《计网》Transport-Layer
3.1 Introduction and Transport-Layer Services
传输层协议为两个hosts上运行的进程提供 logical communication的支持,这种支持可以隐藏底层细节,让用户感觉其他hosts上(可能相距很远)的进程似乎都在自己的电脑上运行一样。不同的hosts的【进程】之间通过传输层提供的logical communication来互相通信。
在发送端,传输层接收其上层(应用层)的messages,将它们切碎成一个个的chunks,再将它们逐个封装成 segments ,发送给其下层(网络层)。
3.1.1 Relationship Between Transport and Network Layers
注意区分,transport layer protocols为【不同hosts上跑的进程】提供logical communication的服务,而network layer protocols为【不同的hosts】提供logical communication的服务。
类比一下,两户人家(hosts)位于地球南北两极,每户人家都有一对父母和一群小孩(processes),南极小孩们每年都要给北极小孩们写信(通信),小孩还小不懂事,所以【收集小孩们写好的信然后寄出】以及【接收所有的来信并分发给对应的小孩】都由它们的父母来完成。这整个过程中,邮局提供的服务可类比network layer提供的服务,即提供hosts之间的logical communication;两户人家的父母提供的服务可类比transport layer提供的服务,即提供process之间的logical communication。
另外这个例子也说明了:
- transport layer protocols是运行在end system上的。
- 如果父母出门了,那收集和分发邮件可能由年龄较大的孩子完成,那么它们可能提供完全不同的服务(可能会经常弄丢信件,又或者邮件寄取收费)。类似的,传输层也可以提供不同的服务(TCP, UDP)
- 如果邮局的服务出现了问题,那么父母提供给孩子们的服务必然会受影响。类似的,如果下层(如网络层)出现问题,则上层(如传输层)的服务必然也会出现问题,也就是说上层提供的服务是基于下层的。
3.1.2 Overview of the Transport Layer in the Internet
预备知识:
- IP协议提供 尽力而为 的数据传输服务,即IP协议不可靠。
- 当开发一个新应用时必须给它分配一个端口号。
传输层有两个协议:可靠的TCP和不可靠的UDP,它们最基本的作用就是将IP协议提供的【端到端的服务】拓展为【进程到进程的服务】。这个拓展的过程叫做 transport-layer multiplexing(将上层来的各个进程的数据包打包收集并发送到网络层)和demultiplexing(将下层来的数据包分发到各个进程) 。
3.2 Multiplexing and Demultiplexing
假设我们现在正在浏览网页(HTTP),并且正在进行一个FTP session以及两个Telnet session,所以正在运行4个进程。现在我们电脑的传输层收到了一个来自下层的datagram,它的任务就是把这个datagram解封装成segments并将其中的payload分发给正确的进程。
每一个segment中都有两个专门的字段,这两个字段就指明了该segment属于哪个process,即 source port number field 和 destination port number field 。所以收到下层传来的datagram并解封装为segment后,第一步传输层会提取这两个字段中的信息,然后按照信息指示将segment发送到对应的socket,这个过程就是 demultiplexing 。
从不同的sockets收集上层传来的数据流并封装成segments,然后将segments发送到网络层的过程就是 multiplexing 。要注意的是分用和复用这两个概念涉及的范围很广,绝不仅仅局限在传输层上,也不仅仅局限在计算机网络中。
3.3 Connectionless Transport: UDP
除了基本的分复用以及一些轻量级的差错检测,UDP跟IP协议几乎没有区别。注意UDP不像TCP一样需要三次握手来建立连接,所以UDP也被称为 connectionless 协议,DNS就是典型的使用UDP的应用,
使用UDP的几个理由:
Finer application-level control over what data is sent, and when
UDP不像TCP一样有非常繁琐的校验和控制机制(比如出错重传,拥塞控制),所以它的效率比较高,且传输速率比较稳定,可以满足及时性要求,虽然是不可靠的传输协议,但是对于某些应用(可以容忍一定的丢包,且对传输速率有要求)来说,UDP是最合适的。
No connection establishment
TCP传输数据前需要进行三次握手建立连接,是面向连接的传输层协议。而UDP则是无连接协议,不管对方情况怎样,不管网络状况怎样,发包就完事了。所以UDP比TCP快,在DNS query这种需要频繁发起通信的场景下,无连接可带来巨量的效率提升。
No connection state
为了提供可靠传输,TCP必须在本地维护很多连接状态信息(如接收和发送buffer,拥塞控制参数、序列号、确认号等),而UDP不用。因此一个专门提供某应用服务的server,这个应用如果是基于UDP的,则它可以支持更多同时在线的users。
Small packet header overhead
TCP segment的头部字段开销为20 bytes,而UDP segment仅仅8 bytes。
影音应用一般都使用UDP,虽然快但是缺点也很明显,不光是丢包问题,因为没有拥塞控制,使用UDP的应用越多,越容易让【整个网络】进入拥塞状态,因此基于UDP创造一种新的可以拥塞控制的协议是目前的一个研究方向。
其实即使使用UDP进行数据传输,也可以达到可靠传输的效果,要求就是在应用层实现可靠传输的功能(比如google的应用层协议QUIC,其下层协议是UDP,却能在chome上进行可靠传输)。自带可靠传输功能的应用很难实现,不过好处在于它【既实现了可靠传输,却不会像使用了TCP那样因为拥塞控制而被限速】。
3.3.1 UDP Segment Structure
UDP头部只有4个字段,每个字段2个bytes。

传输层协议的功能就是提供进程到进程的数据传输——即端口到端口的传输,所以UDP报文中必然有【源端口】和【目标端口】这两个字段。
【长度】字段说明了这个UDP报文携带了多少bytes的payload,因为每个UDP报文携带的payload量不同,所以必须要用一个字段来明确报文的大小。
【校验码字段】是提供给接收方的,接收方可以通过这个字段检查UDP报文中数据的正确性和完整性。
3.3.2 UDP Checksum
校验码字段的功能就是检查UDP报文在传输的过程中数据有没有被更改过(比如可能在传输过程中收到噪声的干扰而导致的数据错乱,也可能在路由器内部存储的时候顺序出现差错)。
校验码的大概原理是将所有数据按16bit(假定)为一组分成若干组,所有组加起来的和【取反——1变0,0变1】后作为checksum传输,接收端收到报文后,也把数据按16bit分组并相加,将结果再加上checksum,如果数据没问题的话结果应该是1111 1111 1111 1111,如果不是全1则说明数据被改动过了。
为什么很多链路层的协议(比如以太网)提供了差错控制,传输层还要提供呢?
因为报文的传输要经过很多条链路,我们无法保证这一路上所有的链路采用的二层协议都提供差错控制
即使segment在所有链路之间被正确的传输了,途中经过的router在将segment存储到buffer中时还是可能出现顺序错误
又因为网络层的IP协议是尽力而为的传输(不进行差错检测),所以传输层必须要提供一层端到端的差错校验,这其实是系统设计中的 end-end principle 的一个例子。
end-end principle:对某一种特定的功能,在高层上实现要比在低层上实现更具性价比。
要注意的是,UDP仅仅提供差错检测,如果发现segment出错,要么就把它直接丢弃,要么继续将这个错误的segment连带一个warning一并发送给应用程序。
3.4 Principles of Reliable Data Transfer
事实上除了传输层,数据链路层和应用层都可能需要reliable data transfer,因此这个概念几乎贯穿了整个计算机网络,同时它也是计算机网络中最重要的研究方向之一。
本章中我们将用rdt代表reliable data transfer和udt代表unreliable data transfer。
接下来我们将模拟循序渐进的开发一个reliable data transfer protocol。
3.4.1 Building a Reliable Data Transfer Protocol
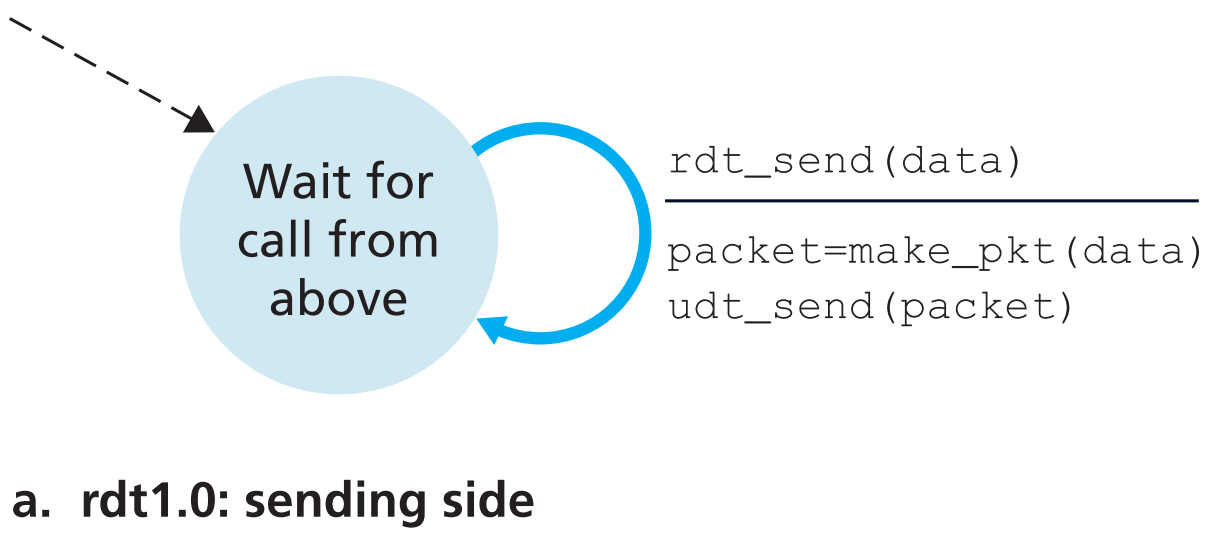
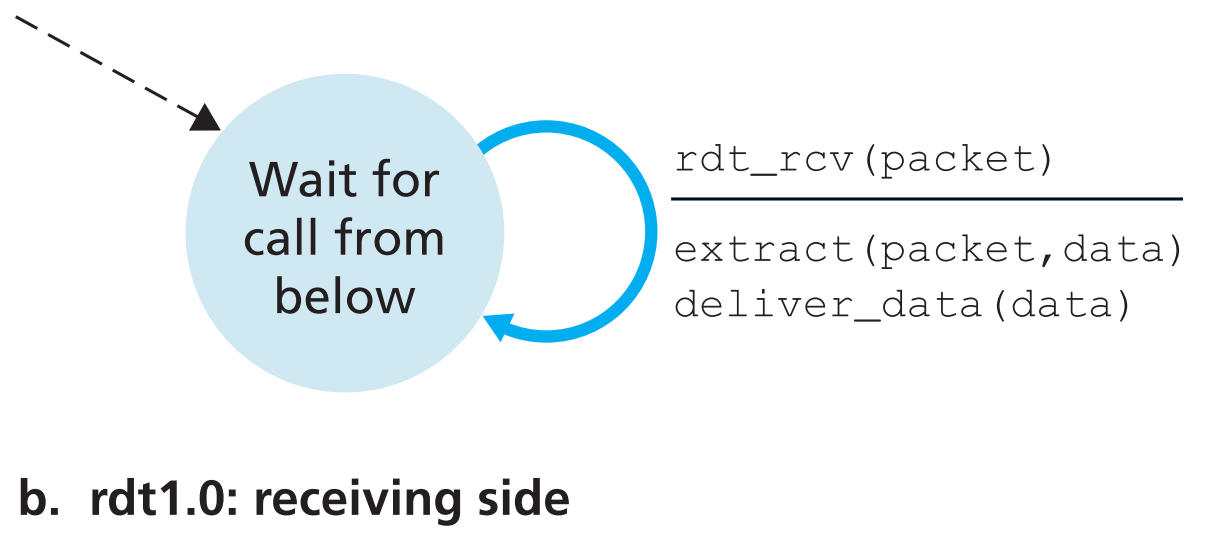
3.4.1.1 Reliable Data Transfer over a Perfectly Reliable Channel: rdt1.0
用finite-state machine(FSM)来描述,并把数据包统称为packet(因为可靠传输的概念不局限在传输层)。
rdt第一版本假定了【当前协议所在layer的低层提供了可靠数据传输】,即所有数据包都能按序到达接收端,且传输过程中不会出现bit错误;并且【接收端可以完美接收发送端以任何速率发送的所有报文】
【横线上方】是导致状态转变的事件,【横线下方】是事件发生时会采取的动作。不发生事件或者不采取行动用 $\Lambda$ 表示,起始状态用虚线箭头表示。
3.4.1.2 Reliable Data Transfer over a Channel with Bit Errors: rdt2.0
现在仍然假定所有packets都能【按序】到达接收端,不过【传输过程中可能会出现bit错误】。
在这样的情况下想要实现可靠传输,该怎么做呢?
先类比人类对话,两个人对话,如果听者没有听清说者的话,则听者会说类似“Repeat that shit”的话告知说者自己没有听懂,说者就重复说一遍;或者类似“OK I get that”的话告知说者自己听懂了。把这个方法类比到网络中,就是 ARQ(Automatic Repeat reQuest) protocol ,这个协议的三个功能刚好可以解决传输过程中可能出现的bit错误问题。
Error detection
在第六章还会详细探讨,这里我们只需知道一个报文需要使用额外的字段(就像UDP的checksum)来完成差错检测功能。
Receiver feedback
能让sender了解receiver是否正确接收到报文的唯一途径就是让receiver回复sender,这个回复只需要一个bit即可:0(NAK)代表接收失败,1(ACK)代表接收成功。
Retransmission
如果sender收到了NAK的回复,就会重新发送错误的报文。
该版本协议的工作原理如下:
sender:
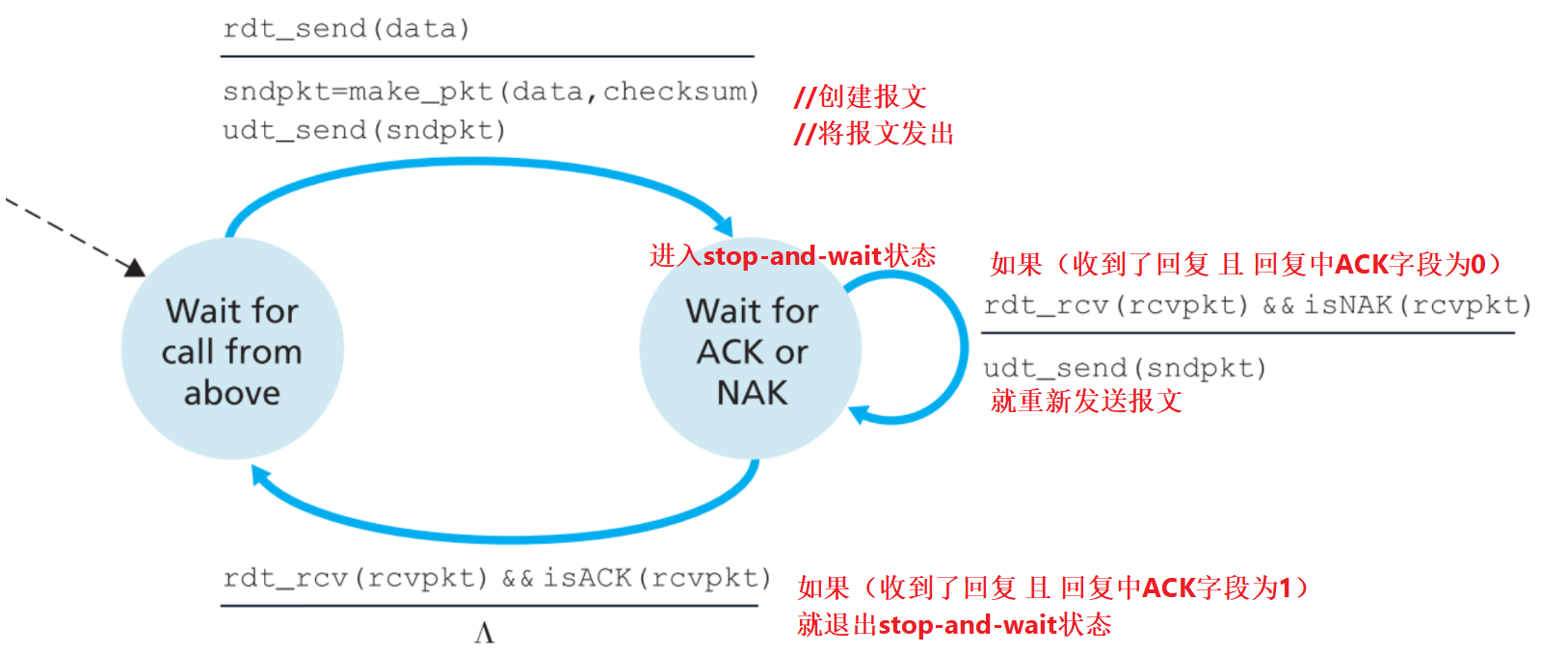
receiver:

要注意的是,sender在等待receiver回复期间是不会发送其他报文的,所以这种类型的协议又被称为 stop-and-wait protocols
到这里问题解决了吗?并没有,因为很有可能【代表ACK或者NAK的bit出错】。
一种简单的解决办法是,只要收到NAK就重新发送。但如果这个NAK原本是ACK的话(出现bit差错),就会出现 duplicate packets 。为了解决duplicate packets的问题,可以在报文中增加一个 sequence number 字段,这样一来receiver就可以根据这个序列号来判断刚刚接收到包是不是重复了(不重复则接收,重复则丢弃)。
如果出现原本回复的是NAK,但出现bit差错变为ACK这种问题,也因为采用序列号字段而被解决了,因为现在ACK要指明是几号报文,指定的不对就认为是NAK。
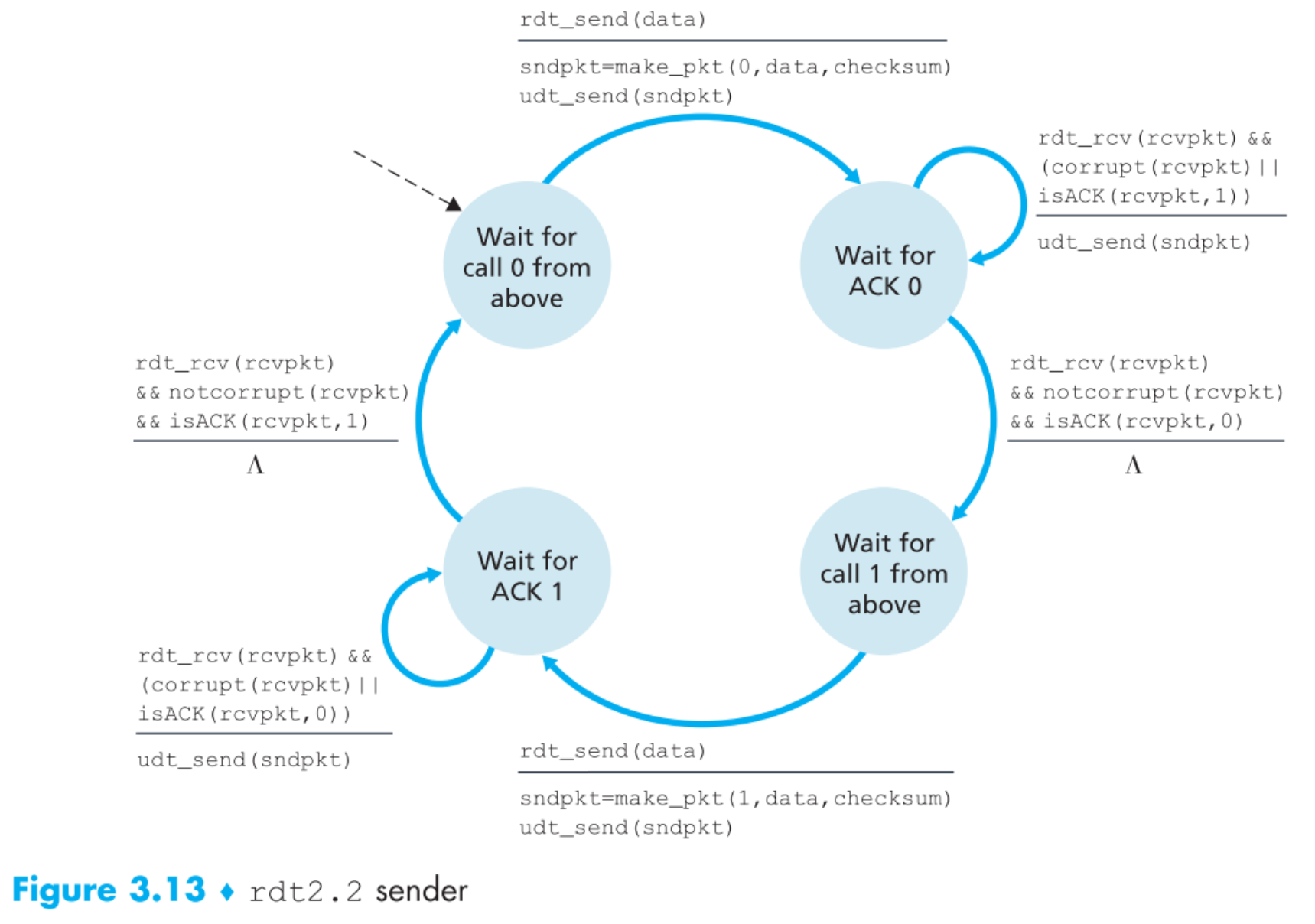
所以来看看2.1版本的工作原理:
假定只有0和1两种序列号的报文,且所有包都能【按序】到达接收端。
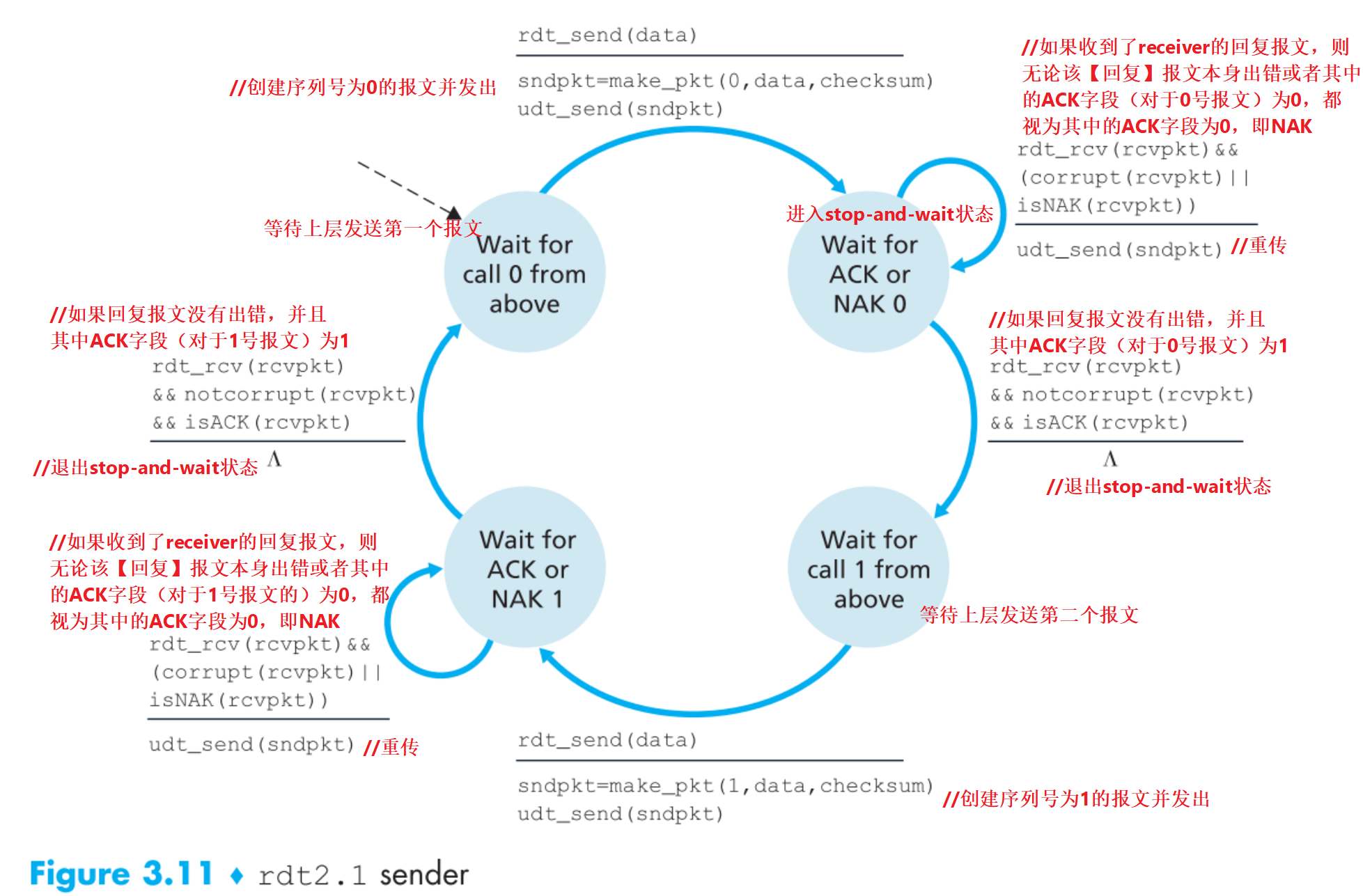
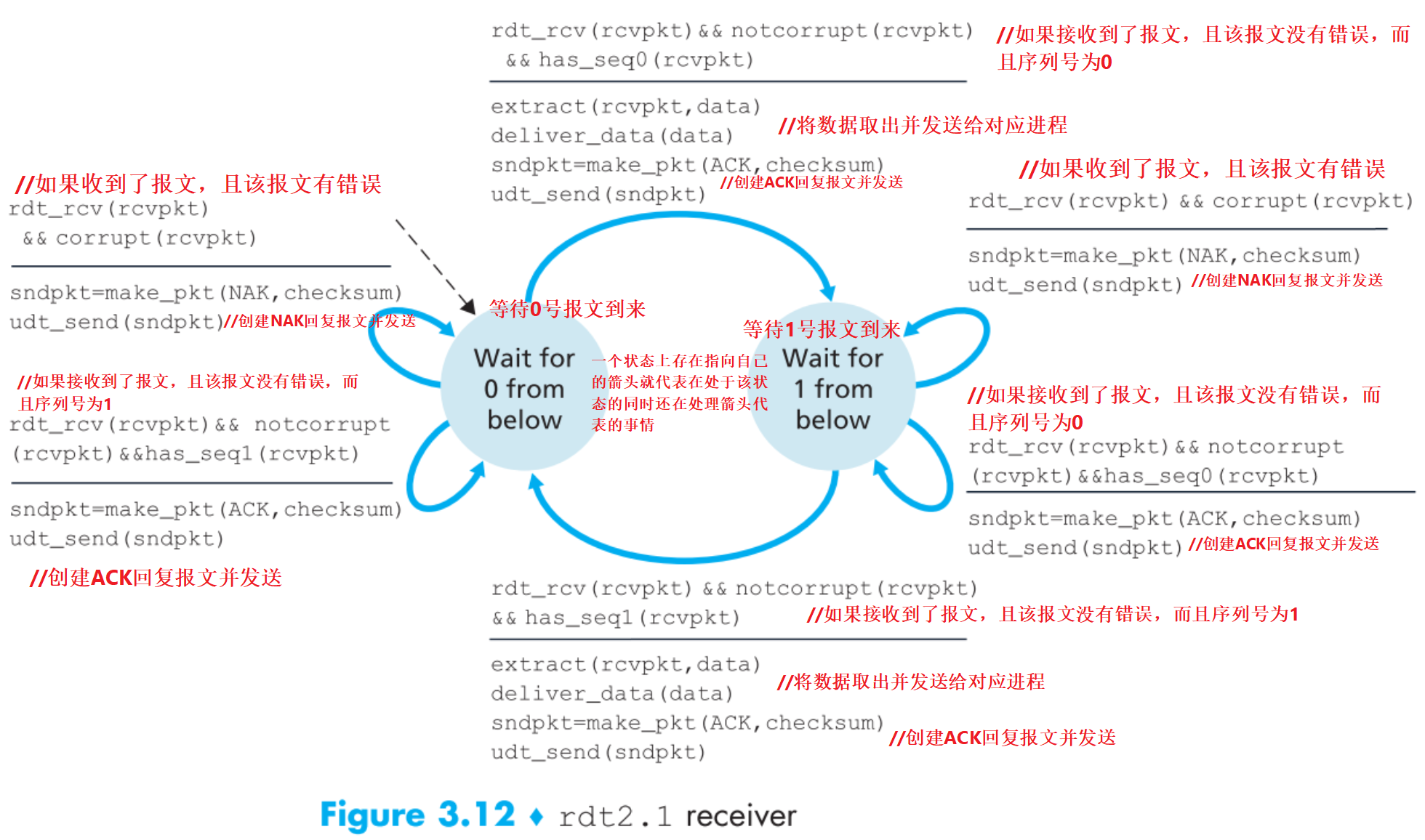
再做一个小升级到2.2,receiver发送的回复报文中明确指出了其ACK/NAK的报文序列号为多少,sender收到receiver的回复后要检查其ACK/NAK的是几号报文,再把FSM增加到用四个状态,这样描述整个原理更加清晰透彻,现在我们的2.0版本就圆满了。
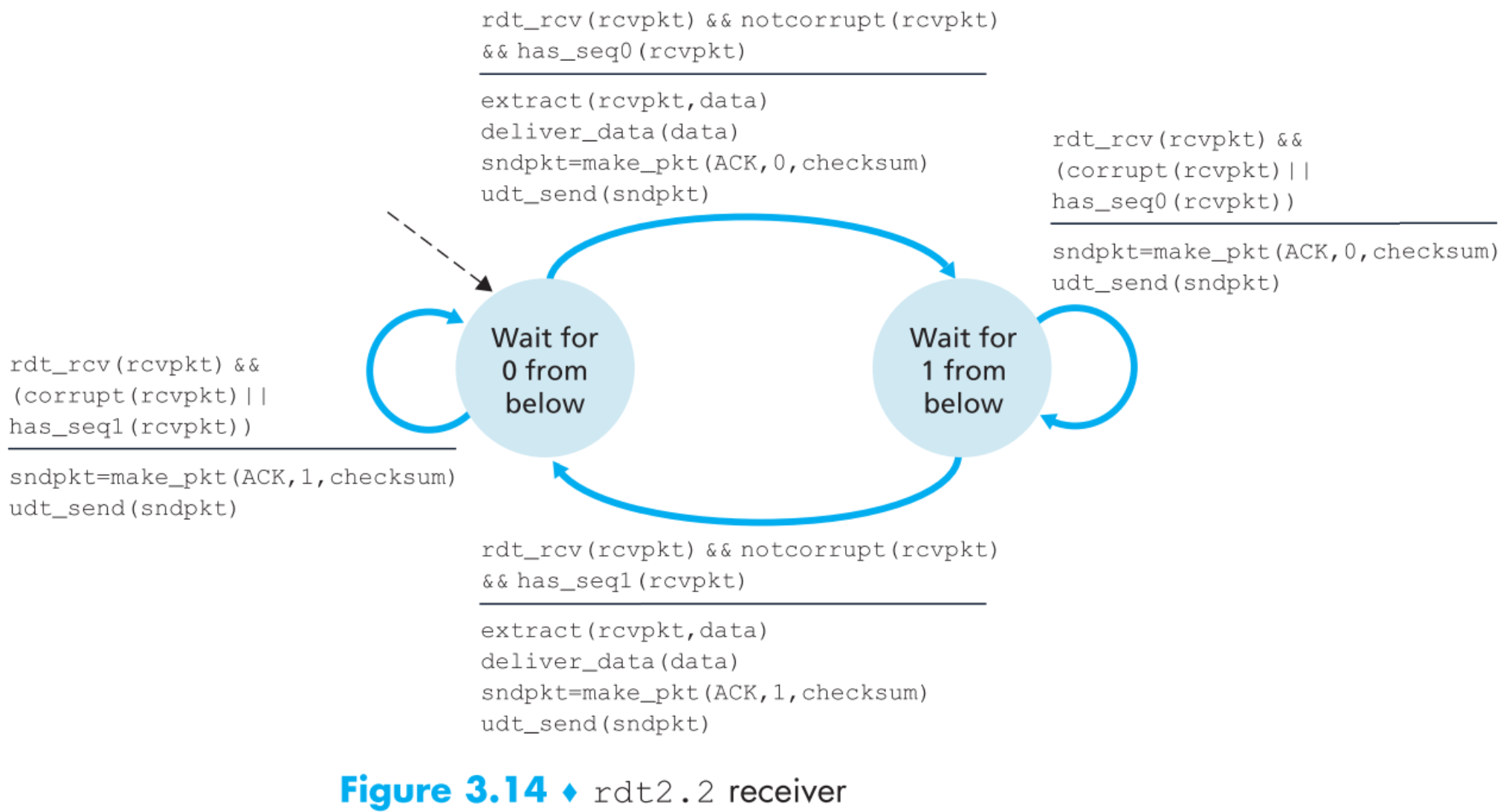
3.4.1.3 Reliable Data Transfer over a Lossy Channel with Bit Errors: rdt3.0
现在假定我们的传输信道不但可能产生bit错误,还可能丢包。
那么:
- 如何检测丢包
- 检测到丢包后应该进行什么动作
先讨论如何单独让sender这边处理这两个问题,无论是sender发出的包丢失还是receiver的ACK回复包丢失,效果都是sender收不到receiver的回复确认。那么只需要设置一个 countdown timer ,在规定时间内如果sender没有收到回复就重传。
但是有时可能网络比较差,一个包传输的时间过久超出了sender的规定时间,那么sender也会重传,这样就可能产生duplicate data packets,不过这个问题我们的2.2版本协议已经可以解决了。
现在来看看rdt3.0版本的FSM:
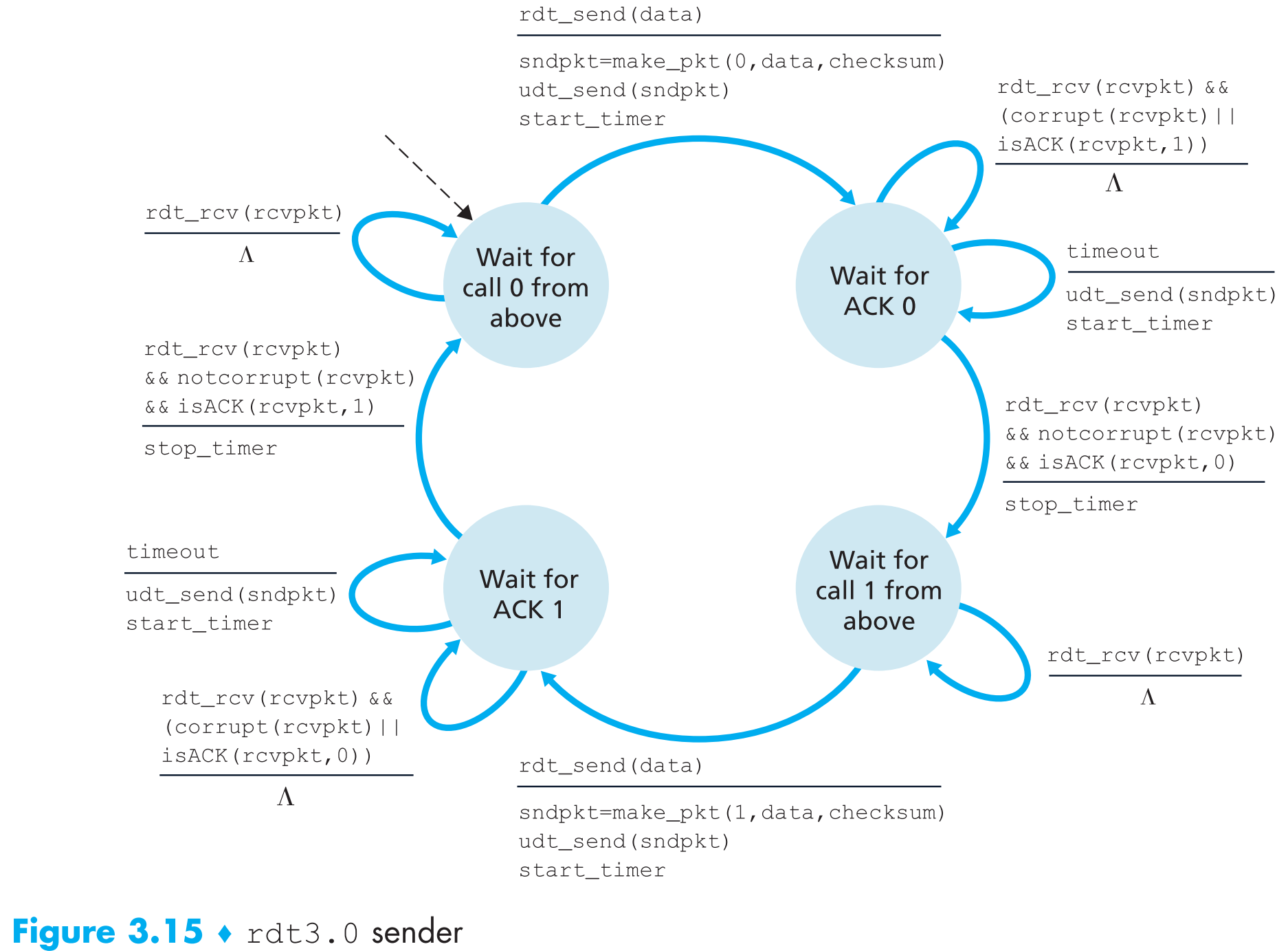
receiver端的FSM与之前的相同。
至此我们打造出了一个可以可靠传输的协议,它可以应对真实信道中可能出现的各种状况。
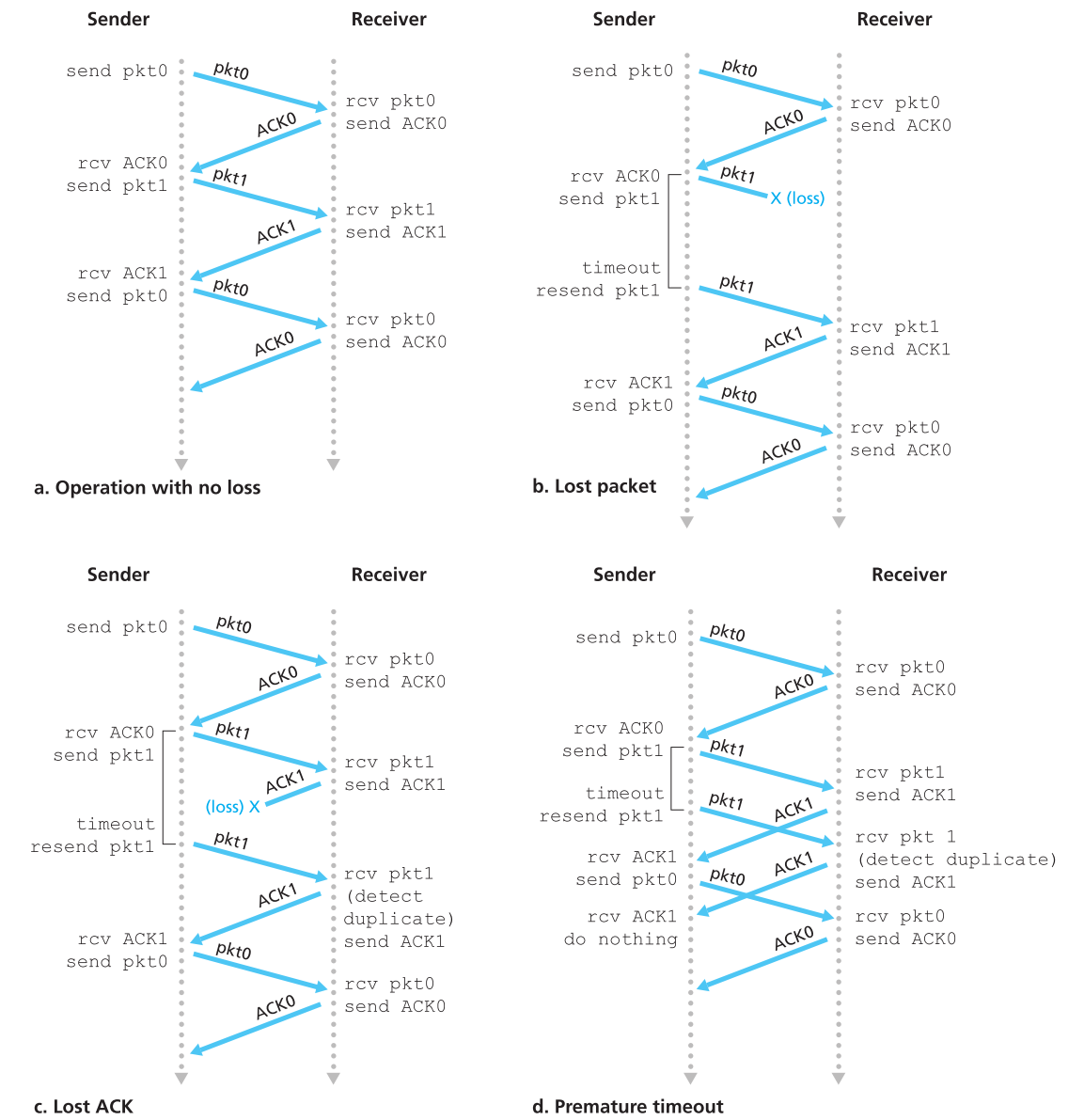
3.4.2 Pipelined Reliable Data Transfer Protocols
rdt3.0虽然实现可靠传输了,但究其根本是一个stop-and-wait协议,在如今巨量网络流量的情况下使用该协议的传输效率是无法被接受的。
我们可以使用pipeline技术在实现可靠传输的基础上提升传输效率。
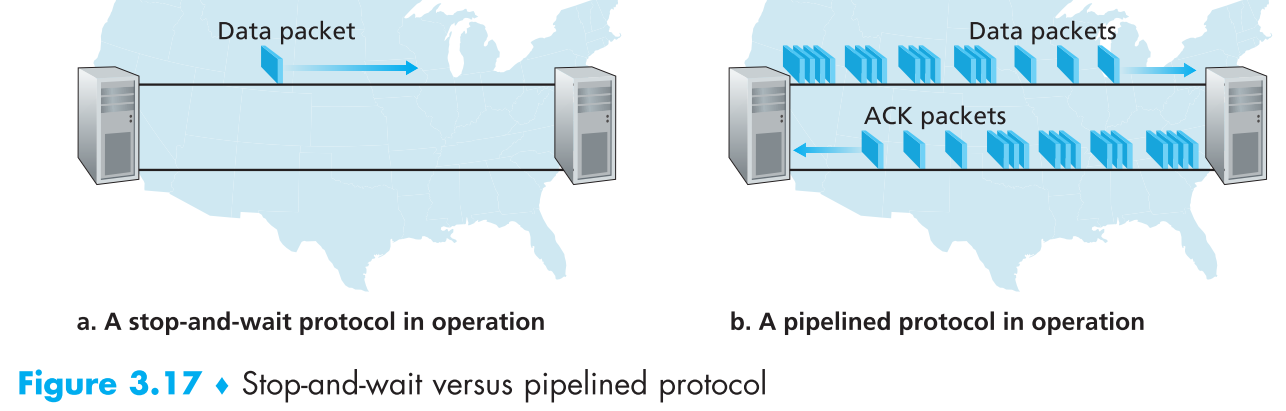
现假定sender在给receiver发包,仅仅使用停止等待协议(L为报文长度,R为发送速率)。
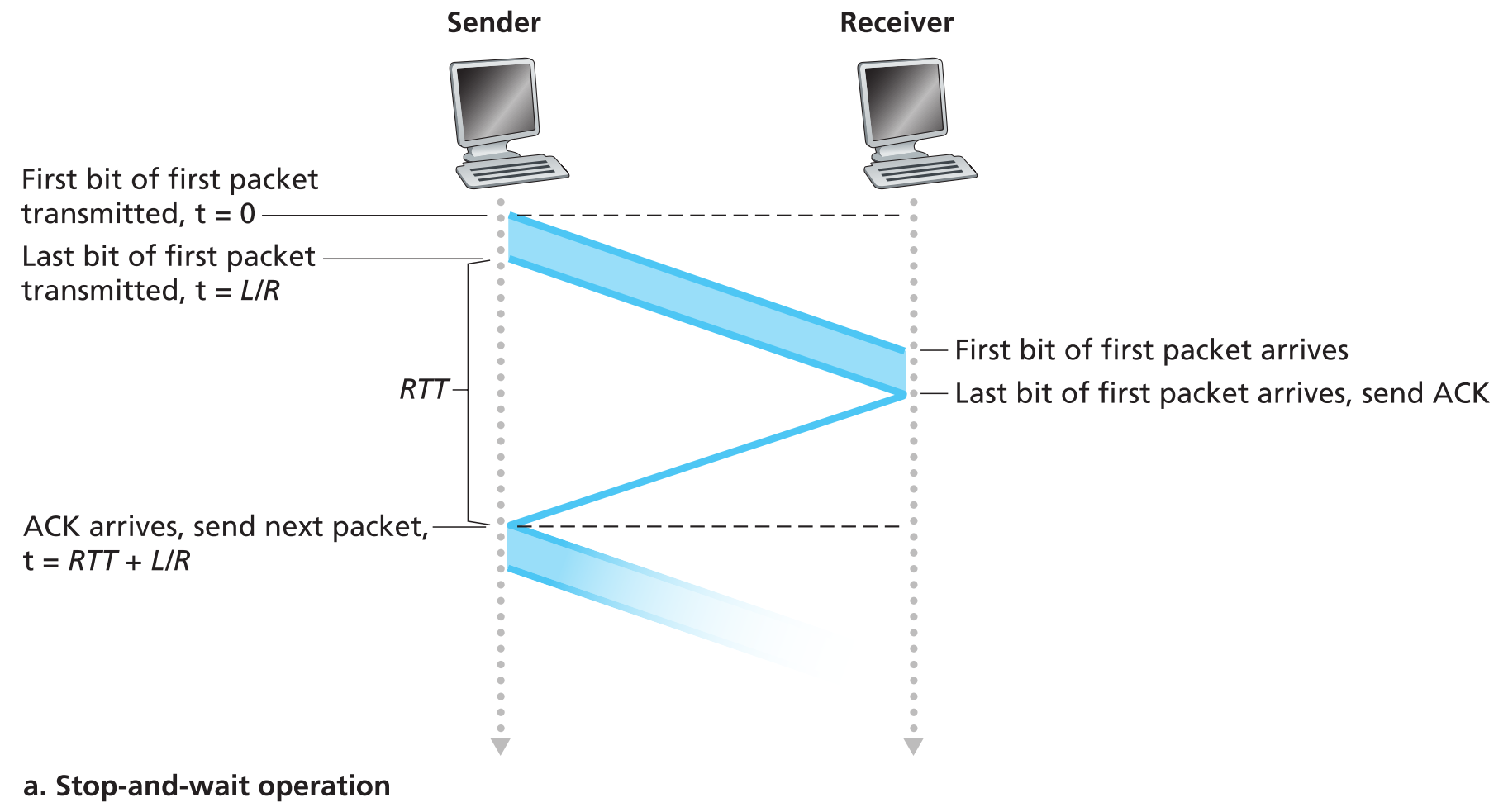
可以看出这种方式的信道利用率极低,stop-and-wait期间整个信道的资源完全是被浪费了。我们完全可以在一个RTT的时间内把空闲的信道利用起来,将停止-等待更改为: sender发出一个packet后可以不用等待这个packet的ACK回复就直接发送下一个packet 。这种技术就是 pipeline 。
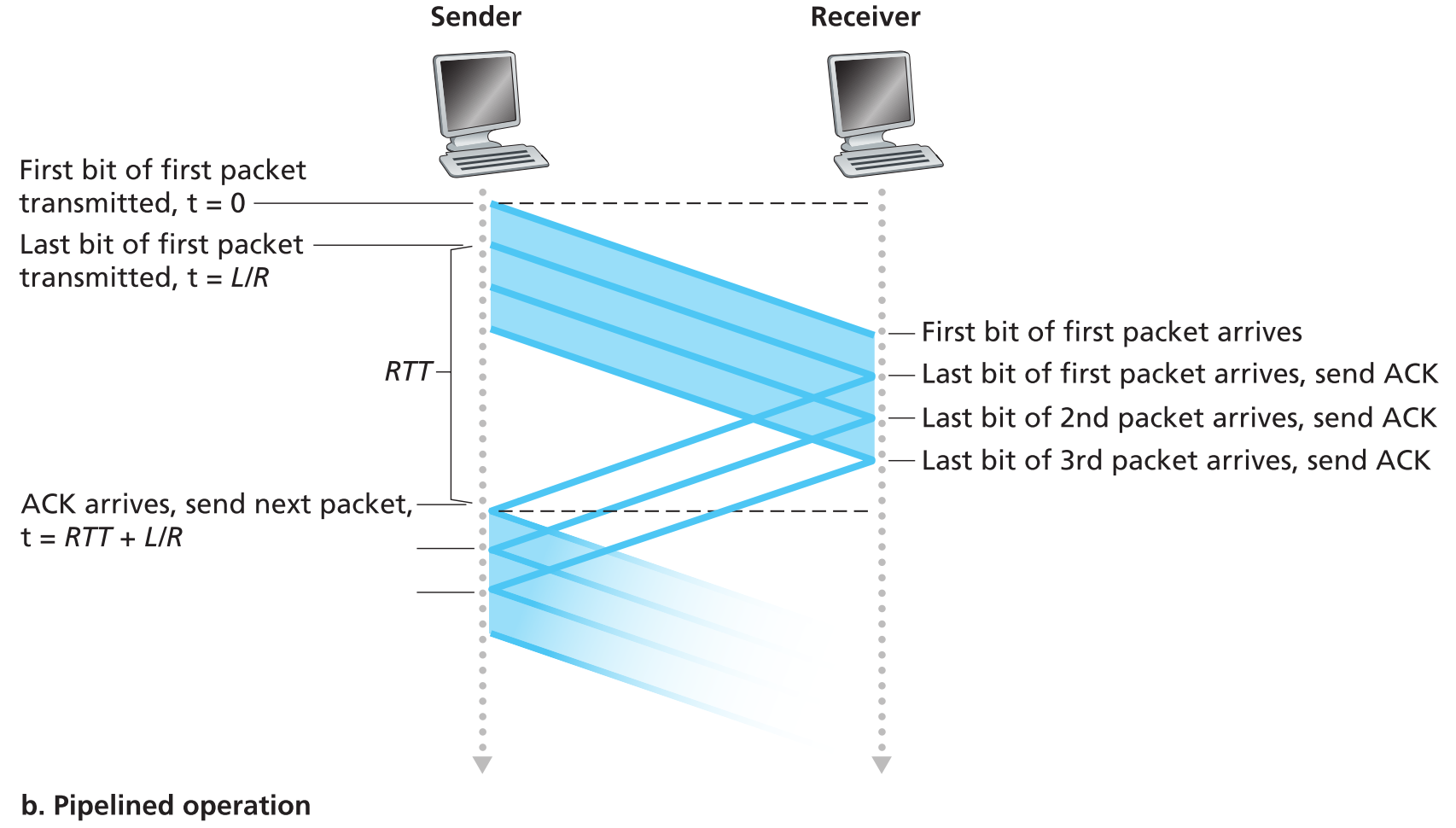
使用pipeline技术的可靠传输协议有如下要求:
- 发出的packet序列号必须递增,因为每一个运输途中的packet必须有独一无二的序列号,而且信道中可能同时存在多个正在传输的还没有被ACK的packets。
- sender和receiver的协议必须用buffer来存储多个packets。比如sender要存储已经发送出去的还没有被ACK的packets,receiver要存储已经正确接收到的packets(原因将在下面详细说明)
- 对付pipeline技术中的丢包、bit错误、重复包要使用新的协议:Go-Back-N或selective repeat
3.4.3 Go-Back-N (GBN)
GBN协议中sender可以发送多个packets而无需逐个等待receiver的ACK回复,但是该协议对【已发出但未得到ACK回复确认的packets数量有上限】要求——不超过N(窗口)。
我们定义 base 为【最早发出的但还没有得到ACK回复的packet】的序列号, nextseqnum 为最小的还未使用的序列号,这样就可以把sender视角的序列号集合分成4个部分。
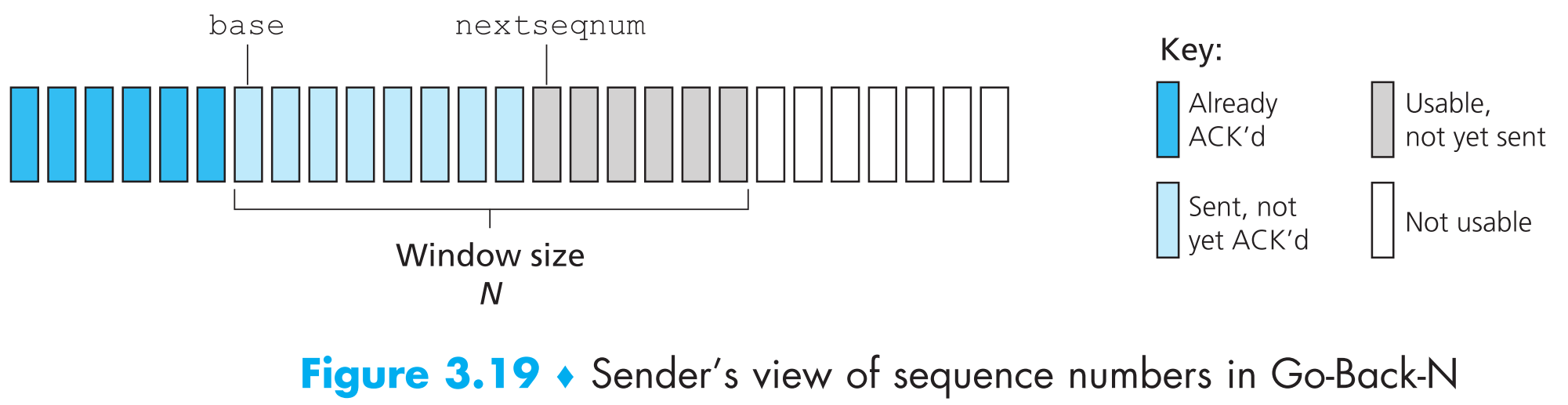
序列号base+N只有等到序列号为base的packet被ACK后才能被使用(即窗口右移)。所有未得到ACK确认的且可以使用的序列号组成了一个大小为N的窗口,这个窗口会不断的向右滑动,因为这个特点,GBN协议也被称为 sliding-window protocol 。
为什么要设置一个上限N,让窗口大小无限不是更方便吗?有两个原因:1. flow control,2. congestion control。原理将在之后详细说明。
事实上,序列号在现实情况下是packet头部的一个字段,假如该字段有k个bits,那么序列号的范围就是$[0, 2^k-1]$ ,并且该范围是以“环”的方式存在的,也就是$2^k-1$ 的下一个序列号是0。
TCP报文的序列号字段为32-bit
GBN sender必须要处理三种类型的事件:
- 上层调用
当上层调用rdt_send()时,sender会首先检查窗口是否已满(nextseqnum>=base+N ?),如果已满,就会拒绝上层的发包请求,上层收到该拒绝信号后过一会重新发包。
真实情况下,sender在window已满的情况下要么会把上层新传来的packet存到buffer中;要么会与上层之间通过同步机制相互通信(比如semaphore),这样上层可以知道当前窗口情况,如果已经满了就不会把数据下发。
- 接收ACK回复
GBN协议中receiver采用 cumulative acknowledgment 的方式发送ACK回复报文,即receiver发送的【ACK n】代表[0, n]已经全部正确收到了。
- 倒计时
每当一个倒计时timer触发时,sender会重新发送【所有】之前已发送但是还没有被确认的packets。只要窗口中存在发出但没有收到ACK回复的packets,timer就会启动,如果没有,timer就会停止。
GBN receiver必须要处理的事件:
如果正确接收到一个序列号为n的packet,且这个packet的按序到达(依据是上一个到达的packet序列号为n-1),receiver就会发送ACK n给sender。除此之外出现其他任意情况,receiver就会丢弃当前到达的packet,并且重新发送ACK k(k为最近正确接收且按序到达的packet的序列号)。
这样就可以保证如果正确接收到n号packet,那么[0, n-1]必定也都正确接收到了,这种情况下累计确认是一种很自然的选择。
窗口大小为4时GBN过程示例:
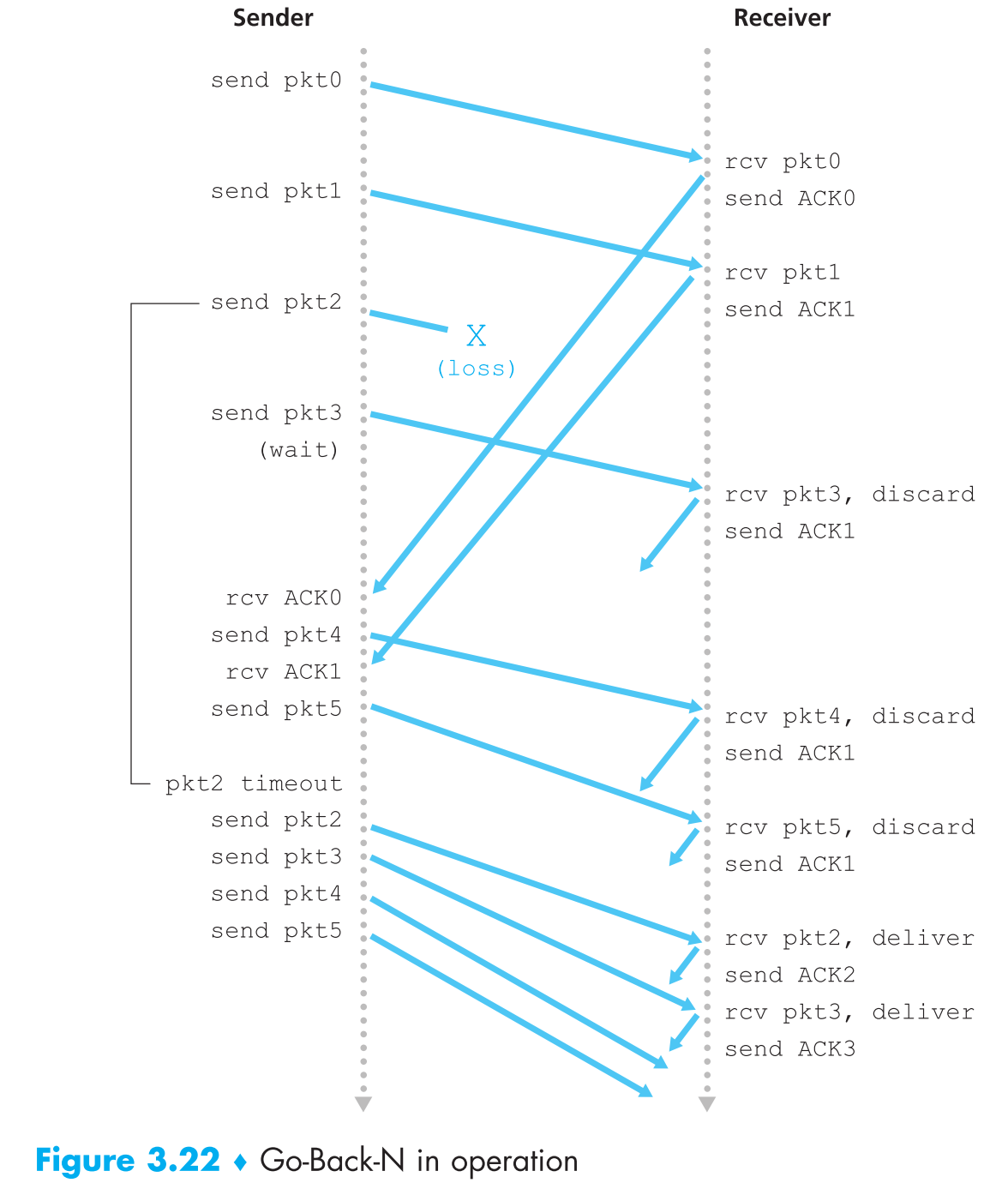
3.4.4 Selective Repeat (SR)
当windows size和网络带宽时延都很大时,pipeline中可能同时存在很多个发送中的packets,如果使用GBN协议,这些packets中只要有一个packet出现错误就可能会引发很多个packets的重传(然而其中大部分可能都是完好的packets)。这个信道出现bit传输错误的概率越高,这种不必要的大规模packets重传的概率就越高,因此必须对这种情况做一些优化,selective-repeat 协议就是来避免这个问题的,它可以使得sender可以仅仅重传那部分有错误的packets。
SR中sender的窗口中也会有一部分已经被ACK的报文,只有等到从send_base开始几个连续序列号的packets都被ACK后,窗口才会移动,且一次性跨越几个连续的序列号。
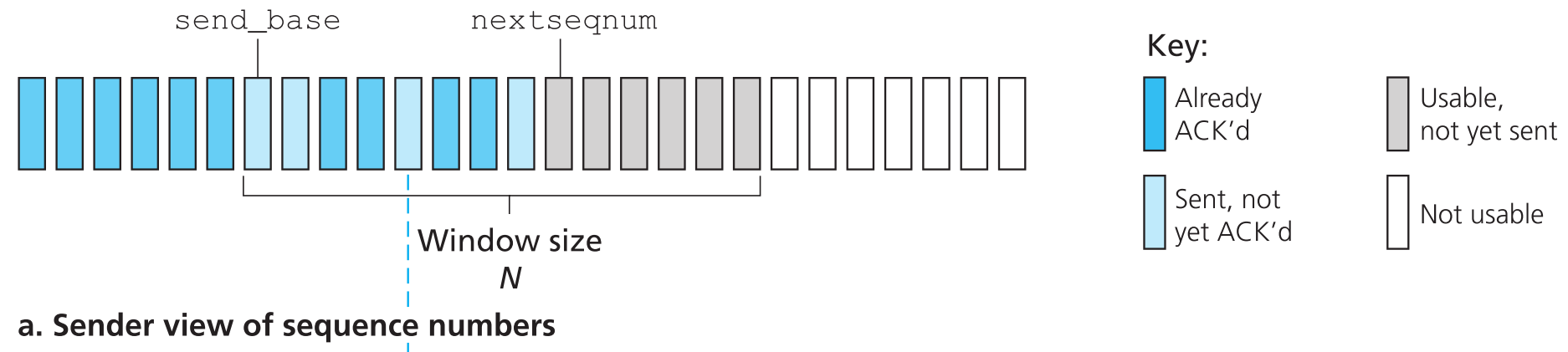
SR中的receiver会逐个ACK正确收到的packets,【无论这个packet是否按序到达】。顺序错乱的packet会先被buffer起来,等到缺失的packets(序列号从已经正确按序收到的最大序列号packet到顺序错乱packet之间所有的packets)正确收到后,这一组序列号连续的packets才会被上传到应用层。
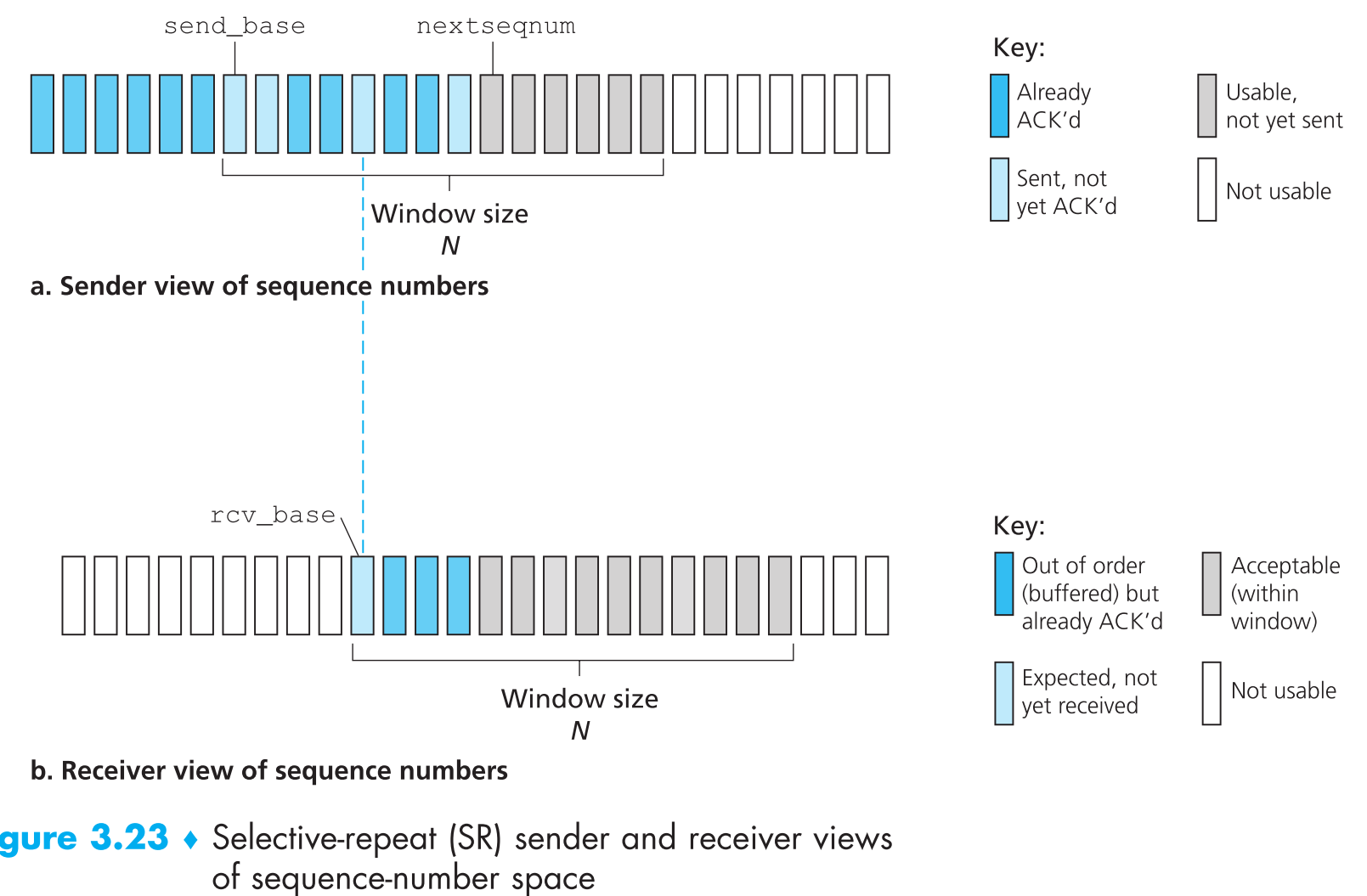
具体来看,SR中sender对下面三种events的动作:
- Data received from above。收到上层的数据后,SR sender会先搜索下一个可用的序列号,如果这个序列号在窗口内,就将数据打包后发出;如果不在窗口内,就把数据存入buffer或者把它返还给上层,让上层过一会再发送。
- Timeout。超时重传机制,依然用来防止丢包。不过现在要为每一个packet设置一个逻辑timer了(实现中只需用一个物理timer就可以模拟出很多逻辑timers)。
- ACK received。如果接收到ACK,SR sender就会把该ACK指定的packet标记为已成功发送,并【把它放在窗口内】。如果这个packet的序列号等于send_base(意味着和前面已ACK的packets序列号接上了),那么窗口就会右移(send_base移动到序列号最小的已发出但还未收到ACK的报文对应的序列号处),移动时当然会有新的序列号加入窗口,如果这时sender buffer中有待发送的packets,就会把新的序列号赋予给这些packets然后发出。
SR中receiver对下面三种evernts的动作:
注意乱序到达receiver的packets都会被存到buffer中
Packet with sequence number in [rcv_base, rcv_base+N-1] is correctly received.
这种情况下刚刚到达的packet序列号落在了receiver的窗口内,receiver会将这个packet的ACK报文回复给sender。如果这个packet的序列号不等于receiver窗口的rcv_base,则receiver会将它存入buffer(里面存的都是乱序的packets),如果这个packet的序列号等于receiver窗口的rcv_base,则这个packet和所有之前buffer了的且序列号连续的packet(从rcv_base开始)都会被移交到应用层,这次被移动到应用层的packet有多少,窗口就会右移多少步
Packet with sequence number in [rcv_base-N, rcv_base-1] is correctly received.
即使之前已经收到这个packet且已经将ACK回复给sender,现在也还要再生成一次ACK回复给sender。为什么会收到之前已经ACK过的packet?可能的原因是之前的ACK回复报文丢包了,sender启动了超时重传。所以在这种情况下必须要再次回复一个ACK给sender
Otherwise。丢弃到来的packet。
下面来看下使用SR协议通信的具体过程:
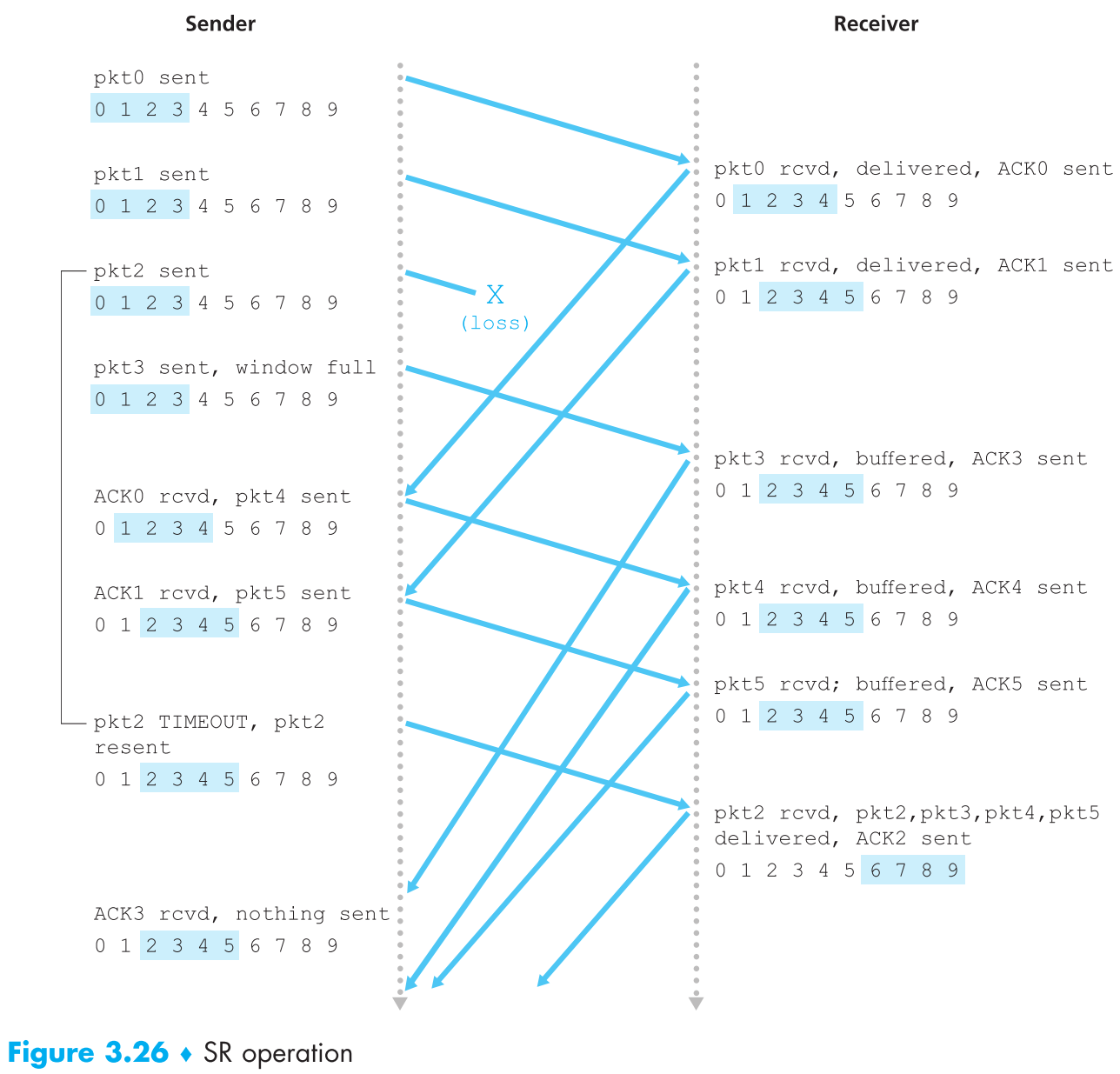
对比sender和receiver来看,有一点很重要,就是【它们看不到彼此的窗口】,那么在现实中序列号是个“环”,很可能出现以下情况:
case 1:到底是新的packet还是重传的packet?
图a的0号packet是重传的,而图b的0号packet的新的。可是receiver完全无法分辨。

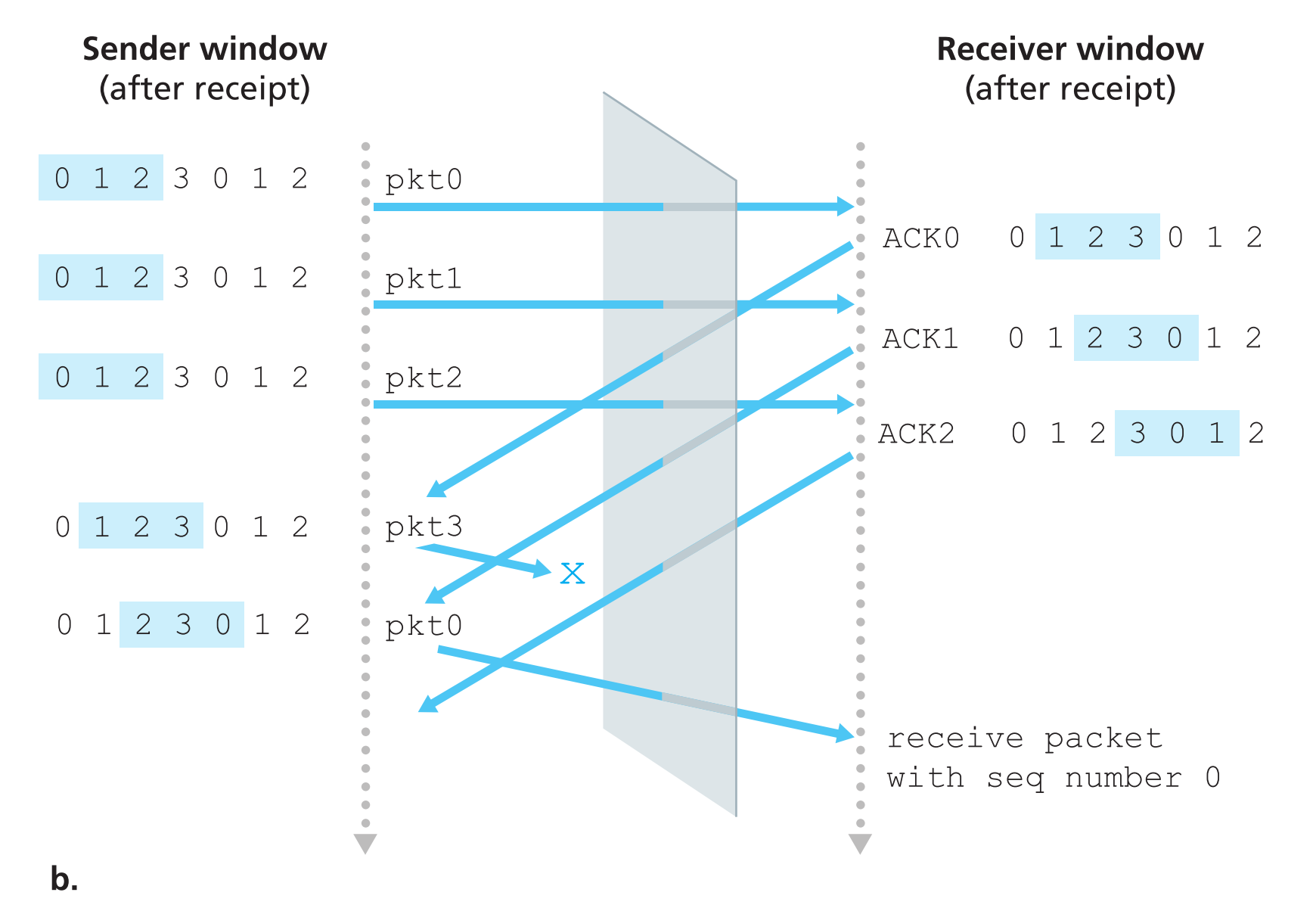
所以在SR协议中令【窗口大小=序列号空间大小-1】是不可行的,那么窗口大小应该设置为多大比较合适呢?
直接给出结论:采用了SR的可靠传输协议,其窗口大小必须小于等于序列号空间(sequence number space)大小的一半 ;而采用GBN的可靠传输协议,其窗口大小可以等于序列号空间大小-1。想想为啥?
最后,我们之前的所有的讨论都建立在packets在【传输过程中】不会出现顺序错乱,现实情况中当两hosts之间仅仅用一条线缆连接时,这样的假设是正确的。不过,因为我们学习的是互联网,所以两hosts之间几乎不可能只用一条线缆相连,这时就可能发生packets传输过程中的顺序错乱,那就很可能存在一个传输时间非常久的packet在信道中游荡(不断的因为顺序错乱而延后),虽然可能马上就到达receiver处,但它既不在sender的窗口中,也不在receiver的窗口中,但是!它的序列号可能刚好就和receiver所期望的packet的序列号重叠。
想要避免这个问题,就必须保证序列号x在通信双方的逻辑信道中消失之前不被再次使用,现实中使用的方法是给每一个packet设置一个TTL(通常为3分钟),把滞留在信道中过久的packet销毁。
note:通信双方组成一条逻辑信道,其中可能包括很多段物理信道,不同的逻辑信道使用不同的序列号空间。因为即使它们中途有某几段物理信道被其他hosts共用,也可通过其他标识(ip地址,端口号)来逻辑上区分。
3.5 Connection-Oriented Transport: TCP
3.5.1 The TCP Connection
TCP是【connection-oriented】,因为两个进程通过TCP互相通信之前,必须要先相互【握手】——即发送一些segments,里面包含用于建立TCP连接的参数。
TCP连接并不同于端到端的电路交换,它实际上是一种逻辑上的连接(通信双方保存有公共的状态字)。因为传输层协议只在end system上运行,所以路由设备(路由器、交换机等)不负责维护TCP的连接状态,事实上,路由设备根本不知道有TCP connection这回事,它们仅仅能够看到的是datagrams。
TCP连接提供 full-duplex service (类似于手机的通信方式,通信双方可以同时接听或者说话),而且TCP连接总是【点对点】的——只能一个sender和一个receiver之间通过TCP相连。
现在来看看TCP连接建立的具体过程,假定一台host上某进程(client)想要与网络中另外一台host上某进程(server)建立TCP连接
client进程首先要通知本host上的传输层:我想要与另一台机器上的server进程建立连接,然后把serverName和serverPort传给传输层。
client传输层先发送一个特殊的TCP segment给server,server收到后回复一个特殊的segment,然后client再发送一个特殊的segment。前两个segment中不携带任何的payload,第三个可能携带payload,这整个第2步被称为 three-way handshake
步骤2正确结束后client和server之间的TCP连接就建立好了,现在它们之间可以互相发送数据了,假定现在client向server发送数据
数据从client host这边的socket发出后,它的走向就完全被client这边的TCP所控制了。TCP首先将数据放入 send buffer 中,然后每过一段时间(不固定)就从该buffer中取一些数据(最大值为MSS maximum segment size)封装起来往下层(网络层)发送。
note:MSS的大小取决于链路层MTU(maximum transmission unit)的值,必须让TCP segment payload(MSS)+TCP segment header+IP header的长度小于MTU,即让数据包最终能够被放到frame中在数据链路层发送。现在Ethernet和PPP这两个链路层协议的MTU都为1500 bytes,所以MSS的值一般为1460 bytes。
注意MSS仅仅是payload的大小,不包括segment header和IP header。
TCP每次从send buffer中取出数据后,都会给这些数据加上一个TCP header,使之整体被封装成 TCP segment ,发送到网络层,网络层又会再对TCP segment封装一次,组成 IP datagram ,最终被发送到网络中。
当TCP receiver接收到TCP segment时,会先解封装,然后将其中的payload存到receive buffer中,接着对应的应用程序就可以从这个buffer中读取数据流了
3.5.2 TCP Segment Structure
TCP传输一个大文件前通常会先把它拆分成很多块,每块大小(除了最后一块)一般等于MSS。
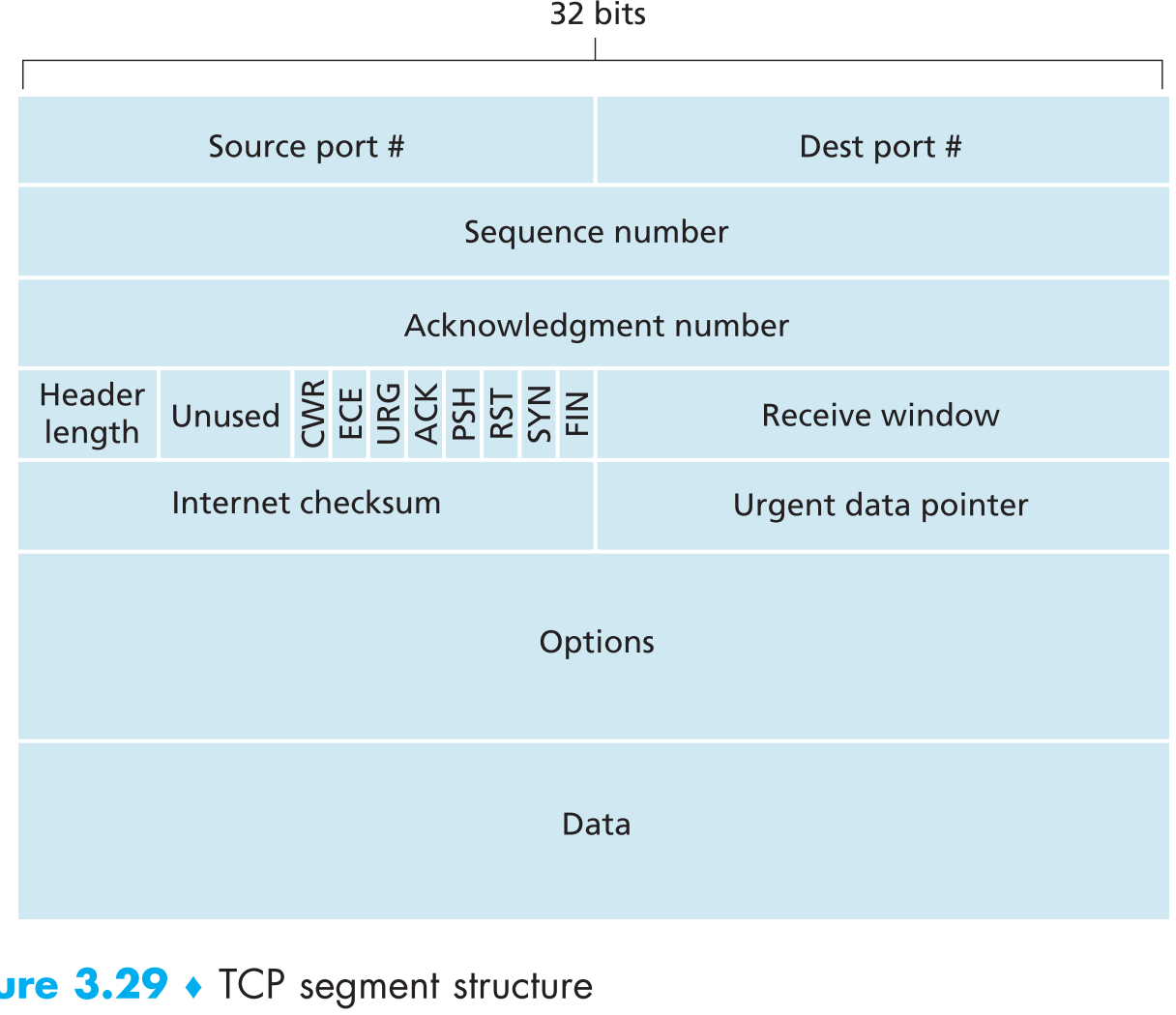
TCP与UDP有一些相同的字段:目标/源端口号,校验码。其他字段则是TCP独有的:
- 32-bit的 sequence number 和32-bit的 acknowledgment number 用来实现可靠数据传输服务。
- 16-bit的 receive window 用于数据流控制,该字段说明了receiver “愿意”接收多少bytes的数据
- 4-bit的 header length 说明了TCP header的长度。因为TCP有一些可选字段,所以它的header length是可变的
- option 字段是当sender和receiver协商MSS时,或者高速网络中调整窗口大小变动因子时使用的。
- 6-bit的 flag 字段。其中 ACK bit ,当segment是ACK回复时才用到,标识刚才的segment是否接收成功;RSY, SYN, FIN bits是用来启动或者关闭TCP连接的,后面会说到;CWR, ECE 用来通知链路拥塞;PSH 为1时receiver收到该segment会立即将它转交到上层;URG 若为1,代表该segment中携带的payload被发送端标识为 “加急件”,这段payload的最后一个byte所在位置保存在16-bit的 urgent data pointer字段中,receiver接收到URG为1的segment时,TCP必须要通知接收端的应用层并将urgent data pointer作为参数传递。
note:现实情况中PSH,URG和urgent data pointer几乎不会被用到。
3.5.2.1 Sequence Numbers and Acknowledgment Numbers
从TCP的视角来看,数据都是没有结构但有序的比特流,所以序列号究其根本标识是具体的某个byte而非segments(每一个byte都有自己的序列号),因此【segment的序列号这个说法】实际上是这个segment代表的比特流中第一个byte的编号。
再看看确认号,【A发送给B的segment中包含的确认号是A期望收到B的下一个byte的序列号】。举两个例子,假定MSS=1000:
假如A已经收到B的序列号为0~535的所有bytes,且A准备发给B一个新的segment,因为A下一个期望收到的byte序列号为536,所以A会先把acknowledgement number=536写入到要发出的segment中,再发出。
假如A已经收到B的两个segments,一个包含了序列号为0
535的所有bytes,另一个包含了序列号为9001000的所有bytes,因为某些原因没有收到536~899的bytes。所以现在A期望收到序列号536开头的bytes,因此A发送给B的下一个segment中会包含确认号536,因为TCP只会确认【第一个missing byte】之前的所有bytes,这种特性叫做 cumulative acknowledgments。这一点符合GBN协议的特征。
第二个例子中隐含了一个问题,TCP协议中receiver如何处理乱序到达的segments?RFCs中并没有明确规定,因此程序员可以定制处理方法,一般来说有两种处理方法:
- receiver直接丢弃乱序到达的segment,这样的话代码比较好写。
- receiver将乱序的segments存入buffer,等到收完缺失的所有segments后一并上交到上层。这种方案是现实中被广泛采用的,因为第1种方案太“浪费”,尤其在如今的网络流量下。这种方案符合SR协议的特性。
note:现实中,刚开始通信时,初始的序列号并不是0而是随机选取的,这样做的目的是为了安全。
3.5.2.2 Telnet: A Case Study for Sequence and Acknowledgment Numbers
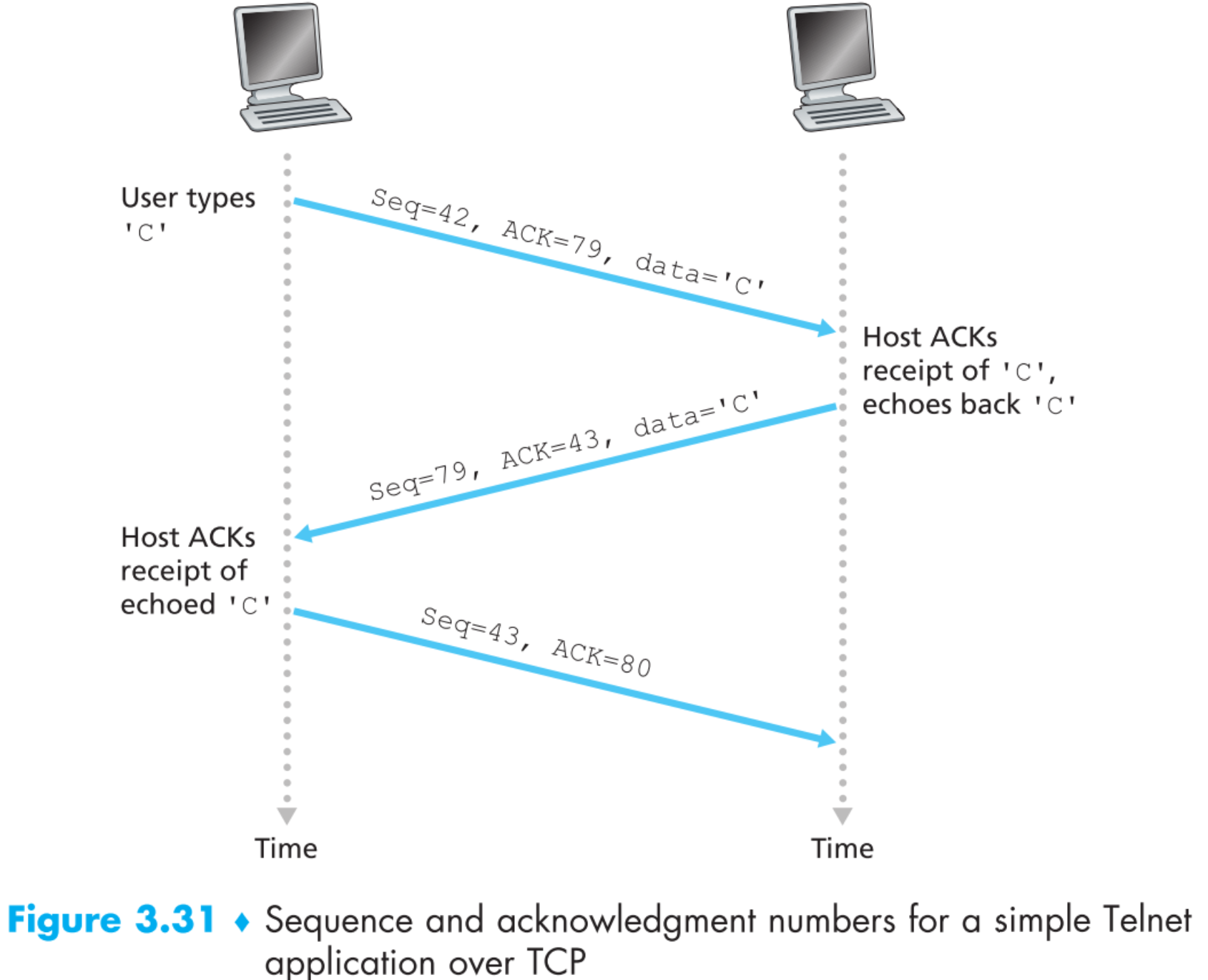
Telnet是一种典型的使用TCP作为传输层协议的应用层协议,现在我们来通过学习Telnet加深对序列号的理解。下面假定A对B发起Telnet session,因为是A发起的通信,所以A是client,B是server。A在telnet终端中输入的每一个字符都会被传输到B处,然后B又会把这些字符原封不动的再回传给A,目的是告诉A这些字符我已经成功收到并处理了。
现在假定A仅仅在telnet终端上输入了一个大写的字母 ‘C’然后回车发送给B,并假定client发出的segment序列号从42开始,server发出的segment序列号从79开始,因此在发送任何数据之前,server的确认号为42,client的确认号为79,下图为通信的过程
3.5.3 Round-Trip Time Estimation and Timeout
TCP和我们之前自创的rdt协议一样拥有超时重传机制来应对丢包的情况。超时重传机制看起来简单,但其实实现起来有非常多的细节需要考虑。
- 重传的时间间隔为多少?
肯定要大于当前连接的round-trip time(RTT),RTT为【从sender发出segment开始,到sender接收完毕receiver的ACK segment结束】这一段时间,否则就会产生不必要的重复包。现在问题在于,应该比RTT大多少呢?
传输开始时终端如何计算RTT?
是否要为每一个segment设置一个timer?
3.5.3.1 Estimating the Round-Trip Time
TCP是如何计算RTT的呢?
方法是,每隔一段时间测量一个segment(非重传)的RTT,称之为SampleRTT。但是显然如果将SampleRTT作为接下来一段时间所有segments的预计RTT是不合适的,因为在不同情况下SampleRTT的数值波动可能较大(比如不同的拥塞情况)。为了让预计的RTT更加精确,会对SampleRTT做一个类似取均值的操作,其结果称为EstimatedRTT,TCP会将这个EstimatedRTT作为接下来一段时间内所有segments的预计RTT,它的计算公式如下:
$$
EstimatedRTT = (1-\alpha) \cdot EstimatedRTT+\alpha\cdot SampleRTT
$$
一般α取值为0.125,所以上式为:
$$
EstimatedRTT = 0.875 \cdot EstimatedRTT+0.125\cdot SampleRTT
$$
可以看出随着时间流逝,越早计算的SampleRTT在预测中的重要程度会越来越低,EstimatedRTT的数值会越来越稳定在某一个区间内。在统计学里面,这种类型的均值叫做exponential weighted moving average(EWMA),exponential在上式中指带某一个SampleRTT的重要度会随着时间流逝呈指数级的衰减。
另外还可以用公式刻画RTT的波动程度(SampleRTT偏离EstimatedRTT的程度):
$$
DevRTT = (1-\beta)\cdot DevRTT+\beta\cdot|SampleRTT-EstimatedRTT|
$$
一般β取0.25,如果波动程度大,DevRTT就会比较大。

3.5.3.2 Setting and Managing the Retransmission Timeout Interval
显然TimeoutInterval必须大于EstimatedRTT,否则就会产生很多不必要的重传。但是也不能过大,否则如果丢包,就会产生较大的延迟(想想为啥?)。
TCP采取的策略是:如果DevRTT比较大(即SampleRTT偏离EstimatedRTT的程度较大),TimeoutInterval就应该比EstimatedRTT【大多一点】;如果DevRTT较小,则TimeoutInterval就应该比EstimatedRTT【大少一点】,也就是说,TimeoutInterval比EstimatedRTT大多少是由DevRTT决定的。公式如下:
$$
TimeoutInterval = EstimatedRTT + 4\cdot DevRTT
$$
现实情况下,TimeoutInterval的初值一般为1s。
是否要为每一个segment设置一个timer?那样timer management的开销太大,RFC推荐即使存在多个已发出但还未被确认的segments,也仅仅使用一个 retransmission timer ,只要有已发出但未ACK的segment,timer就正常工作,没有则停止。
3.5.4 Reliable Data Transfer
IP协议是不可靠的,路由器的receiving buffer满了之后到来的datagrams可能统统被丢弃;datagrams可能乱序到达路由器;datagrams中的bits也可能出现错误。然而segments最终必须要被下发到网络层作为datagrams在网络中传输,那么TCP是如何让segments避免datagram可能遇到的这些问题,实现可靠传输的呢?
假定A通过TCP连接向B发送一个大文件,且TCP sender只使用一个timer来完成超时重传的功能,且这个timer总是为已发出的还未ACK的【序列号最小,即最早发出的】segment计时。
TCP sender伪代码:
1 | /* Assume sender is not constrained by TCP flow or |
对于这个简单版的TCP sender,我们来看看累计确认减少不必要重传的两个情况:
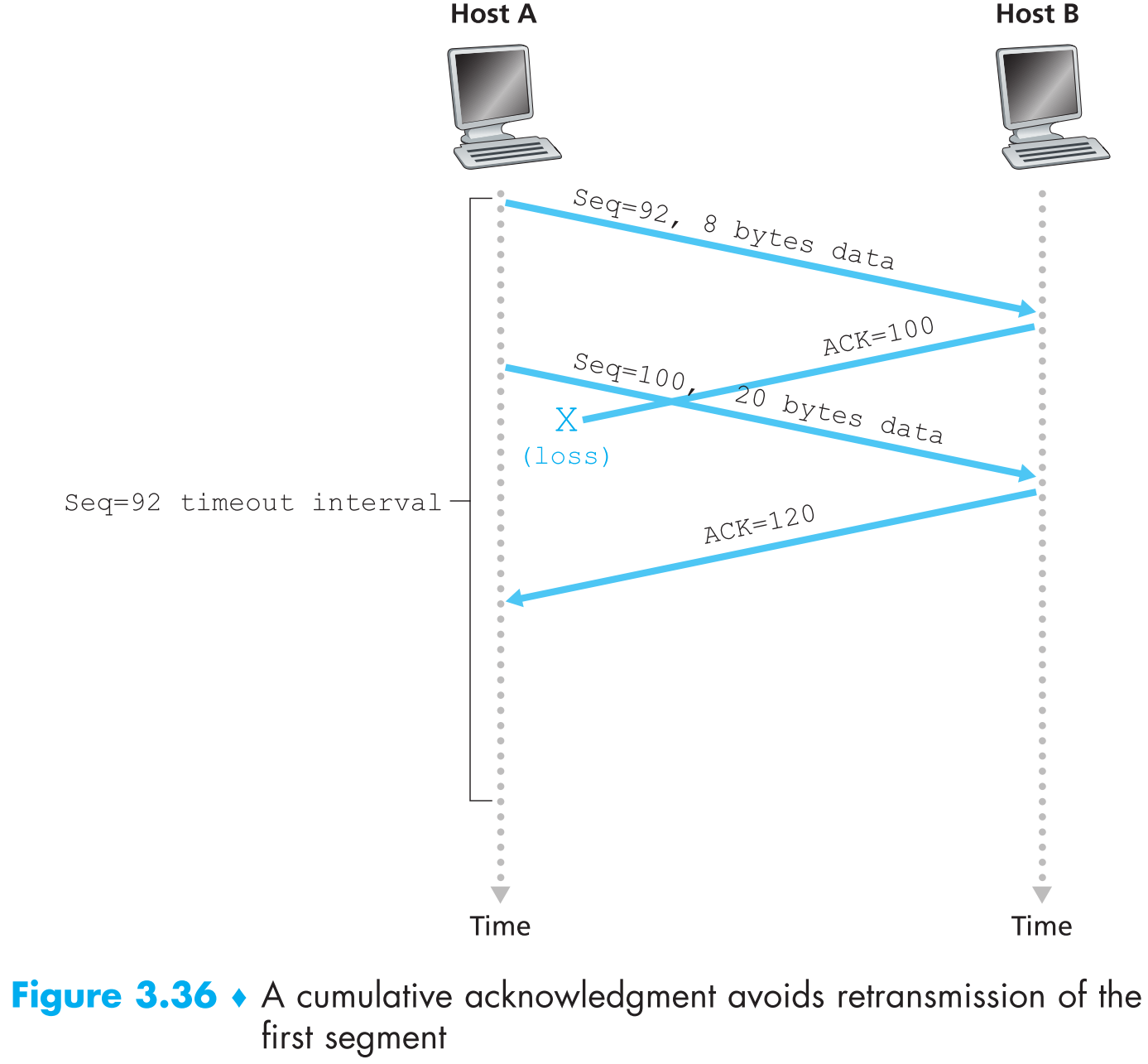
假设A连续发送两个segments给B,第一个segment序列号为92携带8 bytes payload,第二个segment序列号为100携带20 bytes payload。它们两个都无差错的传输到了B,B接收后分别回复两个ACK给A,第一个ACK=100,第二个ACK=120,现在假设这两个ACK segments都在当前timeout之后才到达A。timeout时,A会重传第一个序列号为92的segment并且重启timer,如果第二个segment的ACK在重启后的timeout之前到达了A,那么第二个segment就不会被重传。
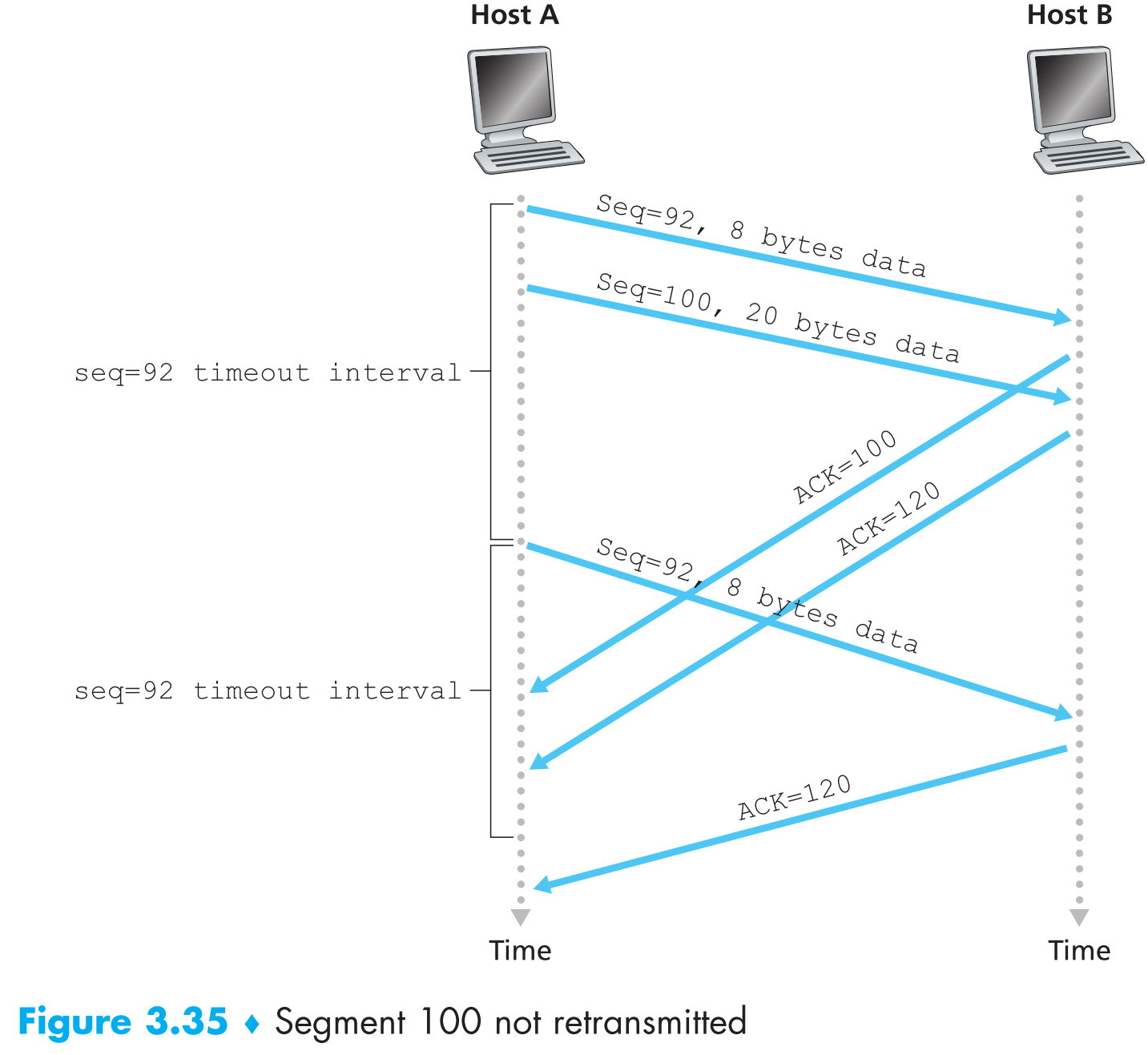
背景和上一个例子相同,结果第一个segment的ACK=100回复在timeout之前丢包了,然后A收到了第二个segment的ACK=120,这时A就知道B已经完美收到了序列号120以前的所有segments,因此不会重传。
3.5.4.1 Doubling the Timeout Interval
每当timeout时,TCP会重新传输所有已发送但还未收到ACK的segments,然后设置下一次的timeout interval:
如果timer重新开始计时前发生这两种事件之一:【收到应用层传来的数据且窗口有位置放下】或【收到ACK回复】,则下一次的timeout interval根据EstimatedRTT和DevRTT计算。
note:第一个事件代表有新数据(非重传数据)可以发送,第二个事件代表网络状况不拥堵。这两种情况下是之前讨论中的正常情况,直接根据EstimatedRTT和DevRTT计算timeout interval即可。
否则直接设置为上次的两倍。
note:既没有新数据发送,网络状况也比较拥挤,那就将timeout interval设置大一点来降低重传速率,减轻网络拥挤状况。
这种方案提供了一个简单的congestion control功能,因为【timeout时有segments已发出但未被ACK】这种情况发生最有可能的原因是网络拥塞(太多的包滞留在某几个路由器的buffer中,导致后到达这几个路由器的包全部被丢弃,或者buffer中的包等待发出时间过长)导致的。在这种情况下如果sender还坚持不懈的重传,就会进一步恶化网络状况,为了应对这种情况,TCP会直接将timeout interval以一次两倍的规模扩大,降低重传的频率。
3.5.4.2 Fast Retransmit
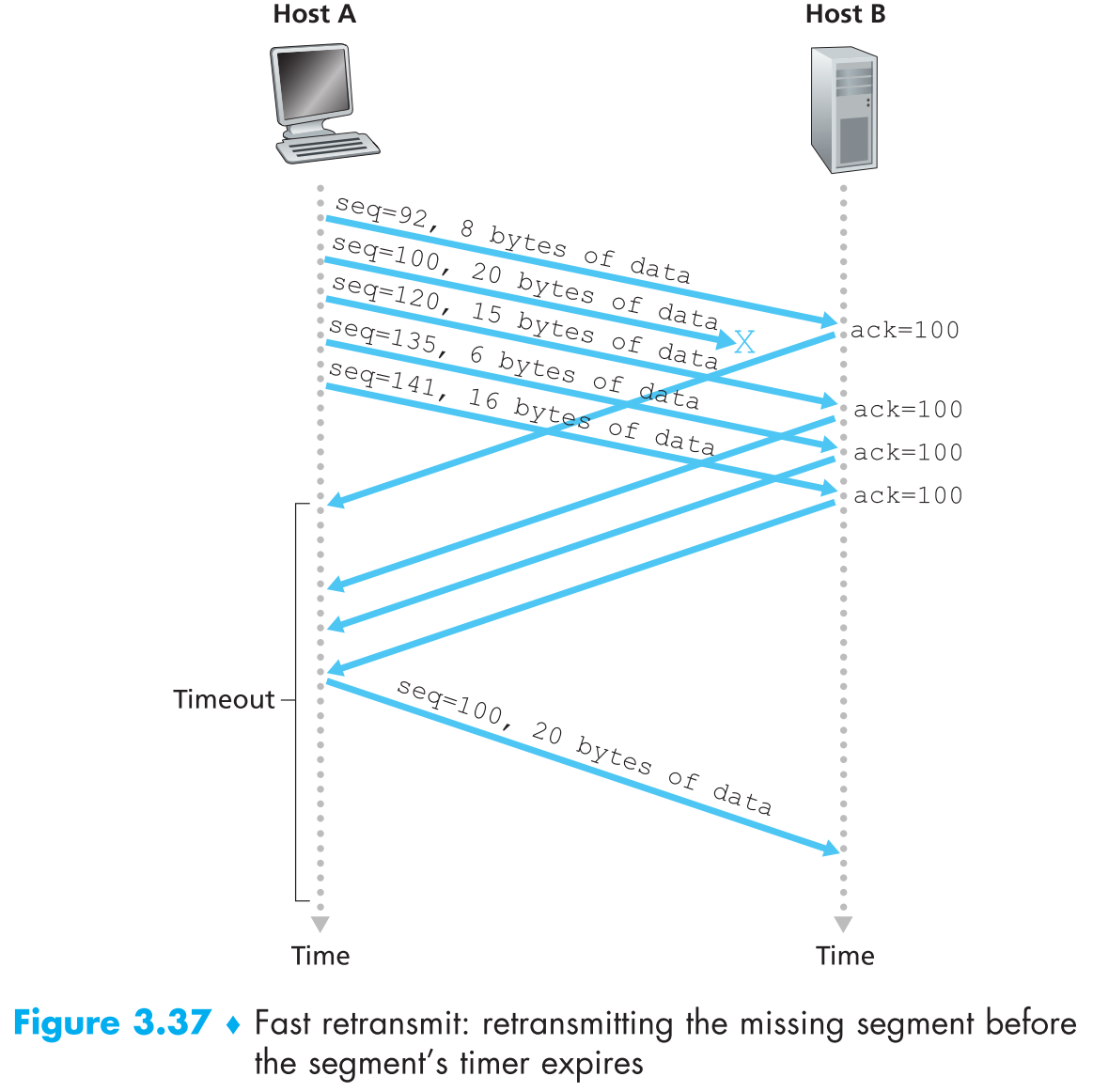
基于timeout的重传机制事实上并不高效,当一个segment丢失时,它并不能够立即被重传,而是要等到timeout,这样会增加端到端延迟。幸运的是,TCP sender通过duplicate ACK可以很容易在timeout之前检测到丢包是否发生,duplicate ACK是指【receiver对之前已经ACK确认过的segment再发送一次ACK】,下面先来看看TCP receiver为啥会发送duplicate ACK

当TCP receiver收到了一个【序列号】大于【期望序列号】的segment时,因为TCP不使用NAK,所以receiver只能通过重新发送【之前最大的已经正确收到的segment ACK】来表示自己刚收到的segment有问题。
因为sender通常连续成批地发送segments,所以ACK通常也是连续成批的回复给sender,如果TCP sender接收到了1个ACK后,又连续接收到与该ACK相同的3个duplicate ACKs,且它们都ACK同一个序列号,则它就断定该序列号之后的segment都丢失了,这时就会直接开始重传(无视timeout interval),该机制被称为 fast retransmit。
1 | event: ACK received, with ACK field value of y |
上面这些机制虽然很细节,但这都是使用TCP这20年来总结的宝贵经验。
TCP协议同时具有GBN和SR的特征。
3.5.5 Flow Control
TCP连接是全双工通信,因此连接双方都既是sender也是receiver,它们各自都有一个receiving buffer用来存储正确接收到的segments,它们上层的进程会【不时地】从这个buffer中取数据。
进程什么时候会到receiving buffer中取数据呢?答案是说不准。极端情况下,完全有可能CPU一直在处理另一个优先级非常高的任务,很长一段时间资源都轮不到那个会去buffer中取数据的进程。这种情况下如果sender还在不停努力的发包,很快receiver的buffer就会被填满,然后后续的segnments就都接收不到了。
TCP提供了 flow-control 的服务来降低sender把receiver的buffer塞满的概率,其原理就是控制【sender发包的速度】,尽可能的将它与【receiver的buffer中数据被取走的速度】匹配起来。
之前说过TCP sender的发包速度可能因为网络层数据的拥挤而降低,这种对sender发包速度的控制叫做 congestion control 。
虽然flow control和congestion control的效果很像,都是抑制sender的发包速度,但是实质上它们是不同的。
接下来我们将学习TCP是如何进行flow-control的,为了方便讨论,我们先【假设TCP receiver会直接丢弃乱序到达的segments】。
TCP sender会维护一个叫 receive window(rwnd) 的变量,它代表了对面receiver的buffer的当前状况。
假如现在A向B发起TCP连接,并向其发送一个大文件,B接受请求后先会为此次连接分配一个receive buffer,并用一个变量RcvBuffer来维护它的大小,另外TCP receiver中存在如下两个变量:
- LastByteRead:进程从receive buffer中【最近】取走的byte的序列号
- LastByteRcvd:TCP receiver从网络中【最新】接收到的一个byte的序列号
为了不让buffer中的数据溢出,必须保证
$LastByteRcvd - LastByteRead \le RcvBuffer$
所以TCP sender端receive window的值为:
$rwnd = RcvBuffer - (LastByteRcvd - LastByteRead)$
代表receiver端的接收buffer还有多少空间。
那么TCP是如何利用rwnd实现flow-control的呢?
receiver会在每一个发给sender的segment中的receive window字段说明自己receive buffer的剩余空间。
sender端会维护两个变量:LastByteSent和LastByteAcked。它们的差值$LastByteSent-LastByteAcked$ 代表有多少byte已经被发出但还没有被ACK,为了实现流控制,TCP sender必须保证这个差值小于rwnd,即:$LastByteSent-LastByteAcked \le rwnd$ 。
有一个非常重要的corner case。假如receiver的receive buffer满了,它就会发送一个segment告诉sender:rwnd=0,然后sender会暂停发包。从现在开始假定receiver不再向sender发送任何数据(包括ACK),过了一会,receive buffer中的数据被上层process取走,又有空间了,但sender根本无法得知,依然处于被阻塞无法发包的状态。
为了解决这个问题,TCP规定:sender接收到rwnd=0后,必须不断发送payload大小为1 byte的segments,receiver要对这些segments逐个进行ACK。
UDP没有flow control的功能,因此如果receiver的buffer满了,UDP sender后续发送的segments将全部被丢弃。
3.5.6 TCP Connection Management
这小节我们来详细讨论下TCP连接的建立和断开。假定终端A(client)上的某个进程想要向终端B(server)上的某个进程发起TCP连接请求:
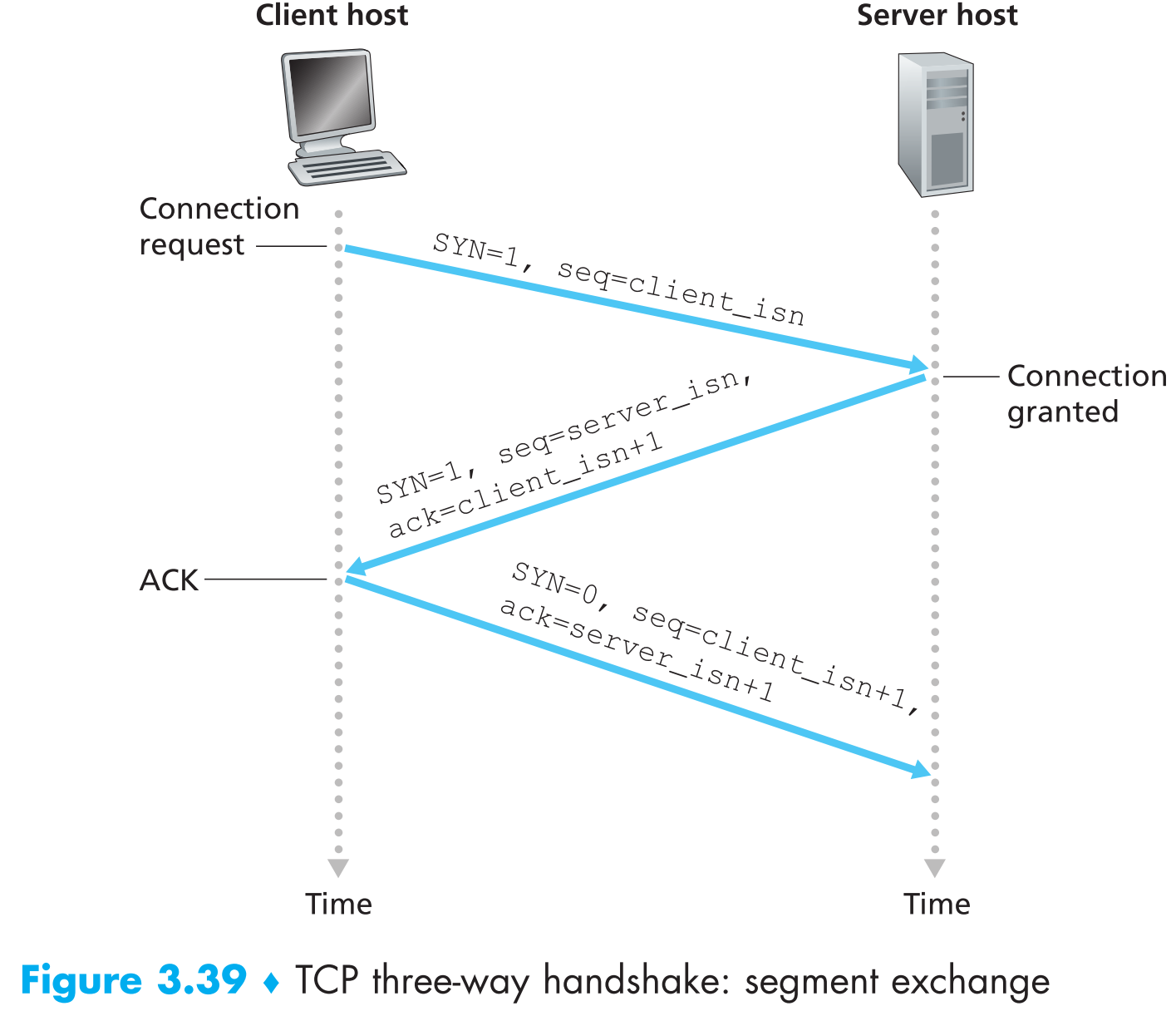
client端首先向server端发送一个特殊的TCP segment,这个segment中不含payload,但包含一些用于创建连接的信息:
a. SYN bit 标志位 。它的值被置为1,所以一般这个特殊的segment被叫做 SYN segment ,相当于client询问server:我能跟你创建连接吗?
b. 初始序列号字段 。client_isn 是client【根据某种规则“随机生成的”】(关于这个规则有很多研究,谨慎选取可以避免一些安全问题)
SYN segment到达server端后,server端会先为之后的TCP connection创建TCP buffer以及一些必要的TCP connection variables(注意这时其实连接还没有创建好,但是server端已经开始为连接分配资源了,这一点也充分体现了TCP协议设计之初并没有考虑安全问题),然后发送一个 connection-granted segment(代表允许建立连接)给client端。这个segment同样不包含payload,但是携带了创建连接的重要信息:
a. SYN bit设置为1。
b. 确认号字段设置为client_isn+1,
c. 另外server也会也会“随机”选取它自己的初始序列号server_isn放在序列号字段。
connection-granted segment相当于是server在回应client:我收到了你的请求,同意与你创建TCP连接,且用你提供的序列号client_isn为依据启动了TCP连接,我的序列号是server_isn。
connection-granted segment一般也被称为 SYNACK segment
client接收到SYNACK segment后,它就会开始为TCP connection创建buffer和一些variables,然后又会向server发送一个segment,这个segment中包含:
a. 确认号server_isn+1
b. SYN bit置为0
相当于对server说:我收到你的回复了!
要注意的是: 这个segment中可能包含client发送给server的payload。
这三个阶段完成后,client和server之间的TCP connection就创建好了,现在它们可以互相通信了,且【它们之后互相发送的segments中SYN总是为0】。因为创建TCP connection的过程总共需要三个包在通信双方之间传输,所以这个过程又被称为 three-way handshake
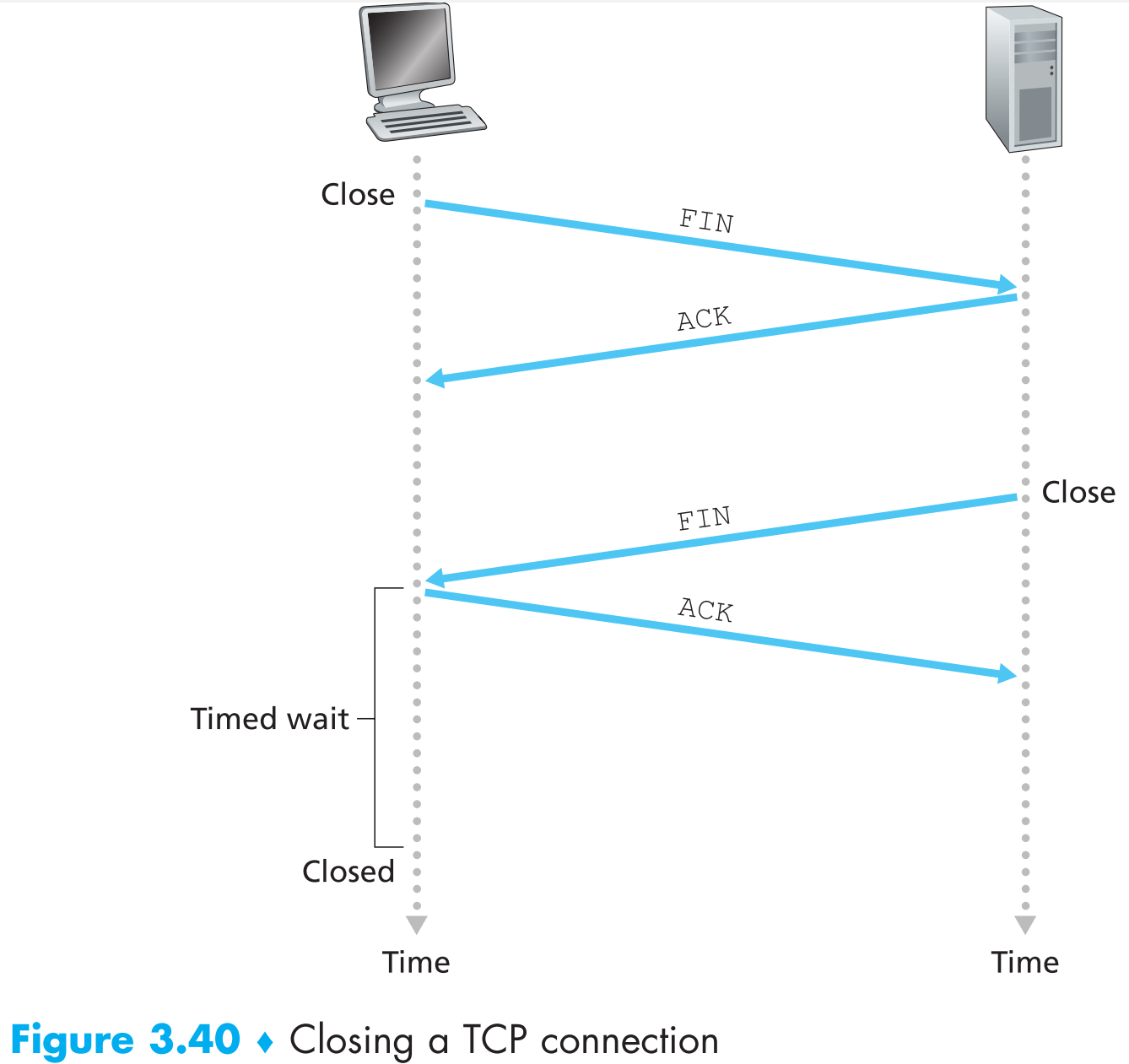
TCP通信的双方都有权利中止连接,当连接中止时,所有资源(buffer和varibales)都会被终端释放。现在假定client想要先中止连接:
- client会向server发送一个特殊的segment,这个segment中有一个特殊的标志位:FIN bit =1。这个segment又被称为 shutdown segment
- server收到Fin bit = 1的segment后,会ACK这个segment,然后再向client发送自己的shutdown segment
- client端对server发送的shutdown segment进行ACK
现在双方的TCP资源均被释放,TCP连接中止。因为断开TCP connection的过程总共需要四个包在通信双方之间传输,所以这个过程又被称为 four-way wavehand
在TCP connection的生命周期中,通信双方上运行的TCP协议会在不同的 TCP states 之间转换。
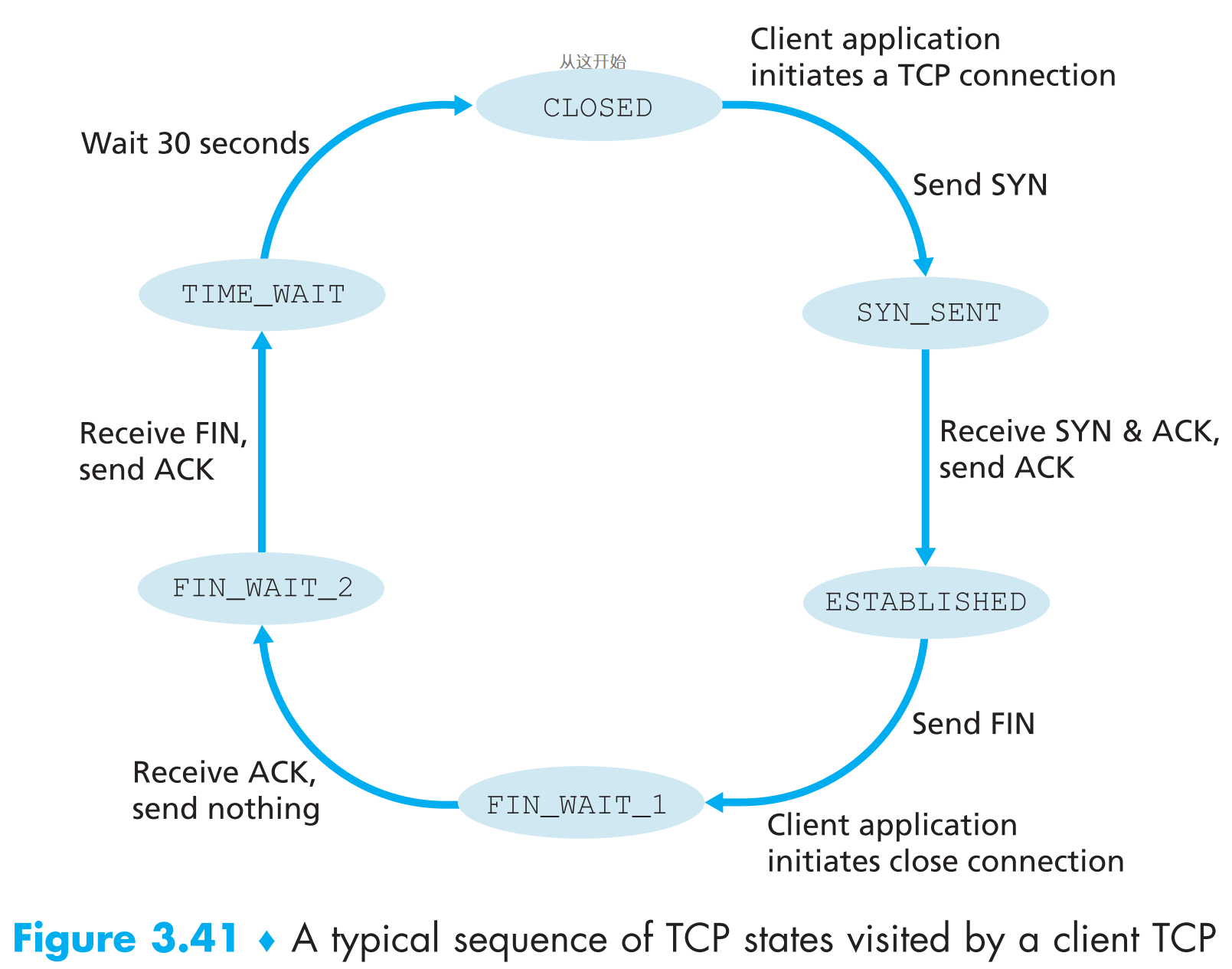
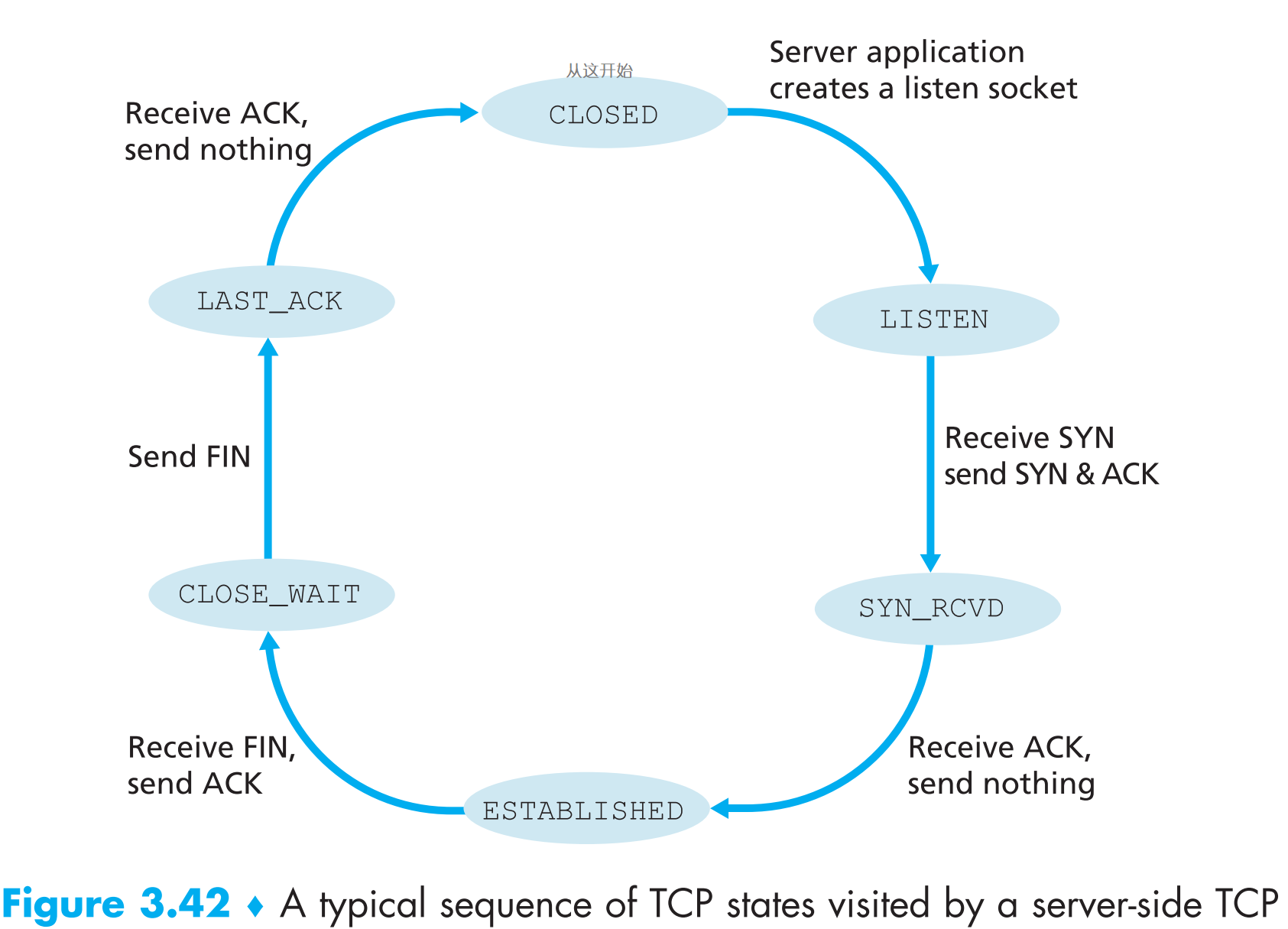
以上的讨论默认了TCP client发送的SYN segment的端口号是TCP server打开并正在监听的端口号,如果不是呢?那么TCP server就会回复一个特殊的 reset segment (RST标志位位1),代表:你请求的端口号我没有打开,请不要重传这个segment了。
一个流行的port-scanning tool是nmap,它的原理就是向目标终端的某个端口(如25)发送TCP SYN segment,结果有三种可能:
- 接收到目标终端回复的TCP SYNACK segment,代表其25号端口已打开并正在监听。
- 接收到目标终端回复的TCP RST segment,代表可以连通目标终端,但它的25号端口没有打开。
- 没有收到任何回复,可能发出的SYN segment被防火墙拦截了。
拓展: 因为只要发送SYN segment给TCP server,它就会立马为TCP连接创建资源,那只要高频率的发送SYN segments很快就能把server方的资源占完,这就是著名的SYN flood attack,为了避免这种攻击,现在的TCP server在接收到SYN segment时会进行一些验证,感兴趣的读者可以自行搜索学习。
3.6 Principles of Congestion Control
3.6.1 The Causes and the Costs of Congestion
接下来通过逐渐复杂的情况讨论该如何进行拥塞控制。对于每种情况,先介绍为什么会发生congestion,再讨论congestion对网络造成的影响。
3.6.1.1 Scenario 1: Two Senders, a Router with Infinite Buffers
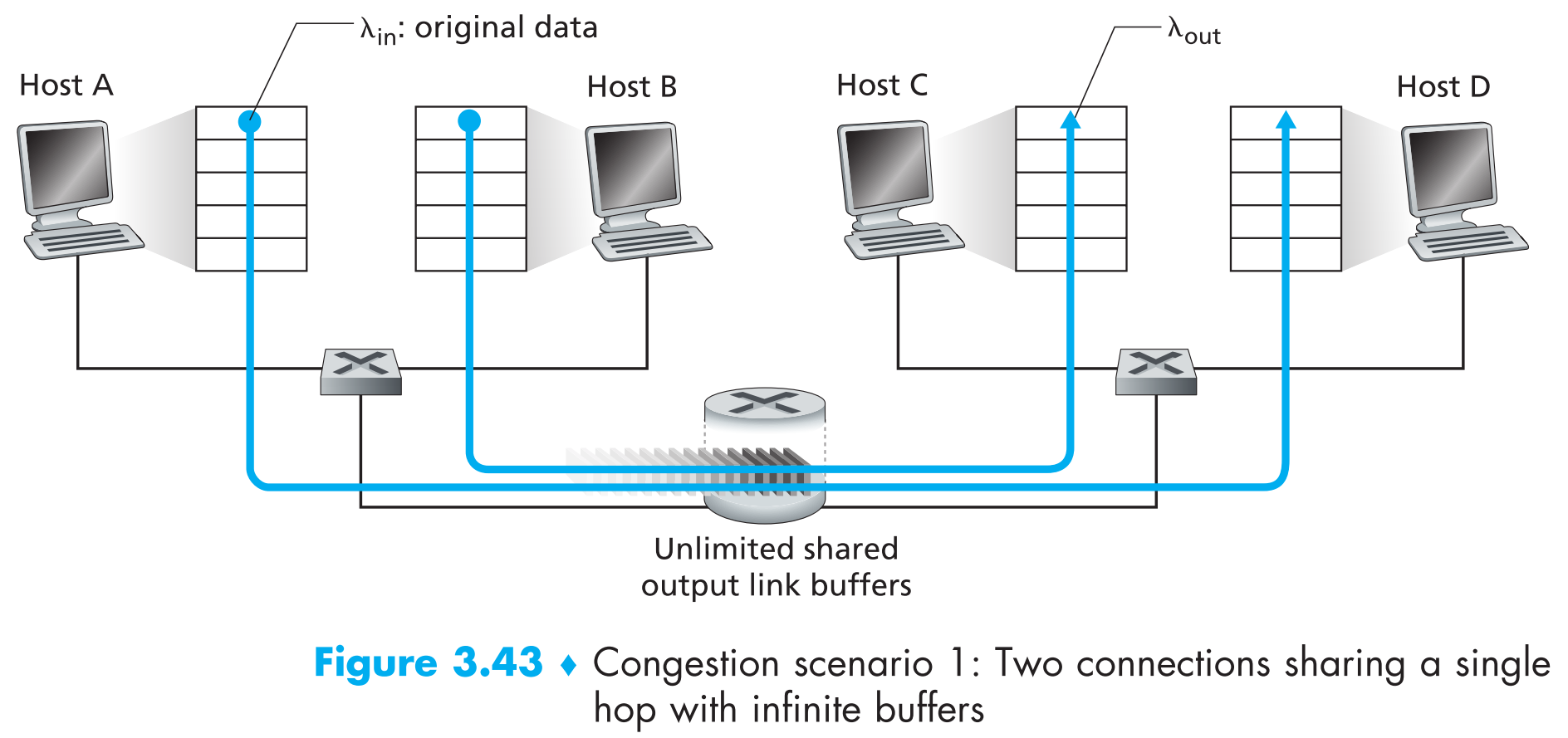
假设A和B的应用层都以平均 $\lambda_{in} ;bytes/sec$ 的速度往TCP连接中发送数据,所有数据只发送一次(即假定没有重传机制),且没有flow control和任何congestion control,封装带来的头部开销忽略不计。A和B的数据发送共享同一条链路,该链路的带宽为R,A和B各占R/2,router中有一个buffer,当packets到达的速度大于发出的速度时,会暂时存到buffer中,现在我们先假定这个buffer无穷大。
A的连接的性能分析如下:
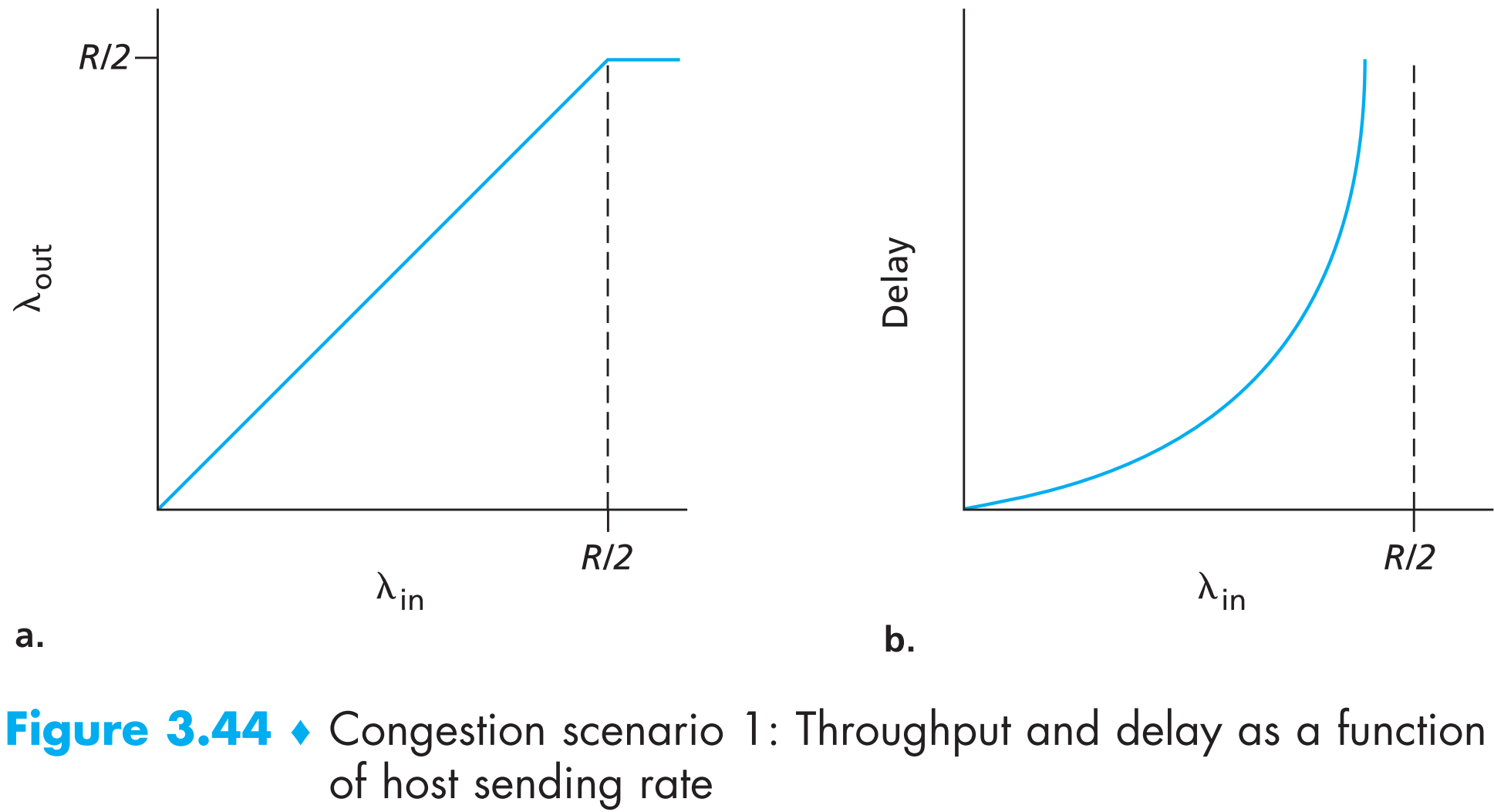
左边的图为【 perconnection throughput (代表每秒到达receiver的bytes数)】随着【每秒发出bytes数】变化的函数,因为是两个TCP连接共用一条链路,所以每个连接最多只有R/2的带宽,因此尽管sender的发送速率可以大于R/2,但是由于一个连接在传输信道最大速率限制为R/2,因此receiver的接收速率最大也只可能是R/2。另外路由器的处理速度可达不到R/2这么快,因此大于路由器处理速度的那部分数据包就会缓存到路由器的buffer中。
右边的图为【连接延迟】随着【sender每秒发出bytes数】变化的函数,连接延迟会随着发送速率的增长而增长(因为路由器的数据处理速度肯定低于链路的最大带宽),随着发送速率的进一步增长,越来越多的packets被缓存在路由器的buffer中,又因为假定了buffer的容量无限,当发送速率接近R/2时,路由器buffer中排队的数据包会越积越多,延迟趋向于无穷大。
可以看到即使在scenario 1这样极端的理想情况下,网络拥塞的代价也十分明显:随着发送速率逐渐提高,queuing delay也会相应的提高,如果发送速率大于等于链路带宽的话,queuing delay直接变成无穷大。
3.6.1.2 Scenario 2: Two Senders and a Router with Finite Buffers
现在在Scenario 1的基础上增加一些复杂度:
- 路由器的buffer大小变为有限,这个变化的后果就是如果buffer已满,那么后续到达的packets都会被直接丢弃。
- 假定每一个连接都是可靠的。即如果有segment被路由器丢弃的话,sender会在之后进行重传。
假定sender端应用层下发数据的速率为 $\lambda_{in} ; bytes/sec$ ,因为存在重传机制,所以运输层发出的包除了上层发来的新数据包之外还有重传数据包,因此需要将它们区分开(因为一个从上层发到运输层,一个从运输层直接发出),所以再定义运输层将segment发送到网络中的速率为 $\lambda’_{in} ; bytes/sec$(一般被称为 offered load) ,
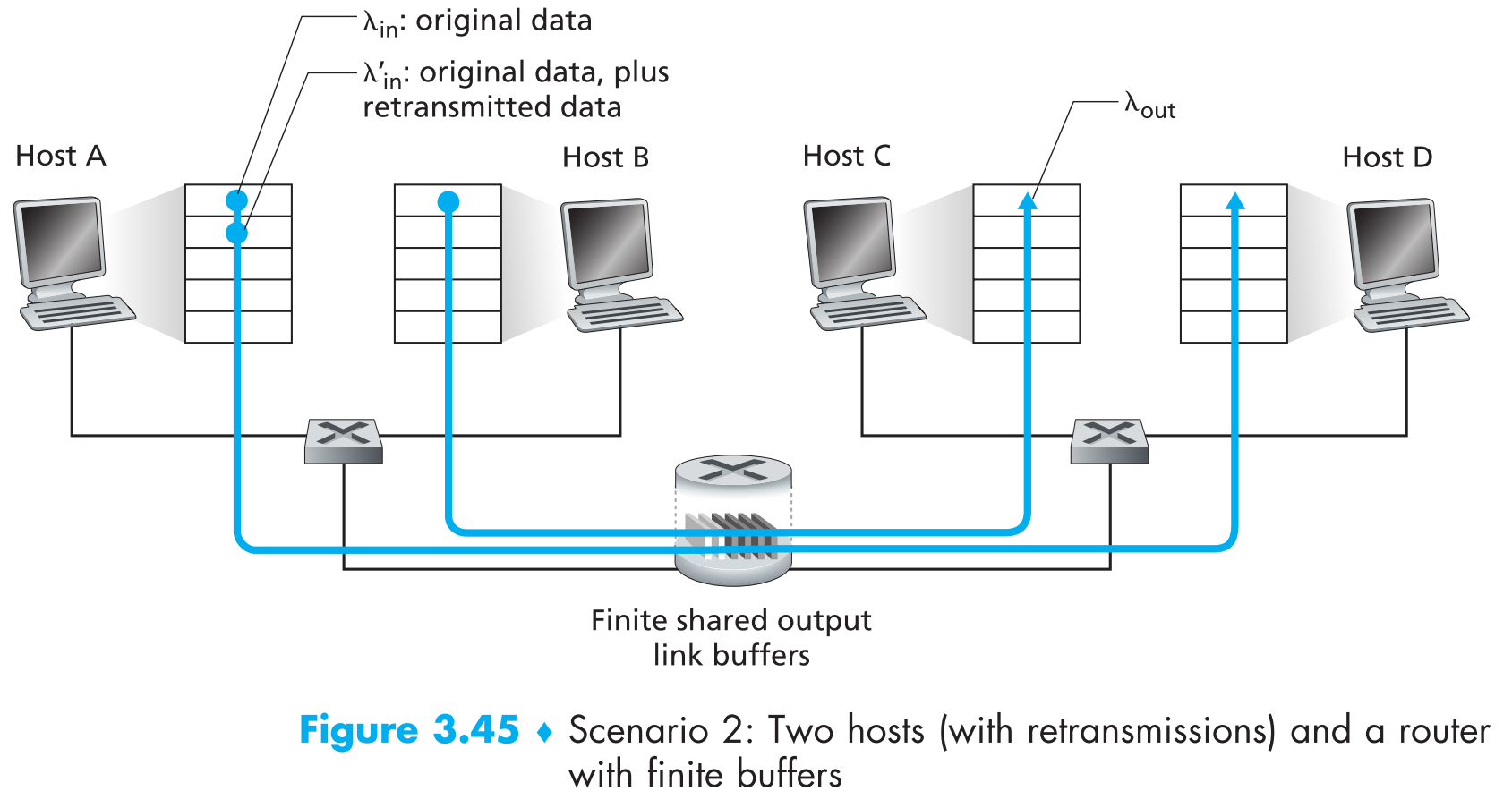
在Scenario 2中,整体网络传输的效率绝大部分取决于重传机制的实现方式。现在假定A能够看到router中的buffer情况,因此它在buffer满的时候就会停止传输,再假定它的发送速率不超过R/2,那么这种情况下不可能发生丢包,因此$\lambda_{in} = \lambda’_{in}$ ,如下图中的a。
再假定A可以确切地知道哪个包是“真的”被丢弃了,而不是因为在链路中滞留过久timeout从而被认为是丢包,这样A就可以只重传那些确实被丢弃的包(把timeout设置的非常大就可以达到这样的效果),假定 $\lambda’_{in} = R/2$ ,这时链路的情况可能如下图b(总带宽为0.5R,平均来看0.333R bytes/sec的新数据,0.166R bytes/sec的重传数据)
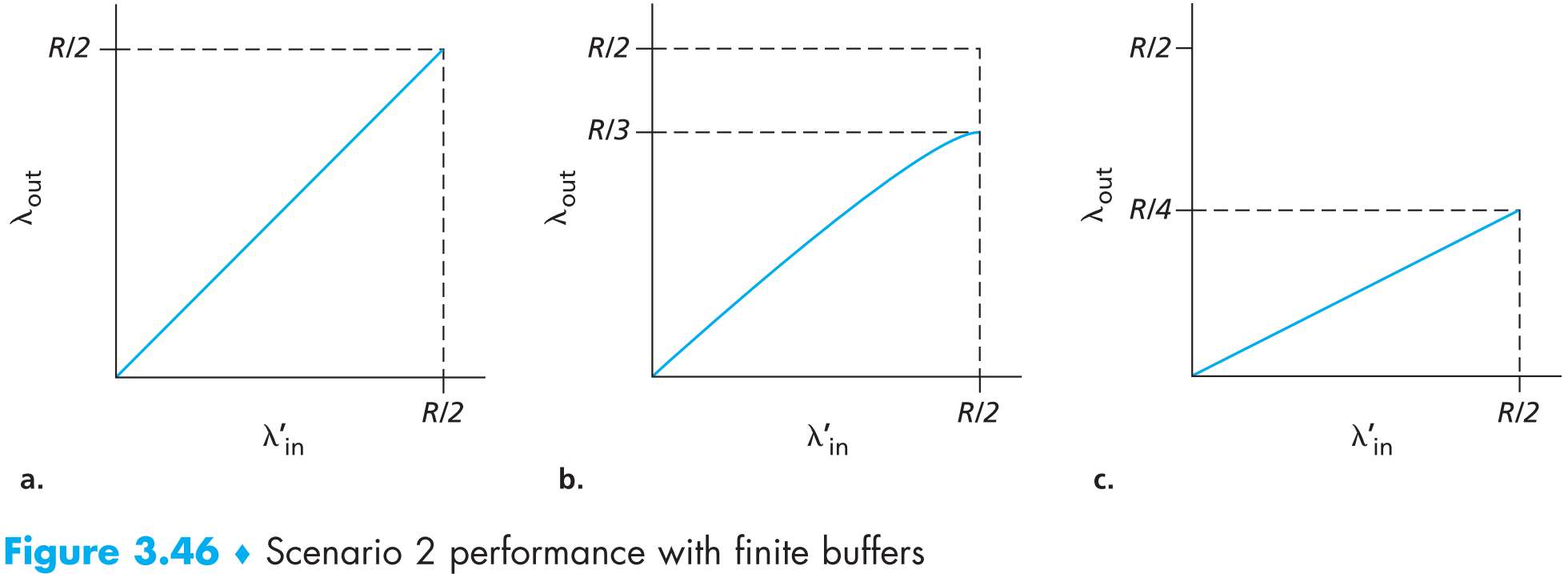
这时我们看到了网络拥塞给整体性能带来的另外一个影响:路由交换设备的buffer可能会被塞满,这时后续到达的数据会被直接丢弃(即丢包可能发生了),因此sender必须使用重传机制来处理丢包的情况
现在再增加一些复杂度,A无法得知哪些包是被丢了,哪些包是在链路中滞留(可能因为timeout设置的没有那么大)。这种情况就体现了网络拥塞对整体性能带来的又一个影响:可能一个包在链路中滞留过长时间,然后A在timeout后对该包进行重传(A以为该包被丢弃了),虽然receiver端可以很方便的处理这种情况(仅仅把重复的包丢弃即可),但是这样会给路由器造成额外的负担——【它可能会buffer很多完全没有用的包——重传的但是其实原数据已经被receiver正确接收的包】。上图c描述了这种情况——因为路由器中会有一些无用的重传包占用空间。
3.6.1.3 Scenario 3: Four Senders, Routers with Finite Buffers, and Multihop Paths
现在将传输路径变为多跳。这时我们会发现假如一个包需要经过N跳到达终点,那么如果它在第N跳被丢包了,前面N-1个路由器都白发这个包了,这是网络拥塞对整体性能又一个影响的体现。
3.6.2 Approaches to Congestion Control
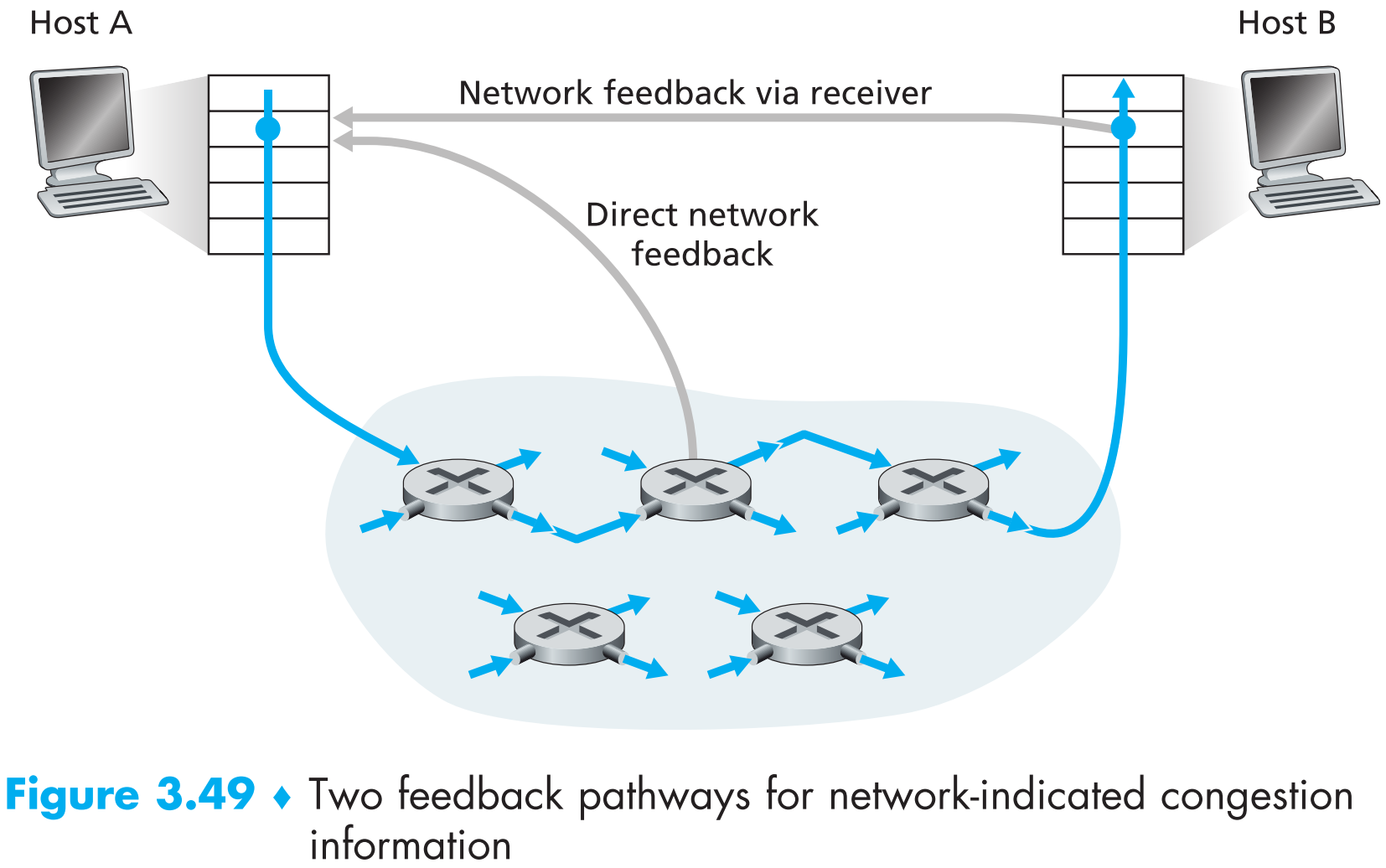
拥塞控制实现的方法有两种,我们可以通过【网络层是否为运输层实现拥塞控制提供明确帮助】来区分。
End-to-end congestion control 。这种方案中,网络层并不为运输层实现拥塞控制提供帮助,发送端只能靠“感觉”来判断网络状况是否拥塞(比如明显的网络延迟或者丢包)。
**Network-assisted congestion control **。
这种方案有网络层的协助,由路由器(一般通过以下两种方式之一)告诉sender或者receiver网络拥塞状况:
a. 网络拥塞时,路由器直接将网络拥塞信息(以choke packet的形式)发送给sender,相当于对它说:“我这很拥挤”。
b. 更加常用的一种方式是路由器对sender发往receiver的packet动手脚,将其中某个字段更改或标记来暗示自己的网络状况很拥挤。收到这样被更改过的packet后,receiver会在下一个发送给sender的segment中添加信息以暗示当前网络拥挤。缺点在于这种方式提醒网络拥塞会有一定的延迟。
IP和TCP的默认版本采用end-to-end方案,但最近它们也开始默认使用第二种方案了。
3.7 TCP Congestion Control
TCP采用的是end-to-end congestion control,因为IP层确实没有为TCP提供任何拥塞控制方面的援助。
如果TCP sender被告知【自己到receiver的这一路上】网络状况还好,它就会【提升自己的发包速率】;如果被告知这一路上存在网络拥塞,它就会【降低自己的发包速率】。现在我们主要弄清楚三个问题:
TCP sender如何限制自己的发包速率?
之前我们说到过TCP协议两端都会维护一些TCP连接参数。为了处理网络拥塞,TCP sender端会维护一个参数 congestion window(cwnd) ,发包速率会根据这个参数进行实时调整——【sender发出但未被ACK的数据不能超过cwnd和rwnd这两个参数的任意一个】,即:
$LastByteSent-LastByteAcked \le min {cwnd,; rwnd }$
为了方便讨论,我们下面的讨论假定TCP receiver的buffer无限大,这样TCP sender【发出但未被ACK的包】就仅被参数cwnd影响(而不受rwnd影响),通过更改cwnd的值就可以控制TCP sender的发包速率。
TCP sender是如何知道自己到receiver这一路上存在网络拥塞?
回忆一下,TCP sender当碰到【timeout时还有发出但未被ACK的包】或者【收到连续4个重复的ACK】时,就会认为发生了丢包,丢包会被sender理解为是网络拥挤的表现。
当正确收到ACK时,TCP sender会认为这时网络状况还行,就会【根据接收到正确ACK的速率来扩大自己的cwnd大小】。这种依据正确接收的ACK来扩大自己的cwnd大小的行为叫做 self-clocking 。
察觉到网络拥塞时,【网络拥塞现况】与【发包速率】数值上的关系应该是怎样的?
即使当前网络状况良好,如果多个经过同一段链路的TCP senders同时快速发包(看到网络状况好就“膨胀”了),那么网络很快就会进入拥挤状态。所以要限制它们的发包速率,但是也不能限制太多,因为那样会降低链路资源的利用率。为了找到一个平衡点,TCP遵循以下原则:
a. 丢包(timeout时有未被ACK的包或者连续收到4个重复的ACK)暗示发生网络拥塞,这时TCP sender必须降低发包速率。
b. 接收到正确的ACK代表sender到receiver这一整条链路网络状况不拥挤,这时TCP sender可以提高发包速率
c. 不断试探【在不造成网络拥挤的前提下】自己发包的最大速率(probing)
连续的接收到ACK时,sender不断的扩大cwnd(即在不超过rwnd的情况下不断的提升发包速率),直到遭遇丢包,才将cwnd大小缩小为【这次扩大前】的大小,然后每隔一段时间就再次重复上面的试探行为。这样就基本上可以保证TCP sender的发包速率在不造成网络拥塞的情况下尽可能的提高。
如果有多个TCP sender到receiver经过同一段链路,则每个TCP sender会独立维护自己的最大发包速率。
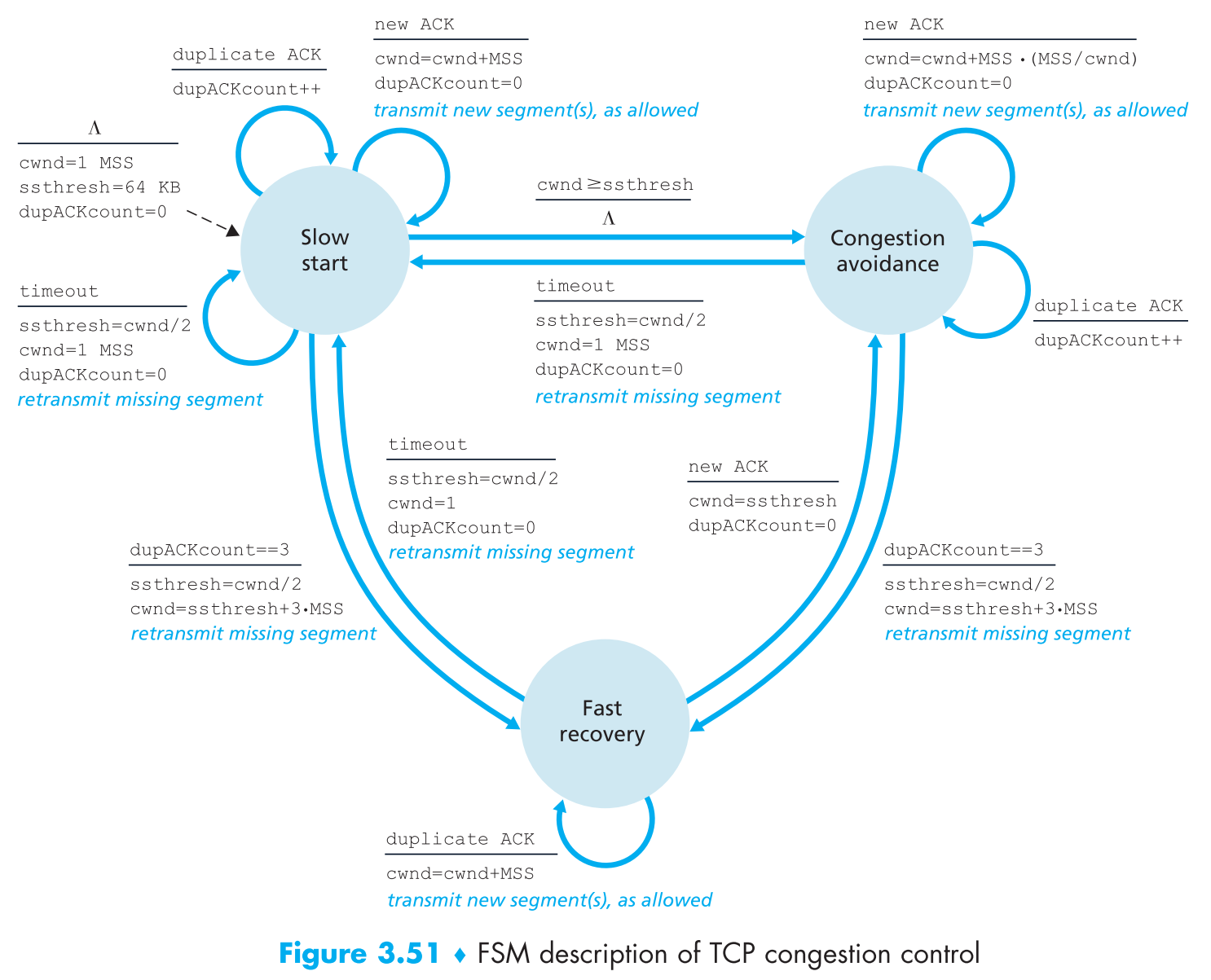
了解了以上内容之后,现在我们可以开始讨论 TCP congestion-control algorithm 了,该算法有三个主要功能:slow start,congestion avoidance,fast recovery。
前两个功能是必须的,且它们的功能十分相似(差别仅仅在于当接收到ACK时用什么方式扩大cwnd),slow start名字很慢,但其实它比congestion avoidance快的多。第三个功能fast recovery对于TCP sender来说是可选的。
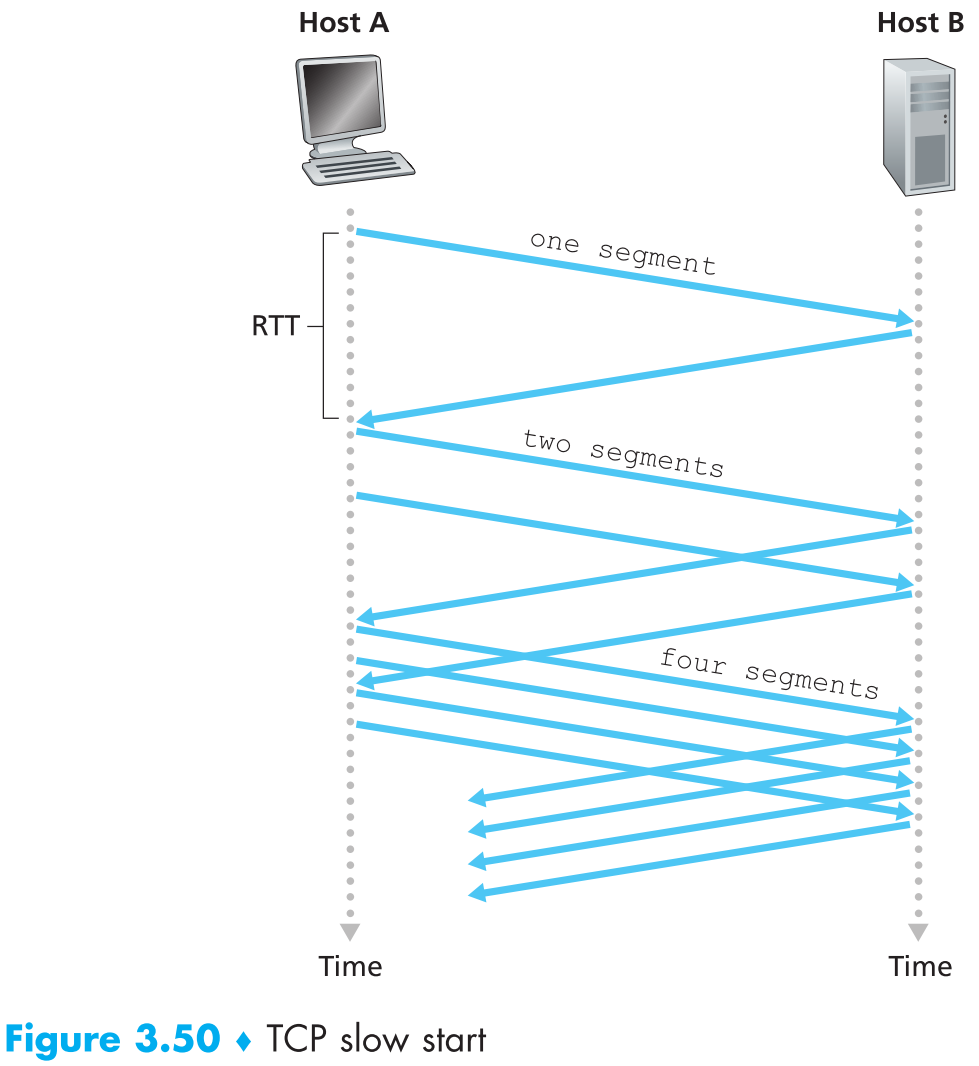
3.7.1 Slow Start
当TCP connection开始时,参数cwnd一般【初始为1个MSS的大小】,因此最开始的发包速率大概为MSS/RTT(例如当MSS = 500 bytes,RTT = 200 msec时,初始的发包速率为大概20 kbps)。因为可用的带宽一般会远远的大于一开始的MSS/RTT,所以TCP connection刚开始时sender会处于slow-start状态,这时cwnd每接收到一个ACK会增加1个MSS(这个增长是非常非常快的,指数级别)
那么慢启动什么时候停止呢?
- 当发生timeout型丢包时,TCP sender会把 ssthresh(slow start threshold) 设置为当前cwnd/2,然后将cwnd重新初始化为1个MSS的大小,开始慢启动。
- 当cwnd增长到等于ssthresh时,慢启动停止,进入congestion avoidance mode(如果说慢启动是迈大步子,那么碰到ssthresh就是扯到蛋了,进入congestion avoidance mode开始走小碎步)。
- 当发生three duplicate ACK型丢包时,TCP sender进行fast retransmit,同时进入fast recovery mode。
3.7.2 Congestion Avoidance
当进入congestion-avoidance状态时,cwnd大概为上次拥塞发生时cwnd大小的一半,但是很有可能cwnd + 1个MSS就再次发生网络拥塞,因此现在如果想要进一步增加cwnd必须十分小心:每接收到一个新的ACK,就令cwnd增长MSS*(MSS/cwnd)。即当前cwnd的值与之后的增长幅度成反比。
那么congestion-avoidance什么时候结束呢?
- 当发生timeout型丢包时,将ssthresh设置为当前cwnd的一半,然后令cwnd = 1 MSS并【开始慢启动】
- 当发生three duplicate ACK型丢包时,将ssthresh设置为当前cwnd的一半,然后令cwnd = ssthresh+3*MSS,接着【进入fast recovery mode】
3.7.3 Fast Recovery
因为three duplicate ACK导致的丢包会使TCP sender进入fast recovery模式,在此模式下每接收到一个duplicate ACK就令cwnd增长一个MSS。在此过程中,如果碰到timeout型丢包,就会将ssthresh设置为当前cwnd的一半,然后将cwnd设置为1并开始慢启动。
如果过程中收到正确的新ACK,就会令cwnd = ssthresh,然后进入Congestion avoidance状态。
3.7.4 TCP Congestion Control: Retrospective
现在忽略掉慢启动阶段,且假定只有收到three duplicate ACKs才被sender认为是发生了丢包(即假定timeout型不算丢)。回顾上一小节的内容,慢启动后TCP sender进入congestion avoidance状态,然后【大概】每个RTT会令cwnd+=1个MSS,该过程中如果碰到three duplicate ACK,就会把cwnd砍半,这种拥塞控制的策略被称为 additive-increase,multiplicative-decrease(AIMD) ,它的特点我们在3.7的开头已经描述过——碰到网络拥塞会把cwnd砍半,但是砍半后又会缓慢增长去 “试探” 引发网络拥塞的边界值。AIMD是使用TCP多年来实测得到的最优方案。
3.7.4.1 Macroscopic Description of TCP Throughput
下面来看看一个TCP connection的平均吞吐量,这里我们同样忽略掉开始的慢启动阶段以及由timeout型丢包引起的慢启动,因为慢启动阶段实际上【非常短暂】。
在某一个RTT内,TCP sender发送数据的速率受cwnd以及当前RTT影响。当cwnd=w bytes且当前往返时延为RTT秒时,TCP sender的发送速率大概为w/RTT,接着TCP会每过一个RTT把cwnd增加一个MSS,假设下一次丢包事件发生时cwnd=W bytes,那么TCP连接的发送速率会落在$[\frac{W}{2\cdot RTT},;\frac{W}{RTT}]$ 之间。也就是说,当发送速率增长到W/RTT时会发生丢包事件,丢包后发送速率砍半,接着开始每隔一个RTT将发送速率提升一个MSS/RTT直到发送速率再次到达W/RTT,这个过程会不断的重复。又因为TCP的发送速率(throughput)是线性增长的,且其具有最值,因此:
$$
\text{average throughput of a connection} = \frac{0.75\cdot W}{RTT}
$$
系数0.75通过真实数据测试得到。
3.7.4.2 TCP Over High-Bandwidth Paths
TCP的拥塞控制策略其实一直在更新,因为必须要与时俱进的满足不同时期对网络的要求。假如一个TCP连接的MSS为1500-byte,RTT为100ms,现在我们想通过这条连接以10 Gbps的高速度传输一个大文件,那么套用上一小节的公式,计算得到TCP sender所需的平均cwnd=83333 segments。在这种情况下如果发生丢包怎么办? 或者说,丢包率为多少才能保证链路依旧能以10 Gbps的速率传输数据呢?这里直接给出公式,定义丢包率为L:
$$
\text{average throughput of a connection} =\frac{1.22\cdot MSS}{RTT\sqrt{L}}
$$
通过这个公式我们可以看到如果想要让链路保持10 Gbps的传输速率,就必须把丢包率控制在$2\cdot 10^{-10}$ 以下,大约等于每5000000000个segments允许丢一个,达到这一目标是TCP的一个很重要的研究方向:高速网络中的TCP协议。因此TCP的版本仍然在不断更新。
3.7.5 Fairness
假如有K条TCP连接,除了一条传输速率为R bps的共同链路外,其余路径各不相同(且假定其余路径一定不会出现网络拥塞),每一条连接都在传输一个巨大的文件,且假定共同链路上不会经过UDP包,则当每一条TCP连接的平均传输速率都接近R/K时,就称现在采用的拥塞控制策略是【公平】的。
那么TCP所采用的AIMD拥塞控制策略公平吗?每条链路拥有不同的cwnd,能做到公平吗?
我们先来考虑一种简单的情形:两条TCP连接共享一段传输速率为R的链路,且它们有相同的MSS,以及相同的RTT(这样如果它们的cwnd相同,则它们的发包速率就相同),都采用AIMD的拥塞控制策略,它们都有大量数据要发送,且我们再次无视掉TCP的慢启动阶段,如下图
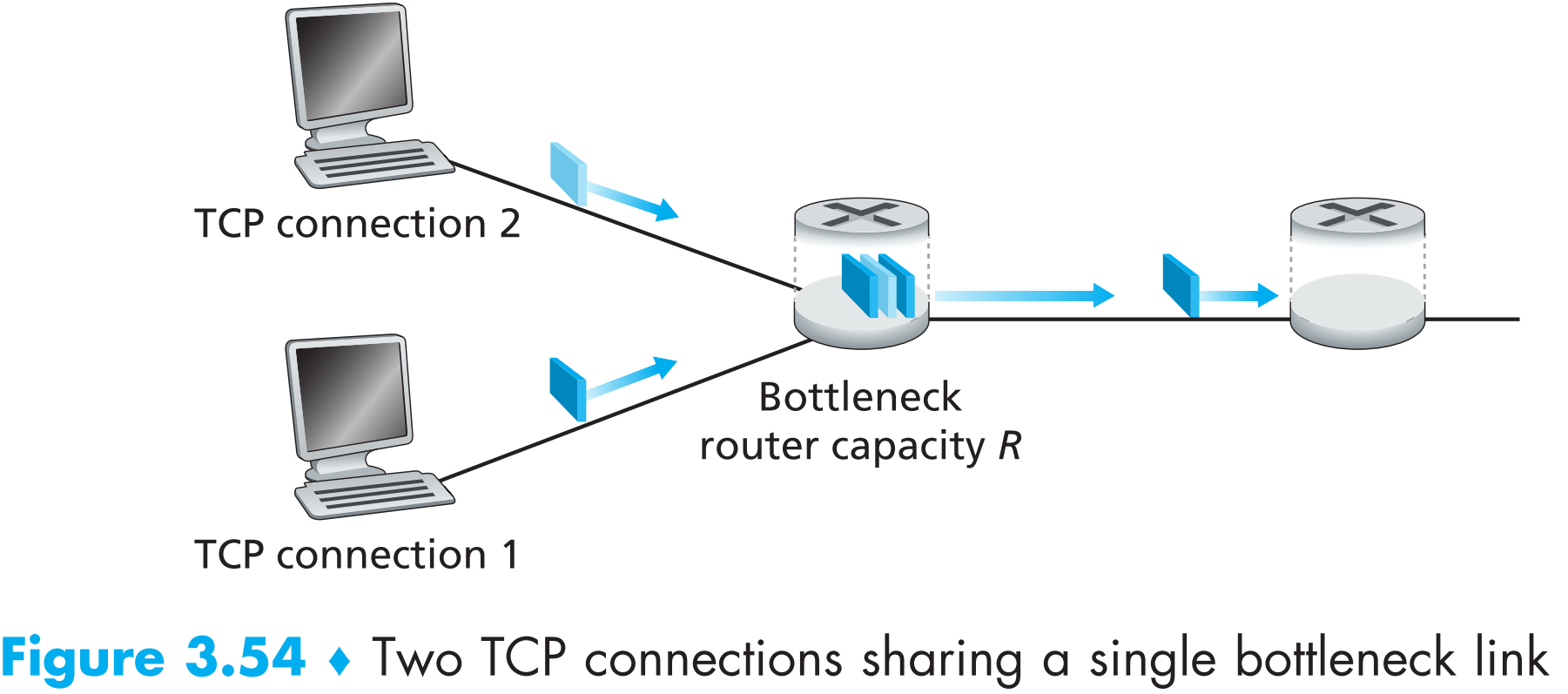
Figure 3.55 代表这两条TCP连接的吞吐量。图中从原点开始的45度直线代表TCP实现fairness时两条连接吞吐量的情况;理想情况下连接1与连接2的吞吐量相加等于R,这种带宽利用率的理想情况在图中用与Equal bandwidth share垂直的直线Full bandwidth utilization line表示。显然,TCP的目标应该是使两个连接吞吐量落在两条直线的交点附近,以期在【公平】的情况下最大化【带宽利用率】。
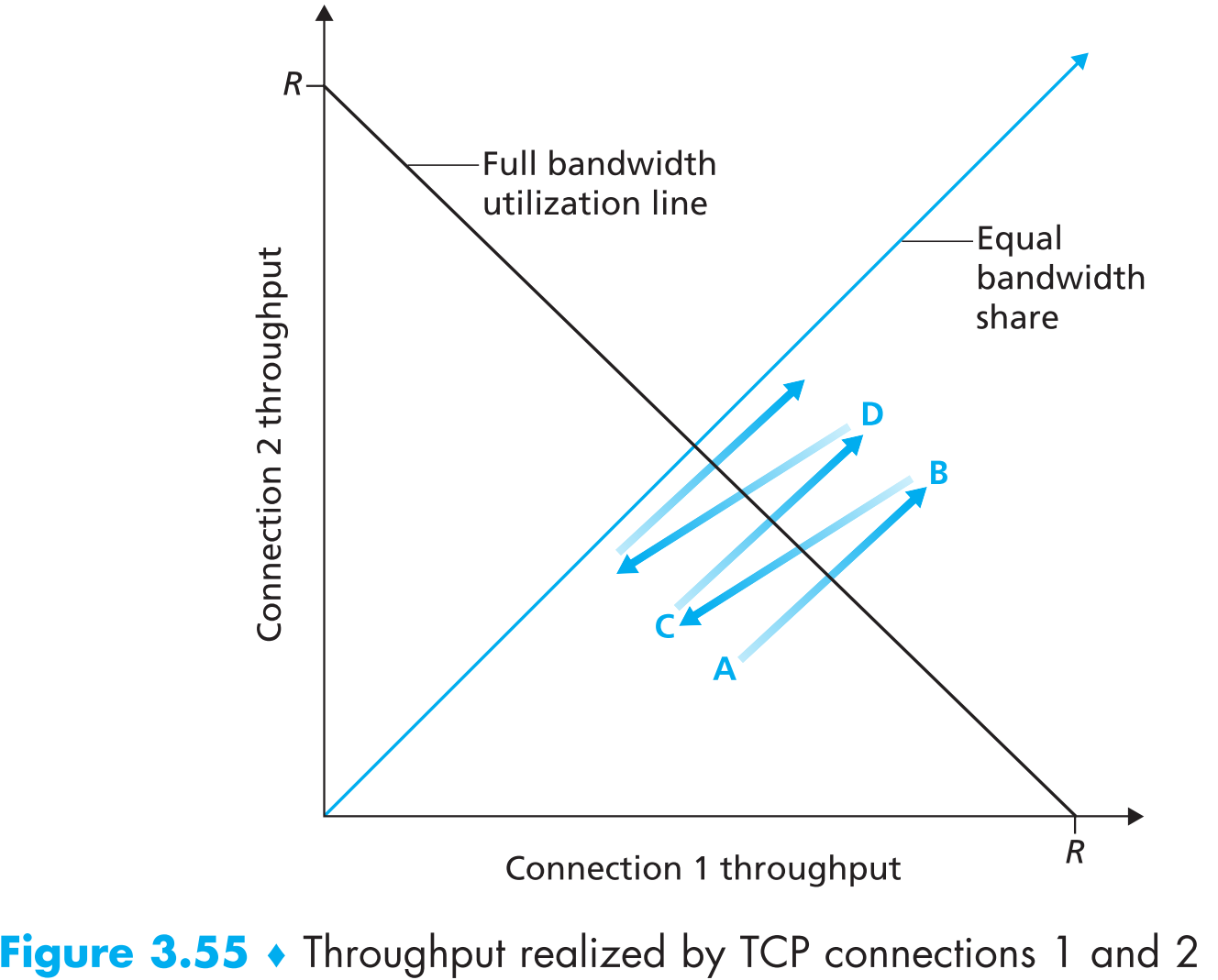
假如在某个时间点两条连接的吞吐量落在图中A点,代表他们总共占用的链路带宽小于R,那么目前不会丢包且现在sender处于congestion avoidance状态(每隔一个RTT,cwnd+=1 MSS)。一段时间之后,两条TCP连接占用的链路带宽会大于R(试探ing),然后发生丢包,现在假设在点B处两条连接的sender感知到了丢包,则它们都会把cwnd减半——到达点C处,然后又进入congestion avoidance开始缓慢增加cwnd,一会它们总共占用的链路带宽又大于R了——到达点D,又把cwnd减半,一直持续这个步骤,最终的结果是【无论开始它们各自的throughput是多少,两条连接共同的throughputs会不断的接近equal bandwidth share】,因为每次发生拥塞时所有连接的cwnd会砍半,当前吞吐量越大的连接砍的越多,反之越小的砍的越少,又因为它们的增长速度基本相同,因此每条TCP连接的吞吐量会趋向于相同,这就是TCP的拥塞控制策略公平的原因。
3.7.5.1 Fairness and UDP
网络多媒体应用——如网络电话或者网络视频一般通过UDP实现,使用UDP的目的是不想限制数据的发送速率(即使现在网络很拥挤),因为一般这类应用都需要【稳定的传输速率】而非可靠传输。
因为UDP的这种特性,公共链路很可能会被UDP大量占领,现在的一个研究方向就是如何解决这个问题。
3.7.5.2 Fairness and Parallel TCP Connections
即使上述UDP的问题被解决了,链路的公平性问题也依然存在,因为基于TCP的网络应用可以同时使用多条并行的TCP connection,比如web浏览器会开启多条并行的TCP连接从web server为一个网页取objects来加快该网页的加载速度,这种情况下该网络应用就会占据大部分的链路带宽。
举个例子。一条带宽为R的链路可以同时负载9个TCP连接,现在有9个网络应用的流量经过这条链路,且它们各自都使用1条TCP连接。如果现在新进来了一个网络应用,它创建了11个并行的TCP连接,那么它就会占据该链路超过R/2的带宽,所以TCP到底公不公平- -?
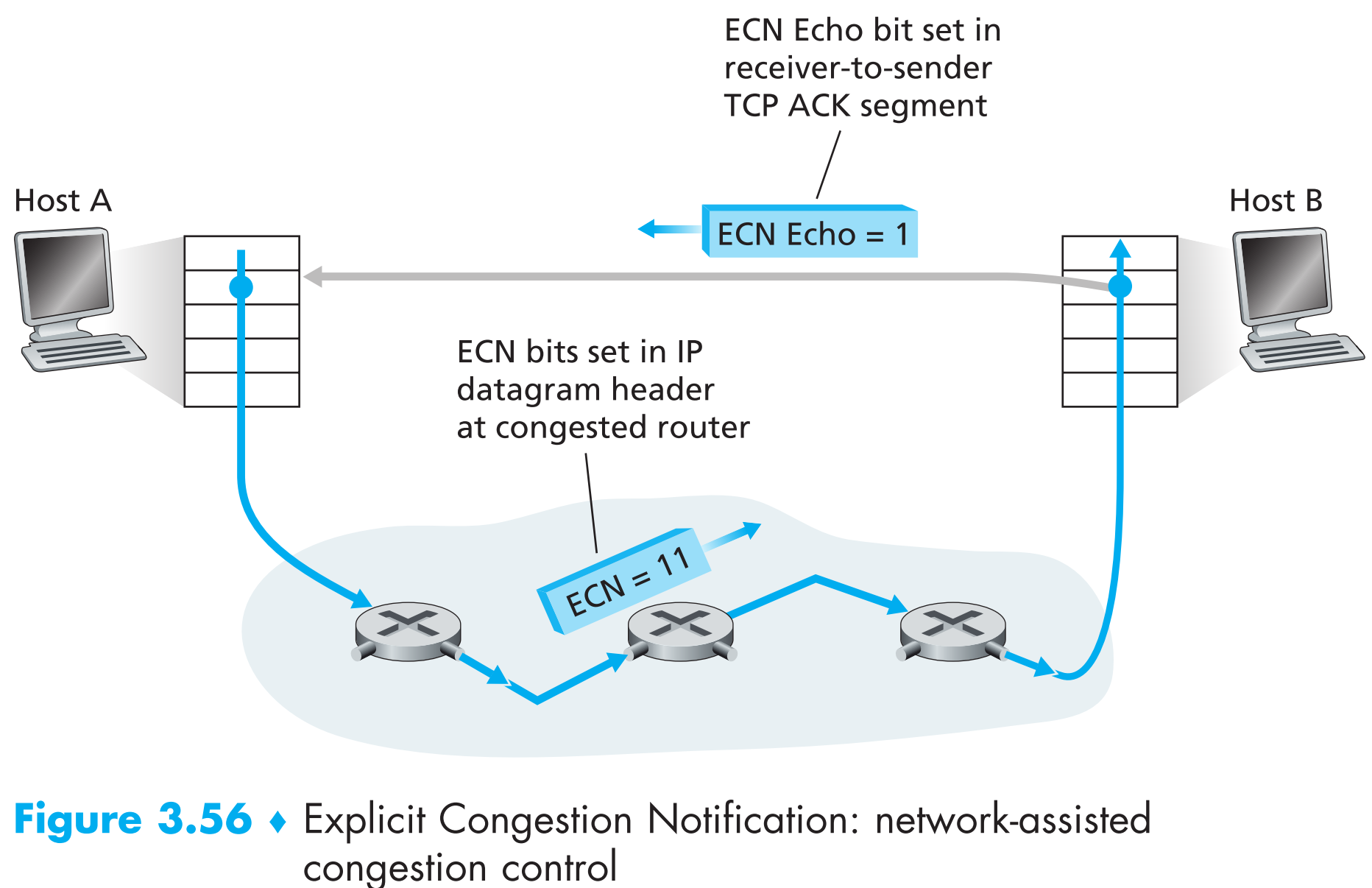
3.7.6 Explicit Congestion Notification (ECN): Network-assisted Congestion Control
之前提到过还有一种拥塞控制是需要IP层协助的,IP datagram header中有一个2-bit的字段(Type of Service)的功能就是ECN,因此一般也称它为 ECN bit 。
ECN bit的一个应用场景就是【路由器用来表达自己现在是否处于拥塞状态】,当路由器处于拥塞状态时,它会在IP datagram中将ECN bit置1,该IP datagram最终会传到receiver处,receiver发现ECN bit为1,就会在下一个发送给sender的ACK segment中将ECE(Explicit Congestion Notification Echo)bit 设置为1,以此告知sender网络状况拥挤。sender收到ECE=1的ACK后,就会将cwnd砍半,然后fast retransmit,并将下一个发送给receiver的segment中的CWR(Congestion Window Reduced)bit置1来表示已正确收到拥塞通知。
是否采用ECN型的拥塞控制取决于网络管理员和路由设备销售商。
ECN bit的第二个应用场景为【sender通知routers:我和receiver都支持ECN的拥塞控制】