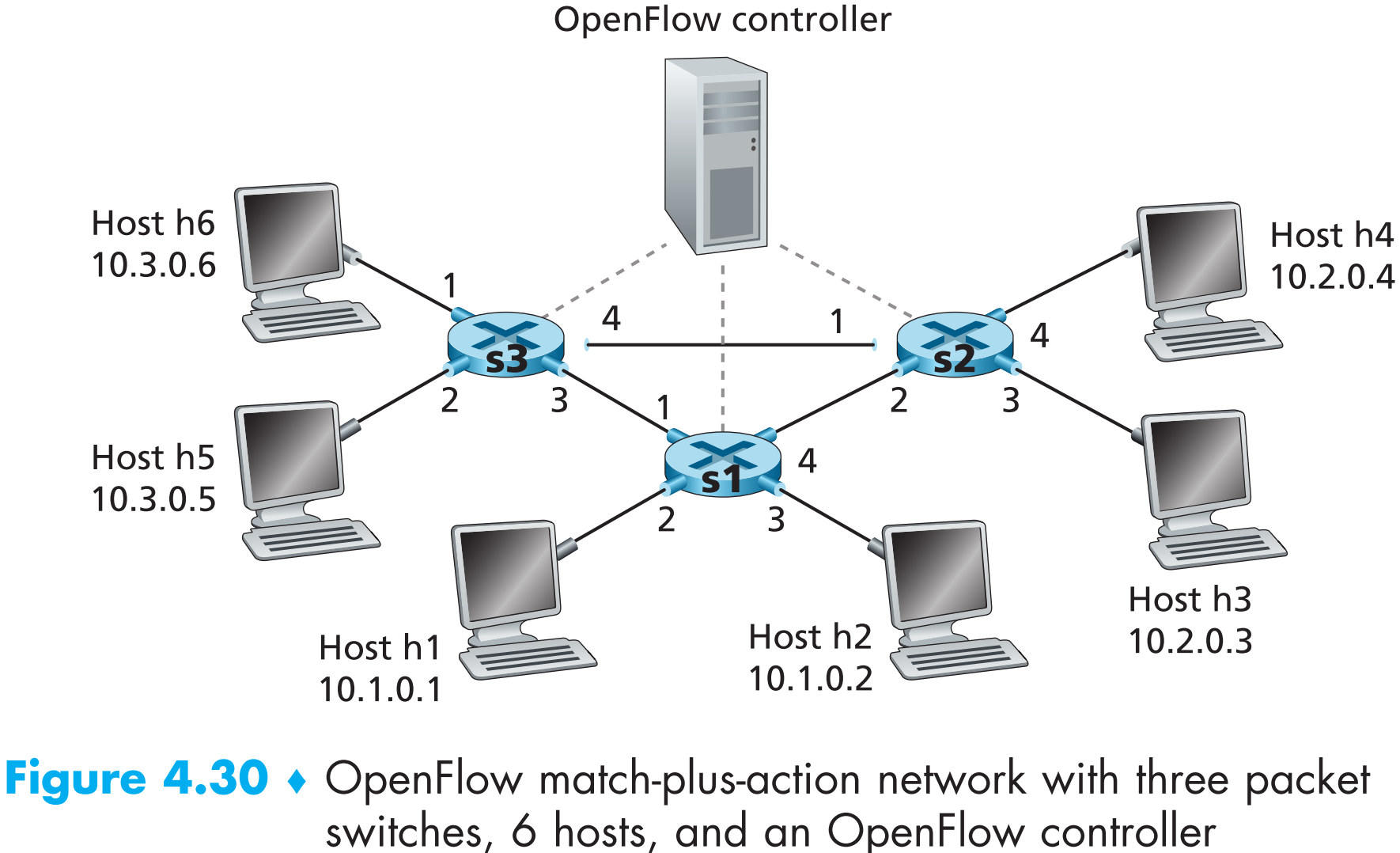
4.4.3.1 A First Example: Simple Forwarding
假定h5或h6给h3或h4发包,数据包要从s3到s1再到s2,则s1的flow table entry如下图所示

s3中也应该生成一条flow table entry
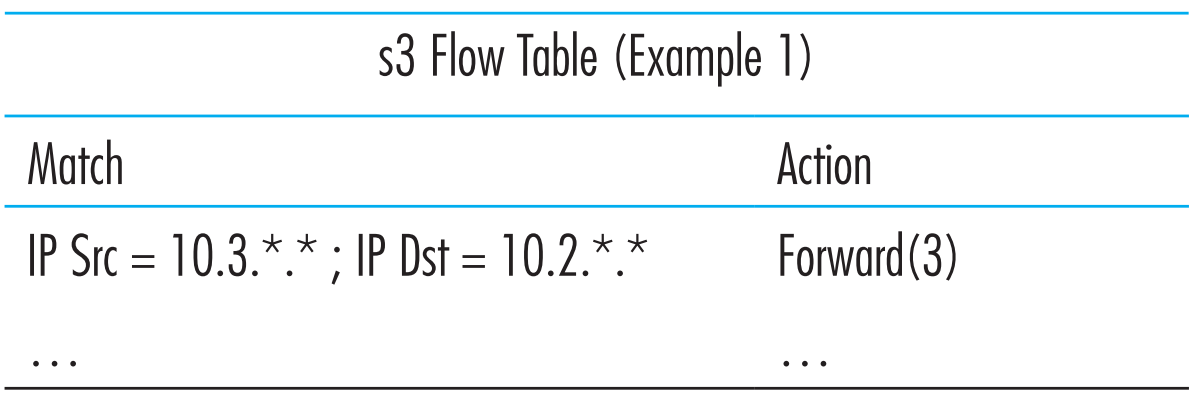
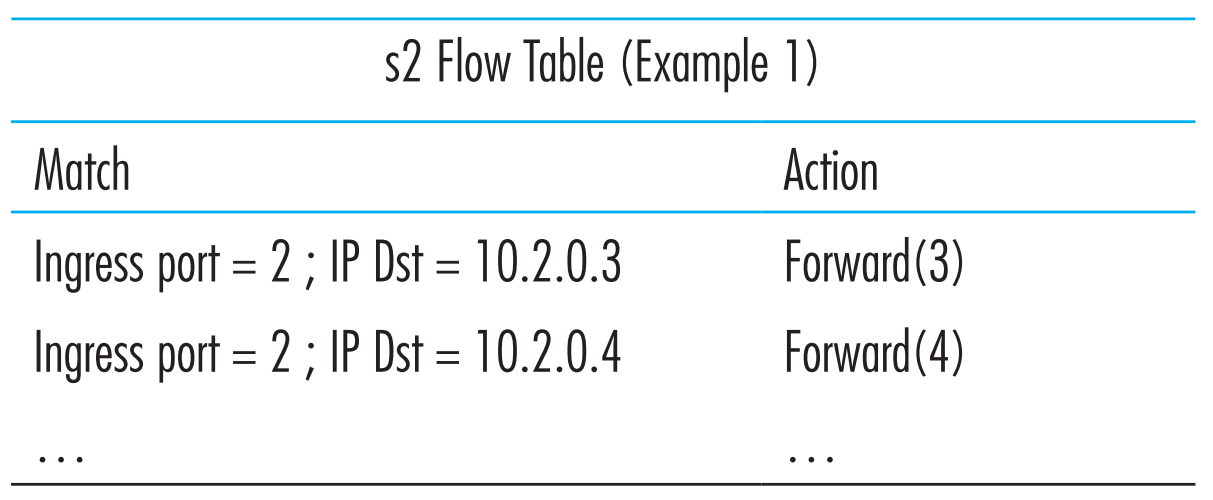
最后,s2中的flow table entry
4.4.3.2 A Second Example: Load Balancing
现在来看下第二个场景,假设从h3发出的数据包经过s2和s1发送到10.1.*.* 网段,h4发出的数据包经过s2、s3和s1也发送到10.1.*.* 网段。
note:这样的需求通过传统的destination-based forwarding是无法完成的。
则s2的flow table如下:
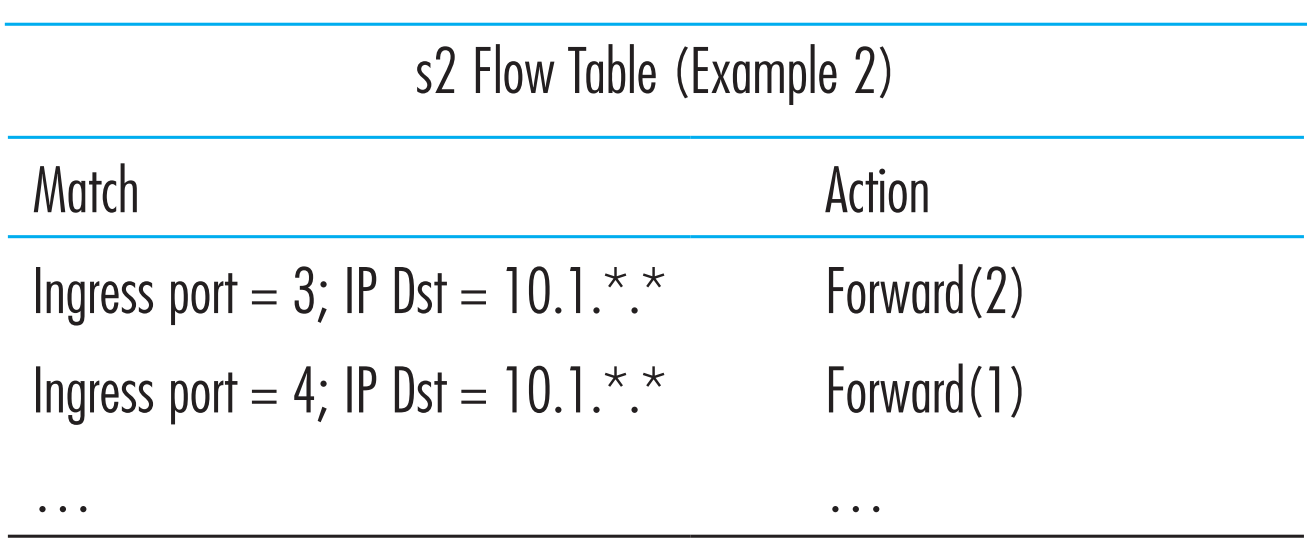
尝试自己写出s1和s3的flow table entries
4.4.3.3 A Third Example: Firewalling
假定s2只想接收经过s3到来的数据包,则s2的flow table如下:

只要s2的flow table中除了以上两条之外没有其他条目,就只有10.3.*.*的流量能够到达s2连接的hosts