《CSAPP》Virtual_Memory
9.0 Introduction
现代计算机可以同时运行很多进程,在我们看来,这些进程就像各自拥有自己独立的内存空间一样,这种感觉是如何被抽象出来的,正是我们这一章要关注的问题。这些进程的数据被加载到内存中后是如何被组织的?多个进程之间的读写冲突问题(一个进程往内存中写入数据,可能把其他进程的有用数据覆盖了)又该如何解决?
为了解答这些问题,我们将要学习计算机系统中最伟大的技术之一:virtual memory(VM),它是多种技术共同交互作用下的产物,为每一个进程提供了巨大且统一的私有地址空间。
总的来看,VM提供了三种重要的功能:
- 将主存作为disk的cache
- 为每个进程提供了统一的地址空间格式,简化了内存管理
- 私有化进程的地址空间,从而杜绝了进程之间的读写冲突
VM的伟大之处在于我们根本感觉不到它的存在,似乎每个进程本来就拥有自己的独立地址空间一样。
9.1 Physical and Virtual Addressing
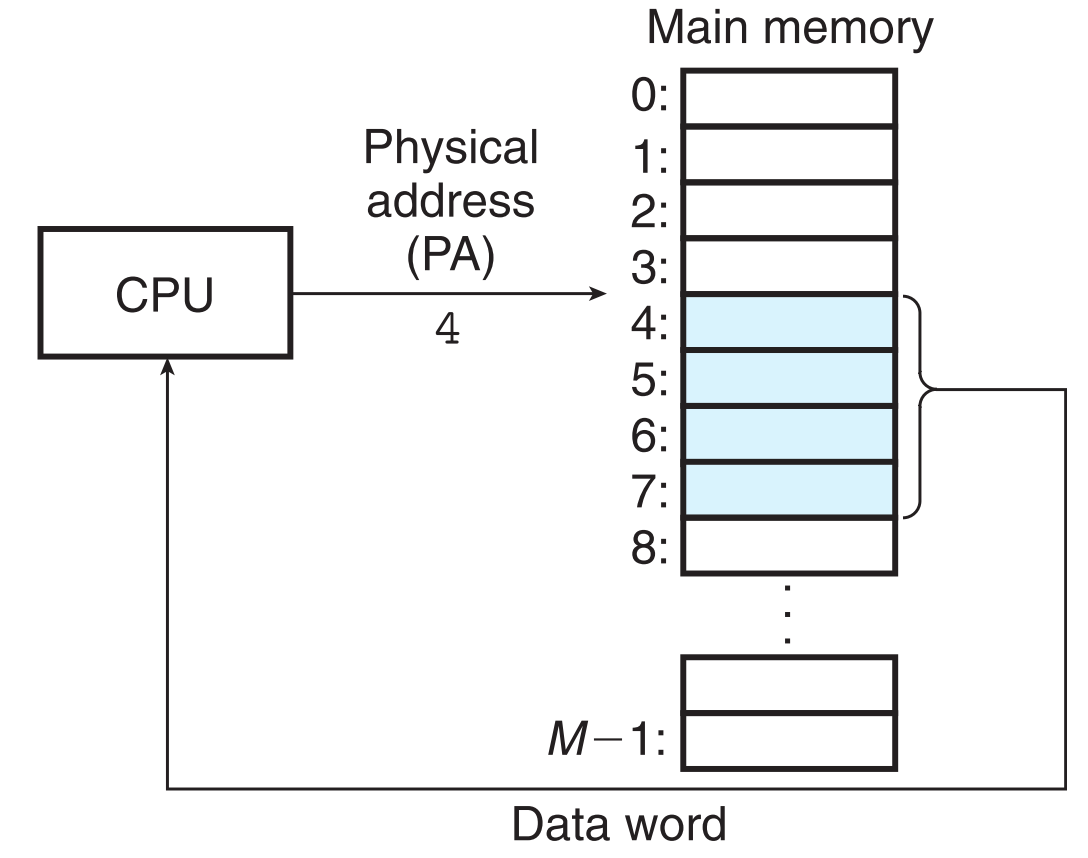
9.1.1 Physical Addressing
主存就像一个巨大的byte数组,它的“下标”叫做physical address(PA)。对于这种结构,CPU访问内存最自然的方式就是直接通过PA来寻址,这种寻址方式叫做physical addressing。
早期的计算机寻址方式都是physical addressing,而现在基本都是用virtual addressing了。
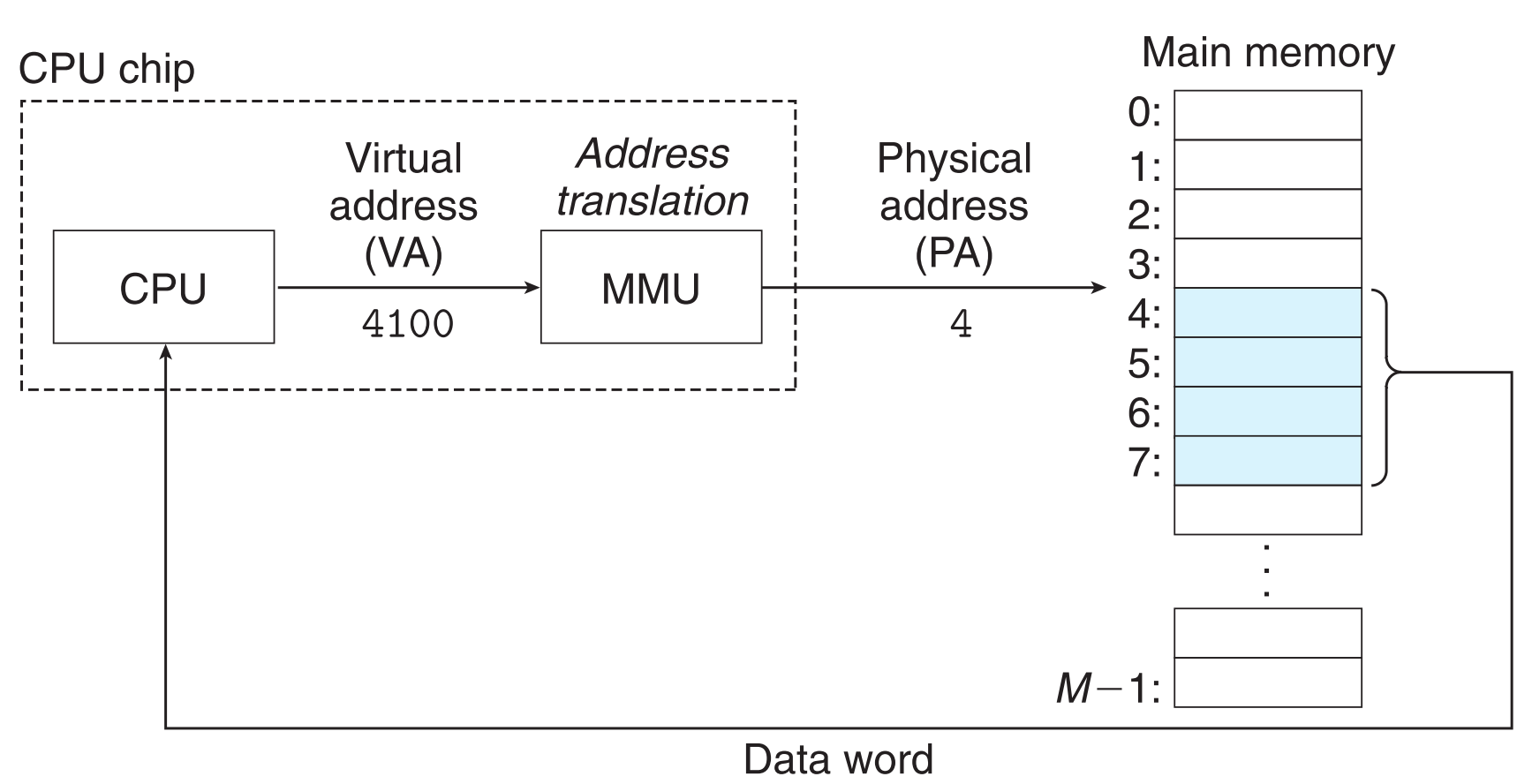
9.1.2 Virtual Addressing
CPU向主存发送的指令一开始为 virtual address(VA) ,VA在到达主存之前(MMU上)会被转换为对应的PA。这种将VA转换为PA的过程叫 address translation。地址转换基于CPU上的特定部件(memory management unit【MMU】),它通过查page table(存在主存中,被操作系统维护)来获取VA对应的PA。
9.2 Address Spaces
如果地址空间是连续的,它就被称为linear address space。
CPU从【n-bit】虚拟地址空间($0\sim 2^n$)中生成VA,现代计算机的n通常为32(4个G)。
系统中同样存在一个物理地址空间($0\sim 2^m$)。
其实物理地址空间不一定是2的指数倍,但为了方便讨论假定它是。
主存中存储的每一个page都同时具有一个VA和一个PA
9.3 VM as a Tool for Caching
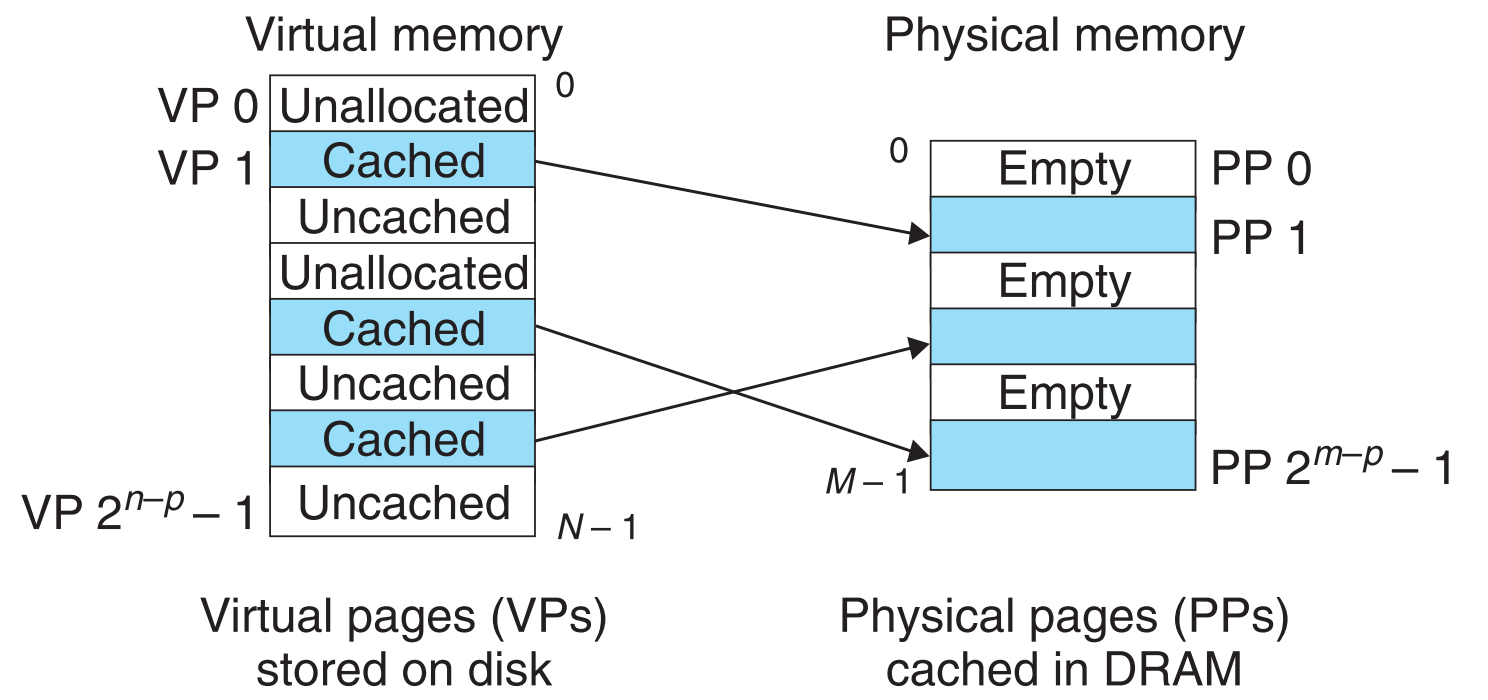
从概念上来看,虚拟内存就是disk的某一子集(连续的,单位为byte)的映射。主存(物理内存)充当一个cache的作用,缓存了虚拟内存中最近被CPU访问过的数据。和我们之前讨论过的cache一样,它们之间的数据交换也是以块(block)为单位的,虚拟内存被划分为一个个的块,叫做virtual pages(VPs),物理内存也被划分一个个的块,叫做physical pages(PPs),很显然VPs和PPs的大小必然是相等的。
在任何时刻,VPs可被划分为三大阵营:
| 阵营 | 为何加入此阵营 |
|---|---|
| Unallocated | 该页还没有被创建(haven’t been allocated),它现在没有任何数据,不映射到任何disk空间 |
| Cached | 该页已经被创建了(allocated),并且被缓存到物理内存中了 |
| Uncached | 该页已经被创建了(allocated),但还没有被缓存到物理内存中 |
9.3.1 DRAM Cache Organization
回忆之前的讨论,DRAM通常用作主存。SRAM通常用作主存与CPU之间的缓存,我们知道DRAM的速度比SRAM至少慢十倍,而disk又至少比DRAM慢100000倍,因此DRAM的设计结构就非常重要了,要尽量在DRAM这一级多命中,否则就得花费非常多的时间去disk取数据。
不仅如此,从disk中开始读取的第一个数据要比之后顺序读取的数据慢100000倍
下面用DRAM表示主存,SRAM表示CPU与主存之间的cache以方便讨论。
我们的目标是要尽量降低DRAM发生cache miss的概率(否则就要去disk取数据)
- 把Virtual Page的设置的大一些(通常4KB~2MB)
- DRAM采用全相联映射:即任一Virtual page可以被映射到任一Physical page
- 对cache miss的情况使用相对于SRAM中cache miss更加复杂的replacement policy(每次换页都要深思熟虑,否则就得去disk取数据了)
- 同样为了减少访问disk的次数,DRAM总是使用write-back而非write-through(参看《Memory Hierarchy-3.3 写》)
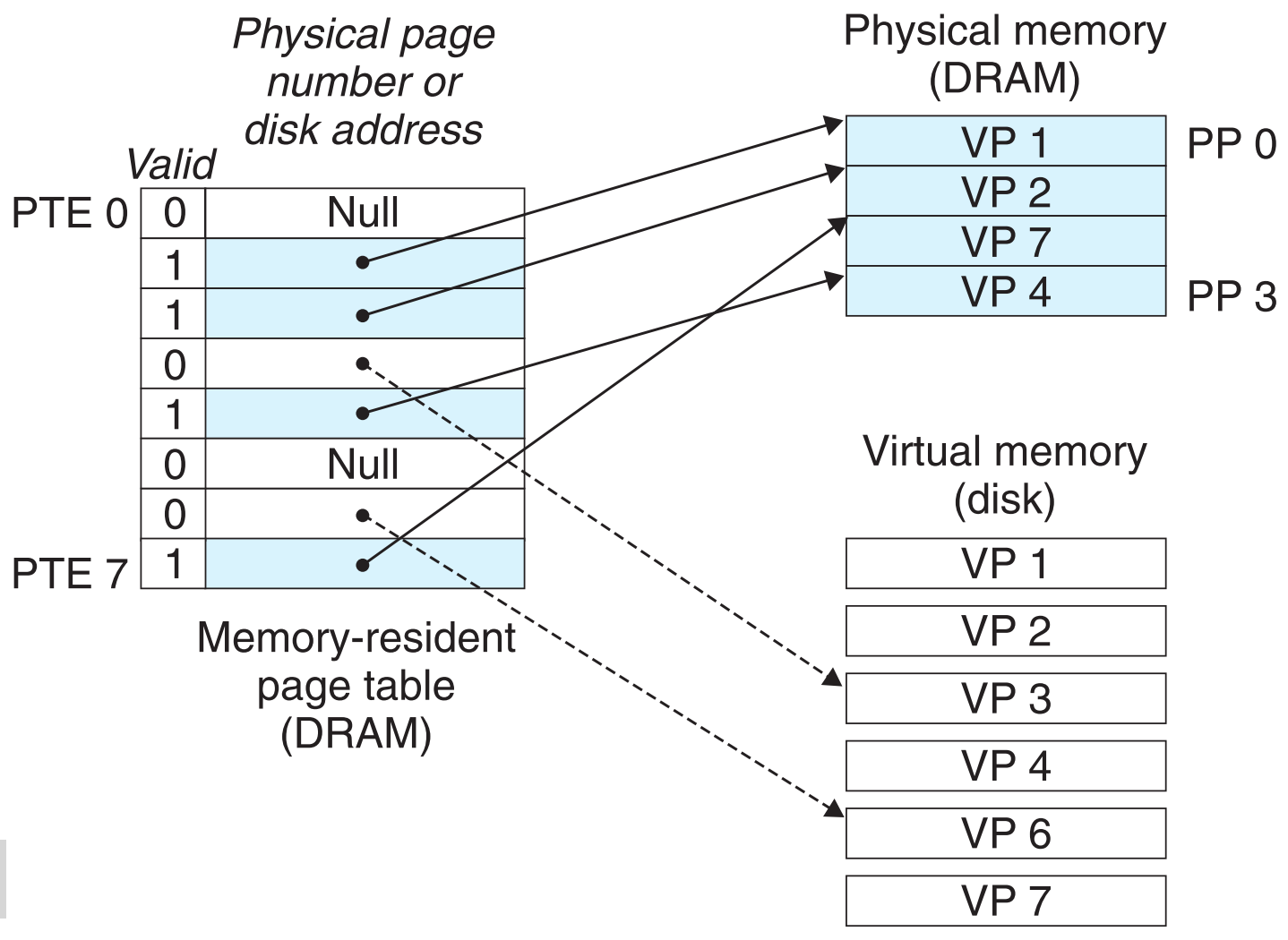
9.3.2 Page Tables
系统如何判断某个virtual page是否被缓存了呢?换句话说,如何判断数据在DRAM这一层cache hit了?如果cache hit了,那么它被缓存在哪一个physical page中呢?如果cache miss了,这个virtual page存储在disk的哪个位置呢?
这些问题是由操作系统、MMU中的地址转换部件和一个特殊的数据结构共同协作解决的,这个存储在物理内存中的特殊数据结构就是page table,它提供了virtual page与physical page之间的映射关系。
MMU中地址转换部件的职责:通过查page table得到VP对应的PP
操作系统的职责:维护page table,并负责disk和主存之间的page传输
以下是(某进程)page table的基本结构:
一个page table由一系列的PTE(Page Table Entries)组成,每一个VP都对应了page table中一个对应位置的PTE(如VP3对应PTE3)。page table中每一项都有一个valid bit,如果它为1,就表示该项对应的VP已经被cache在了物理内存中(如图中VP1, VP2, VP4, VP7);如果它为0,则若该项的地址为NULL,说明这个页还没有被allocate(如图中VP0, VP5),若该项的地址不为NULL,则它就是该VP在disk中的地址(如图中VP3, VP6)

要注意的是此例中DRAM是全相联映射,VP可映射到任一PP(因此本例物理内存中VP7在VP4上面),而page table和Virtual memory则是顺序的一一映射。
9.3.3 Page Hits
在上例的基础上,假如现在CPU要访问VP2。
MMU用CPU访问指令的virtual address定位到page table中对应的PTE(此例为PTE2),发现PTE2的valid bit为1(说明该page已经被cached了),就将该PTE中的物理地址发回给MMU,MMU再将刚才CPU访问指令的虚拟地址改为取回的物理地址(即该page在物理内存中的首地址),将指令重新发送一遍(这次直接发到PM中),完成一次page hit。
9.3.4 Page Faults
在使用VM技术的计算机系统上,在DRAM上发生的cache miss被称为 page fault 。
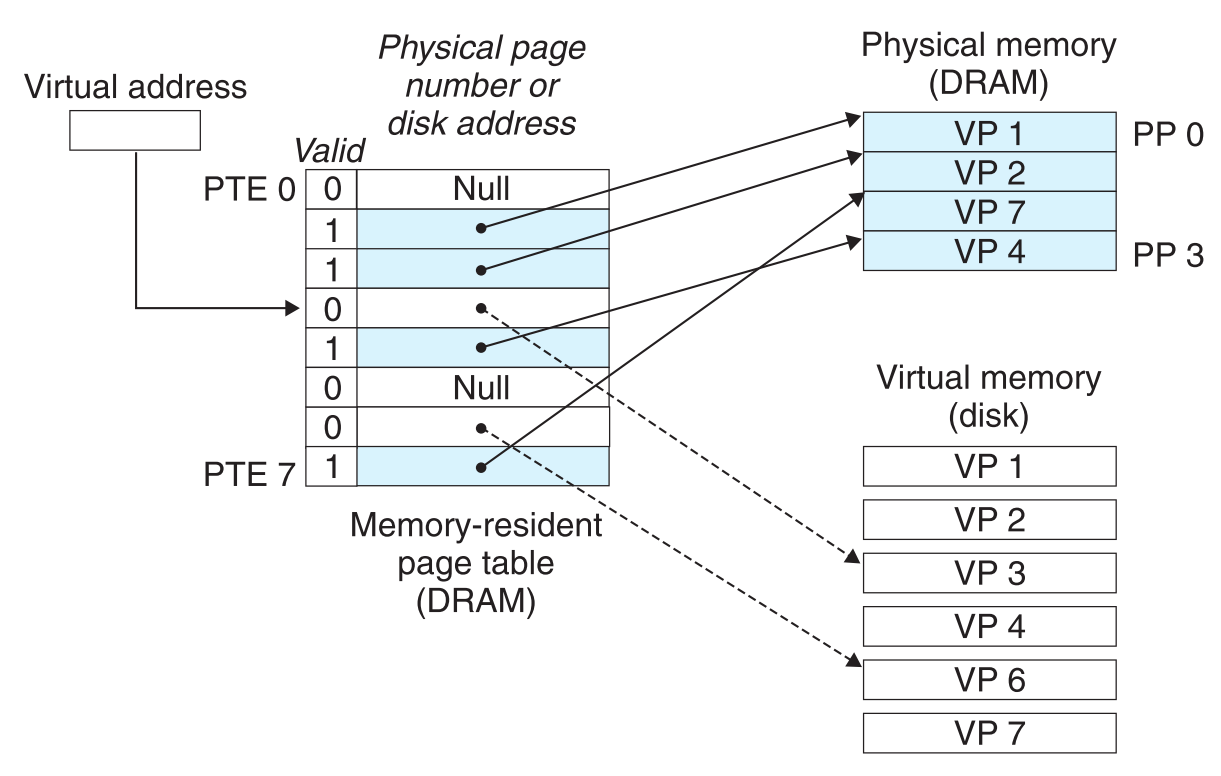
假如上图为访问前的内存状态,假定我们这次要访问的是VP3。
MMU先去page table查询,发现对应VP3的项PTE3中valid bit为0(表示VP3还没有被cache),这时就会触发一个page fault exception
page fault exception会调用内核中的page fault exception handler,该handler会选择一个PM中的一个PP作为victim page(此例中选择PP3,其中存储了VP4),先检测该victim page在被cache后是否被改动过:若被改动过,就会把它更新到disk;若没被改动过,则直接进入下一步。
将victim page对应在page table中的PTE标识为uncached
内核将VP3从disk中取出,用其覆盖PM中的victim page(VP4),然后更新PTE3,将其标识为cached
这时handler执行完毕,他会在return的同时重新调用引起page fault的那条指令(访问VP3),这次page hit
以下为处理完page fault后的状态:
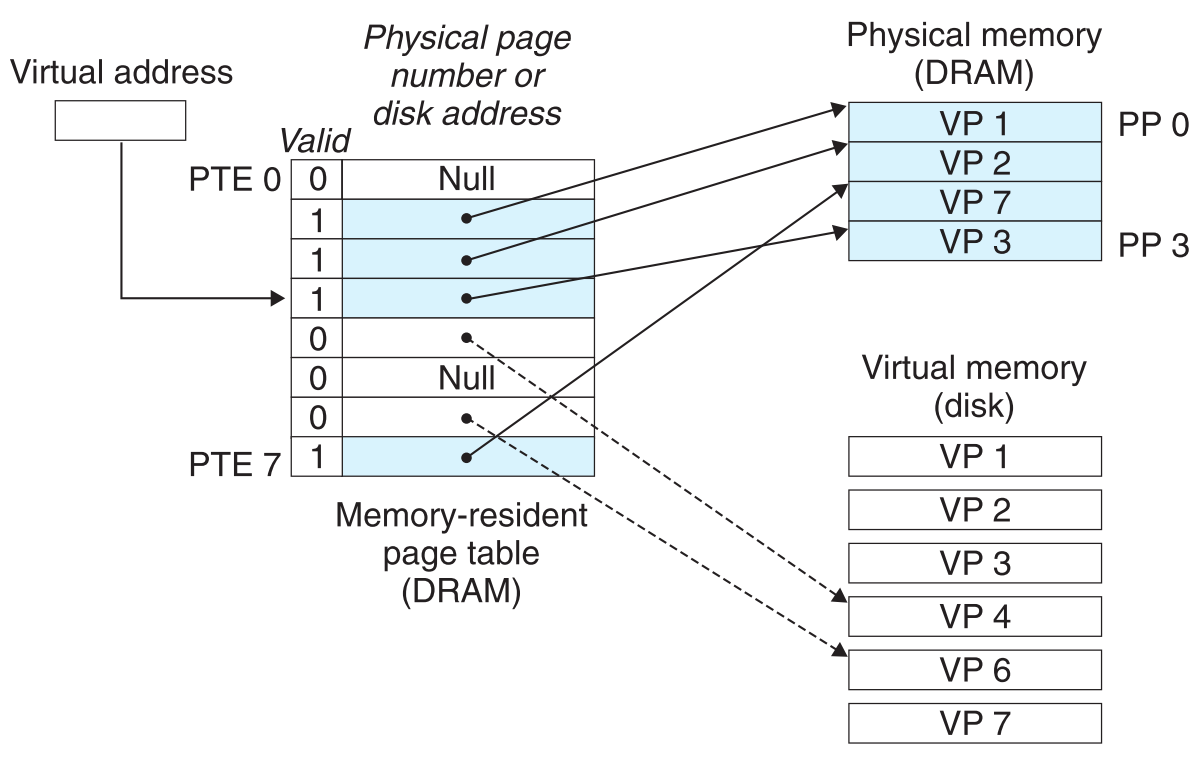
上面的讨论中,发生page fault后操作系统在PM与disk之间进行page交换的行为称为swapping或paging,Pages are swapped in (paged in) from disk to DRAM, and swapped out (paged out) from DRAM to disk.
某VP被cached并保存在PM中的这段时间内,即使发生更新也不会立即把更新写到disk中,而是等到它被置换之前(被选为victim page),才不得不将其内容更新到disk。这种发生page fault时,victim page将其内容更新到disk的行为叫做demand paging。(类似于之前讨论过的write-back写更新策略,参看《memory hierarchy》)
9.3.5 Allocating Pages
malloc函数的作用就是allocating pages。
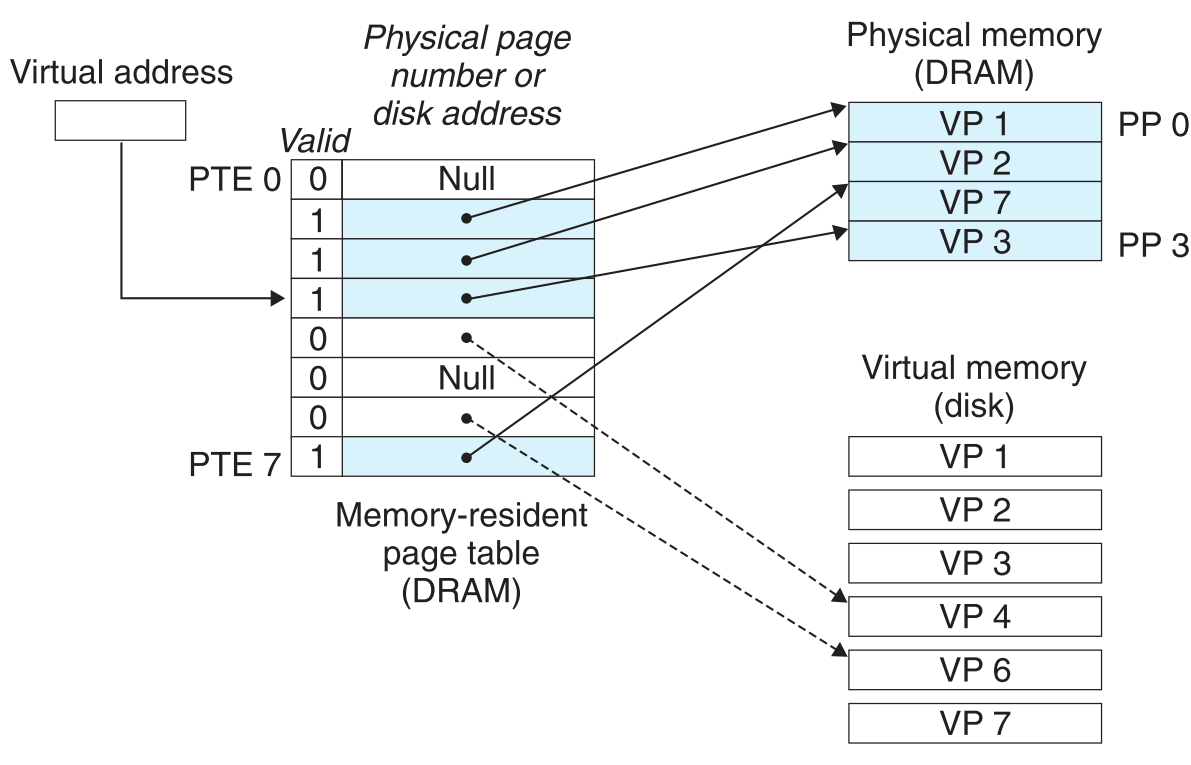
比如在上图的基础上,调用了malloc函数,系统为它申请了VP5。
9.3.6 Locality to the Rescue Again
和我们之前讨论过的SRAM的Locality一样,DRAM同样遵循Locality。因此虽然DRAM与disk之间的paging耗费巨量时间,但DRAM中总是会存在一个working set,CPU的大部分时间都在访问这个set中的pages,因此整体速度还是比较快的。
也有可能会出现不幸的状况:thrashing(在《memory hierarchy》中讨论过),反复的进行paging,极大的影响计算机的性能,因此在编写程序时要尽可能的使其具有良好的locality。
9.4 VM as a Tool for Memory Management
之前我们的讨论假定了整个系统中只有一个page table。然而事实并非如此,系统会为每一个进程分配一个独立的虚拟地址空间,所有进程的虚拟地址空间格式和起止地址完全相同,但是它们所对应的disk上的地址空间却不相同(不过也可能存在交叉部分,如下图进程i的VP2和进程j的VP1映射disk上的同一段地址),因此系统要为每一个进程都维护一个page table。
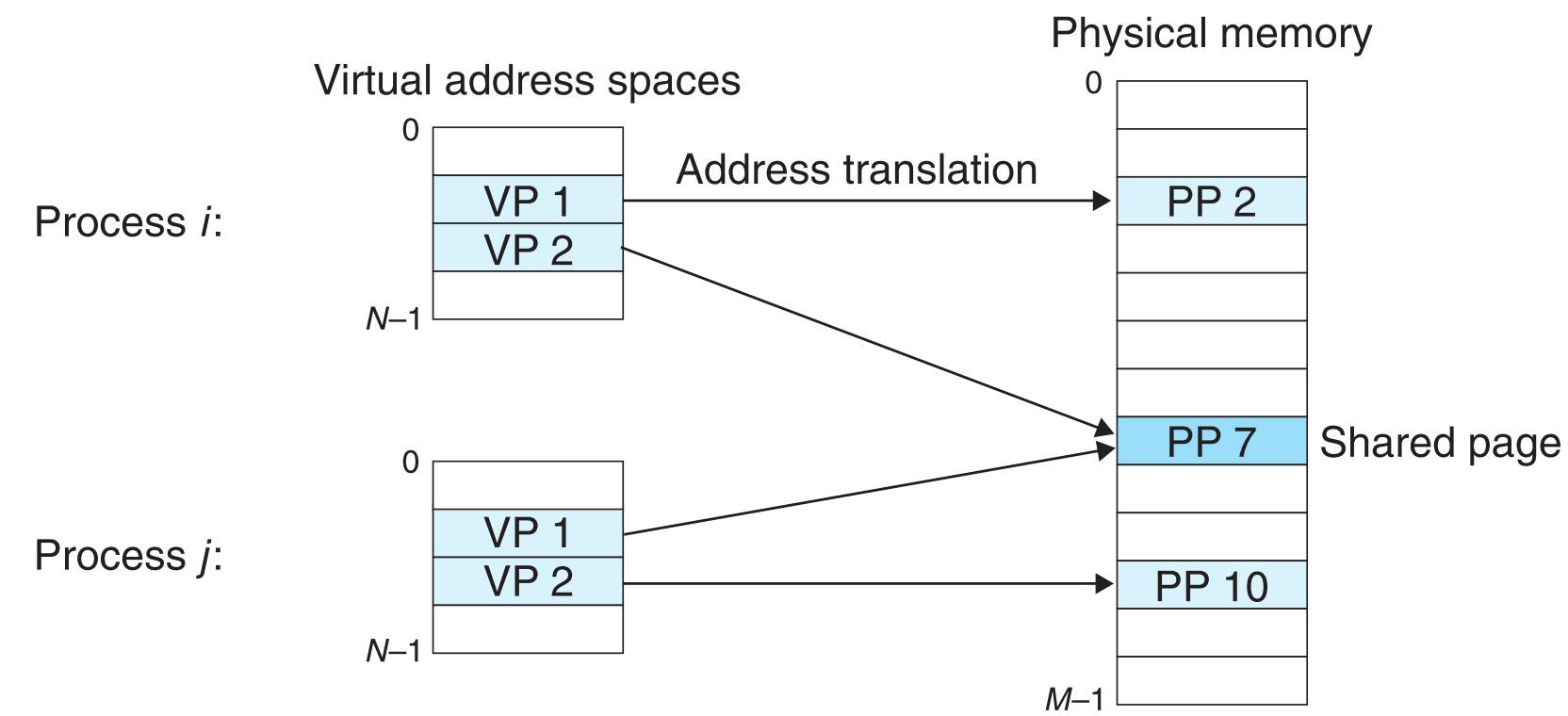
可以看到,实际情况下每一个进程的VM空间中实际cache到PM中的VP数量是远小于整个PM空间的。另外还能观察到,两个进程的VP映射到PM上可能离的很远(如图PP2和PP10),一个进程的两个VP也可能离得很远(如图PP2和PP7),可以看出某VP具体映射到PM上的哪个位置是不确定的,同时两个进程的VP还可能映射到同一个PP上(如图PP7)。
在 demand paging 和 每个进程拥有独立的虚拟地址空间 的共同作用下,VM技术极大的简化了内存管理:
- 简化linking
分离虚拟地址空间使得每一个进程都身处于同一格式的内存镜像中,这样一来,它们只需要沉浸在自己的小世界里,组织好自己的结构,而不需要去纠结自己在PM中的组织问题,因为那是VM机制要管的事。这样一来,linker的工作也被极大的简化了,因为在它眼中,内存就长这个样子
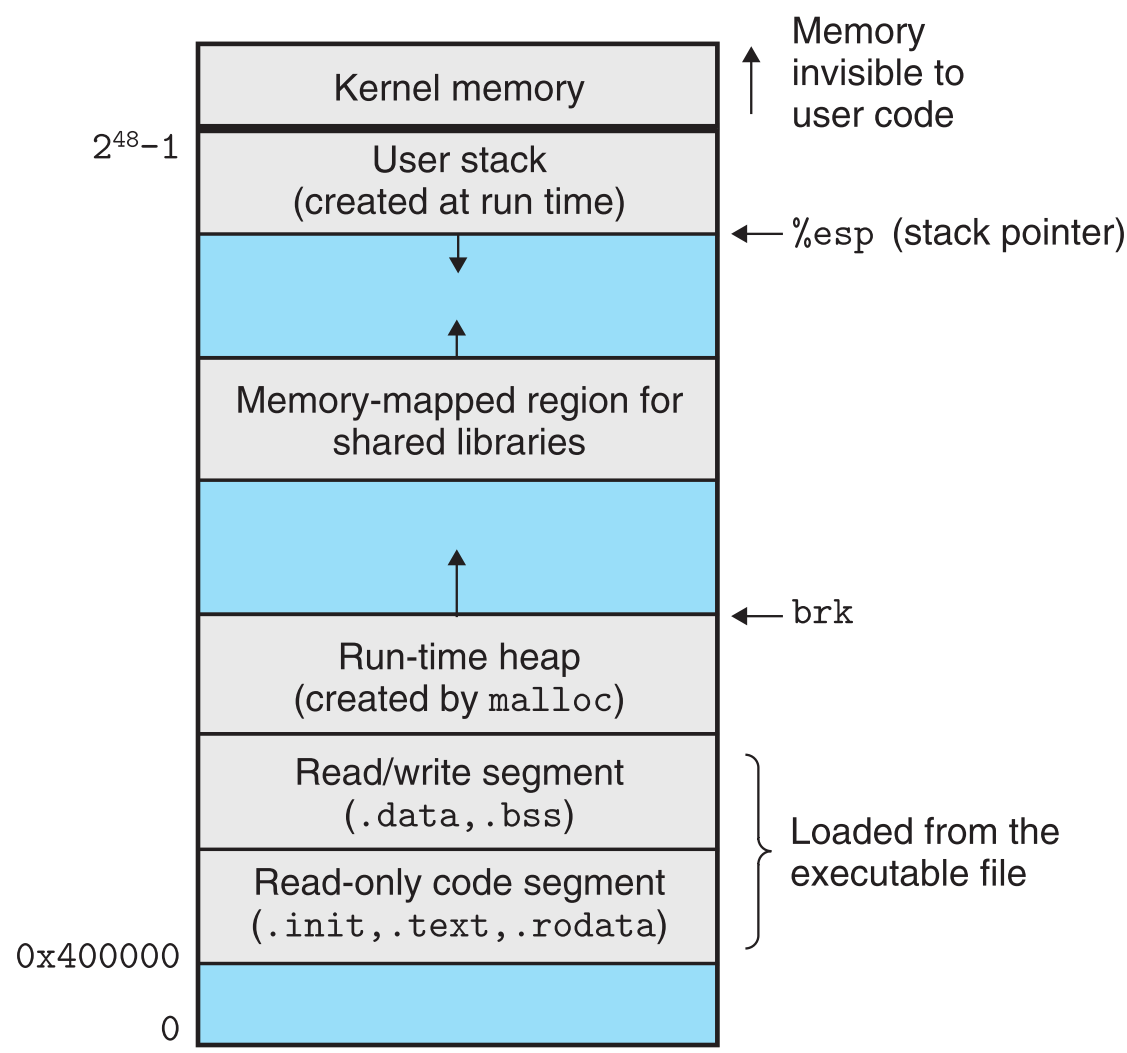
我们知道【executable file的结构】与【运行中的程序在内存中的结构】是存在映射关系的(提供映射关系的是header table,在《Linking》-loading中有详细介绍),也就是说linker只需要按照上面这个统一的格式来生成与其对应的executable file就行了。(想想如果没有VM抽象出上面这个统一的虚拟内存地址空间,linker要多做多少事?)
- 简化loading
假定我们现在已经有一个executable文件,想要把它load到一个刚创建的进程中。
首先loader会去allocate一组连续的virtual pages(足够装下程序的整个code和data字段),再将这个变化更新到该process的page table中(对每个刚申请的VP所对应的PTE:valid=0,VP指向disk上该page对应的地址段)就OK了,注意loader此时并不会将任何一个virtual page给cache(page in)到PM中(即不会对PM进行初始化),是否cache某个page完全是看之后程序是否访问了这个page,且page in的行为总是由VM系统来完成。
上述:loader先申请一组连续的virtual pages,然后建立这些pages与disk上一组地址段的映射,这一过程叫做memory mapping,之后还会详细介绍。
简化sharing
前面我们已经知道到分属于两个进程的两个VP可以映射到同一个PP。
这样一来某些常用函数(比如printf)就不需要每个进程都copy一份了,而是只需要有一个进程将常用函数cache到PM中,之后让所有使用它的其他VP都指向那个PP即可。简化内存分配
使用malloc函数后,操作系统会创建一组连续的VPs(足以容纳我们申请的内存大小),每当一个VP被访问,它就会被cache到PM中的随机位置,这就像是把这些VPs打散,随机的映射到PM中一样。因为根据page table的原理,根本没有必要把连续VPs映射到连续的PPs。
9.5 VM as a Tool for Memory Protection
必须内存加以保护,用户态进程不能:
- 修改它的只读区域数据
- 访问内核中的任何数据
- 访问其他进程的私有空间
- 修改共享给其他进程的VP(除非其他进程明确允许)
给每一个进程抽象出独立的虚拟内存空间已经能够一定程度上保护内存了,为了提供更好的内存保护,我们可以改进一下page table,让它具有额外的访问控制能力。
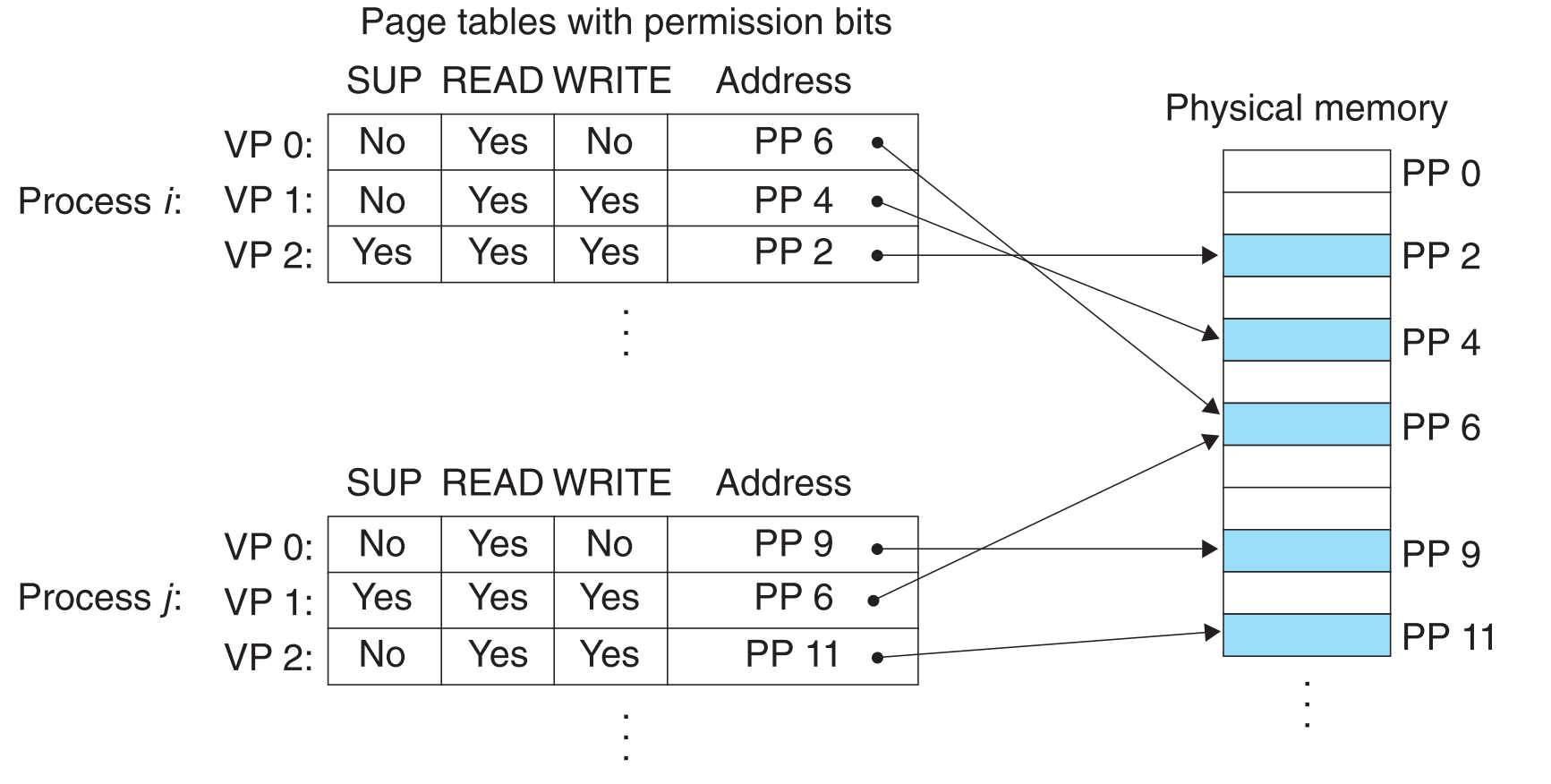
我们为每一个PTE增加了几个permission bits
| permission bit | 作用 |
|---|---|
| SUP | 访问这个VP是否需要内核权限 |
| READ | 该VP是否不能被读 |
| WRITE | 该VP是否不能被写 |
举例:假如进程 i 跑在用户态,则它不能读取VP0,不能对VP1读或者写,不能访问VP2.
如果某个进程对内存进行了违规访问,就会触发一个general protection fault,它会把控制转交给内核中的一个exception handler,该handler会发送一个SIGSEGV信号(默认动作为中止进程)给违例的进程,这种exception就是大名鼎鼎的segmentation fault。
9.6 Address Translation
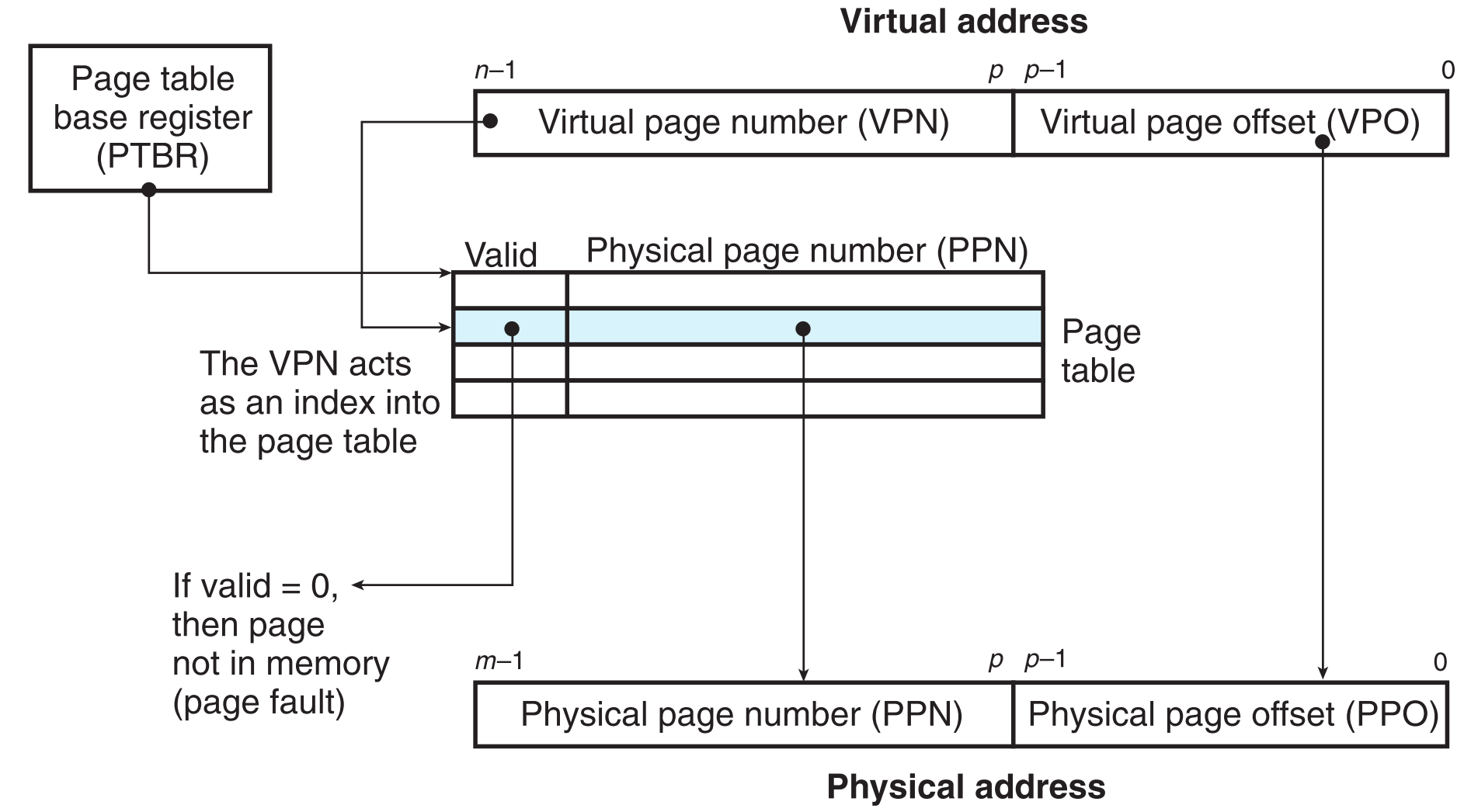
PTBR是一个CPU内部的控制寄存器,它总是指向当前进程的page table。
可以看到CPU发出的virtual address分为两个部分:VPN和VPO,MMU会根据它的VPN来选择page table中对应的PTE(VPN与PTE之间是一一对应的,VPN0对应PTE0、VPN1对应PTE1),如果该PTE的valid bit为0,则产生page fault,否则读取PTE中的PPN(Physical page number,即物理内存中对应的page number),然后把Virtual address的VPN改为PPN后,重新发送指令,这次直接将其发送给物理内存。
最后的效果是指令可以通过PPN在PM中找到对应的physical page,然后通过offset(注意VPO和PPO是相同的)定位具体数据。
下面再讨论的具体一些:
page hit
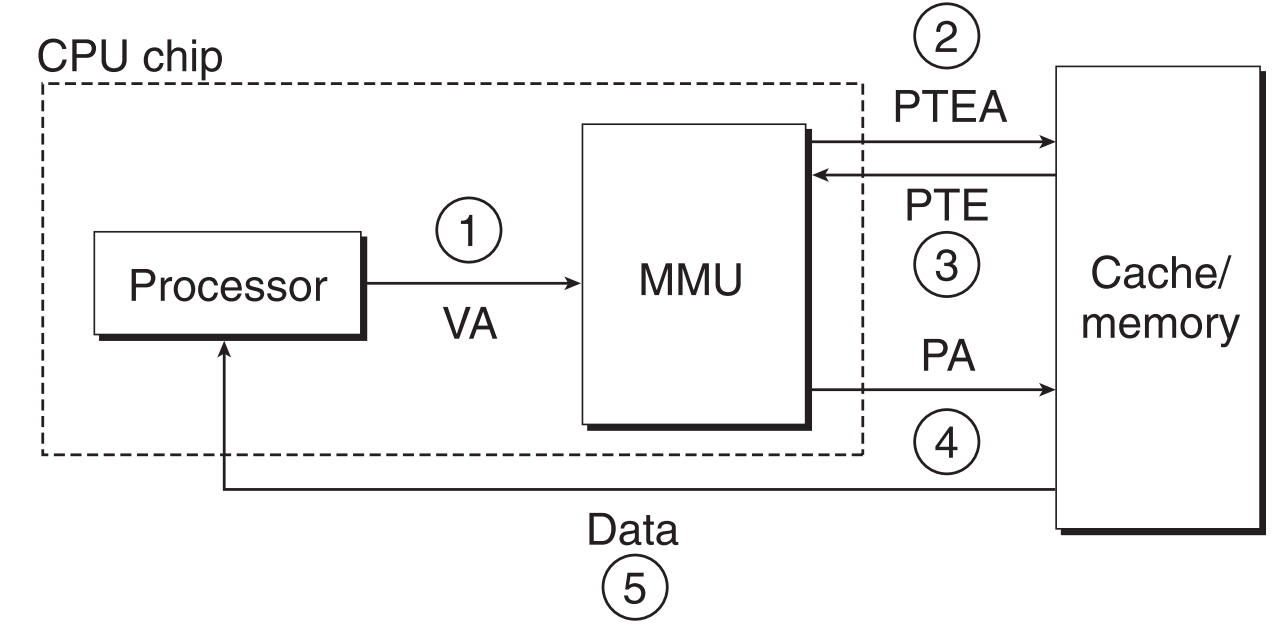
- 处理器把VA发送到MMU
- MMU拿到VA中的VPN,将这个VPN发送给常驻于物理内存中的page table
- page table把查表的结果(PPN)返回给MMU
- MMU使用这个PPN生成物理地址,直接发送到PM,这就完成了一个page hit。
不同于完全由硬件完成的page hit,page fault需要由硬件和内核协作完成。
page fault
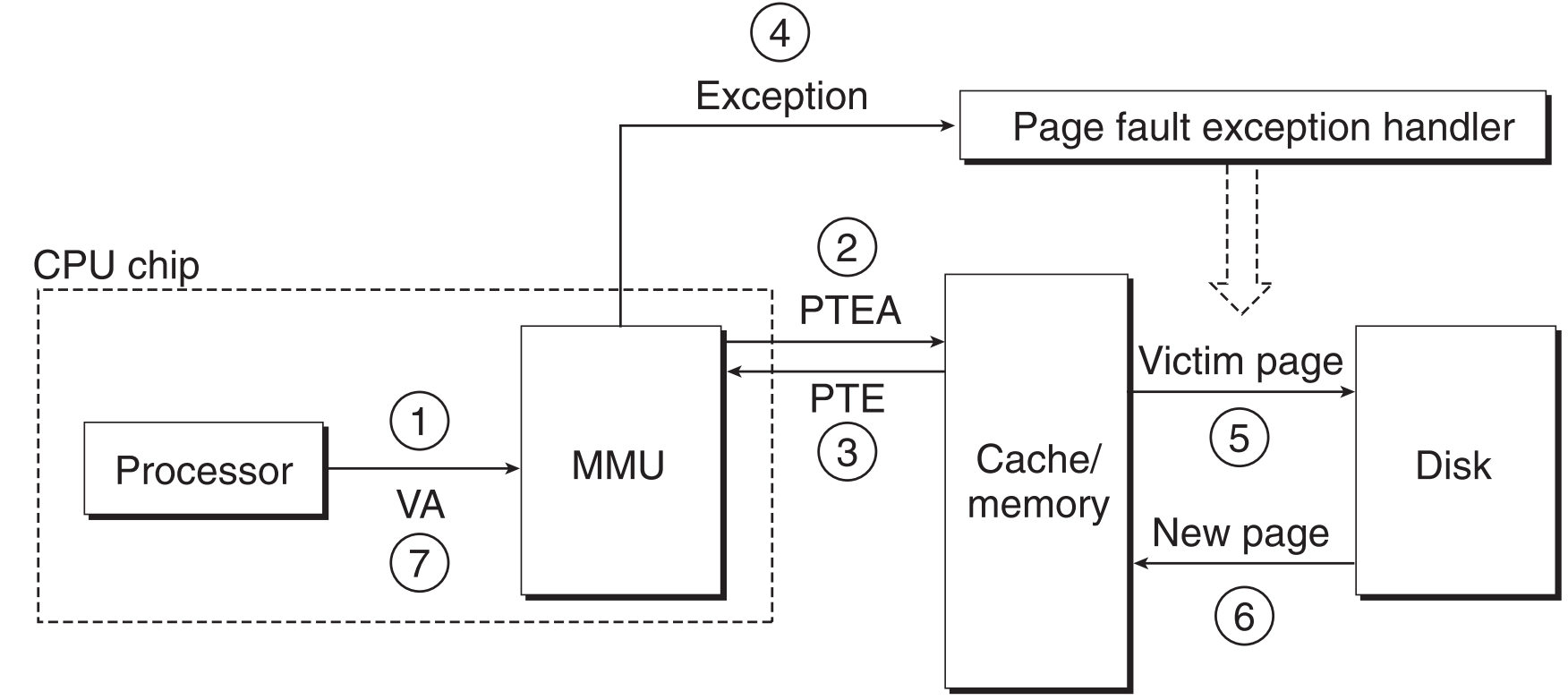
- CPU把VA发送到MMU
- MMU拿到VA中的VPN,将这个VPN发送给常驻于物理内存中的page table
- 查询发现VPN对应的PTE的valid bit为0,就直接触发exception,CPU调用内核的page fault handler
- page fault handler在PM中选择一个victim page,检查这个page在PM中缓存期间有没有被改动过,如果被改动过,就将这个page更新到disk中,若没被改动过,则直接进入下一步
- page fault handler将需要访问的page从disk中page in到PM中,覆盖刚才选中的victim page
- 更新page table对应的PTEs
- page fault handler执行结束,将控制交还给引发page fault的指令,重新从它开始执行
- 这次目标page已经被缓存了,同page hit的完整流程
9.6.1 Integrating Caches and VM
讨论了这么多,都是假定CPU的下一级直接就是主存,如果它们之间存在SRAM,那么数据在SRAM上cache是用Virtual address还是Physical address呢?
答案是:Physical address,在指令把VA发离CPU之前就把它转换为PA。
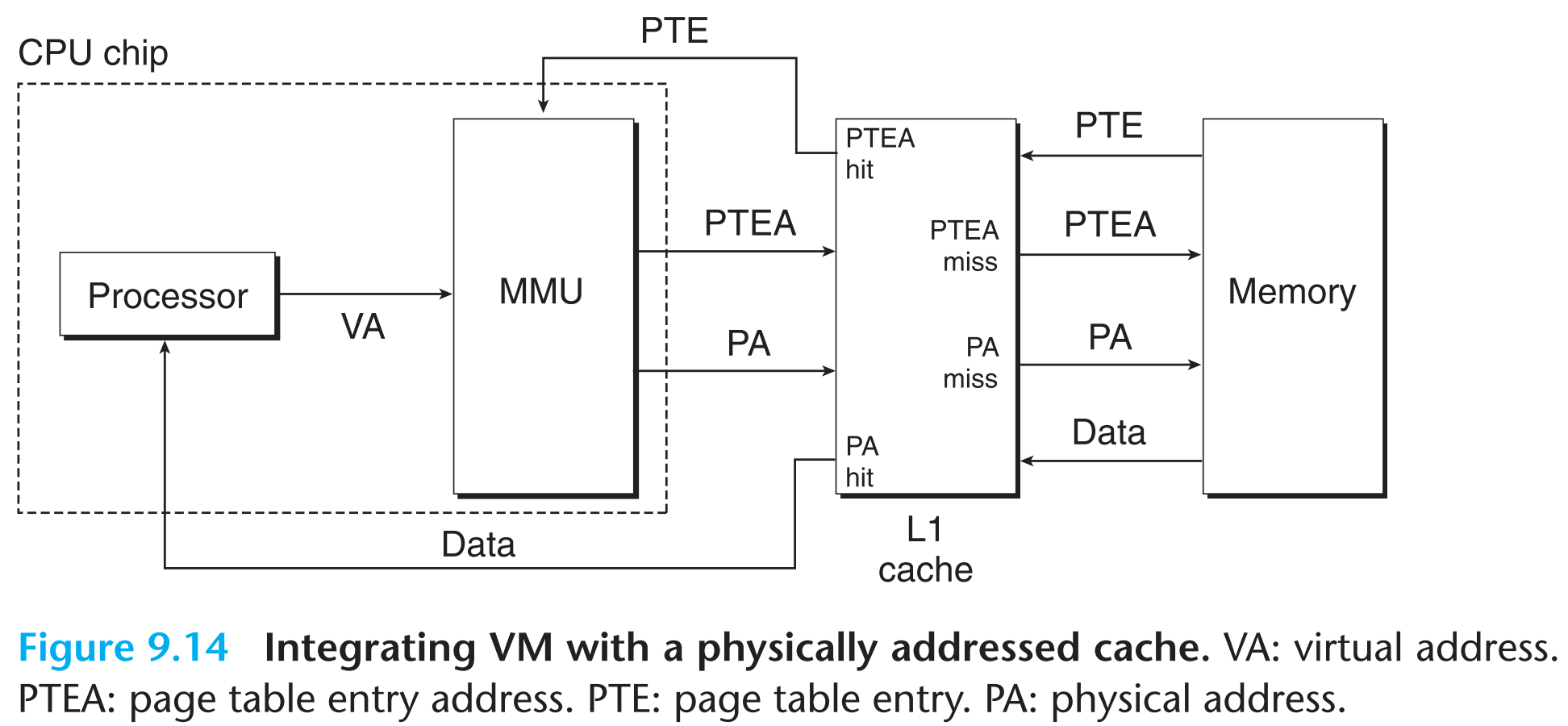
在SRAM中,每一个进程都有一个属于自己的小区域,并且与两个VP可以指向一个PP一样,SRAM中的进程也可共享数据。因为指令地址脱离CPU后就以物理地址的形式存在了,因此每一个SRAM都可以被看作是一个小型的PM,前面讨论的关于PM的性质在SRAM中都适用。
9.6.2 Speeding Up Address Translation with a TLB
其实上面我们讨论的地址转换,相当于每条指令都得先被发送到PM一次,然后PM把返回值发送给MMU,接着MMU再发送一次转换后的地址到PM,这其实要消耗非常多的时间。
为了提速,CPU设计者在MMU中加上了一个小的cache,专用于缓存page table,叫做 translation lookaside buffer (TLB) ,TLB的每一个项都是用虚拟地址标识的,格式如下:
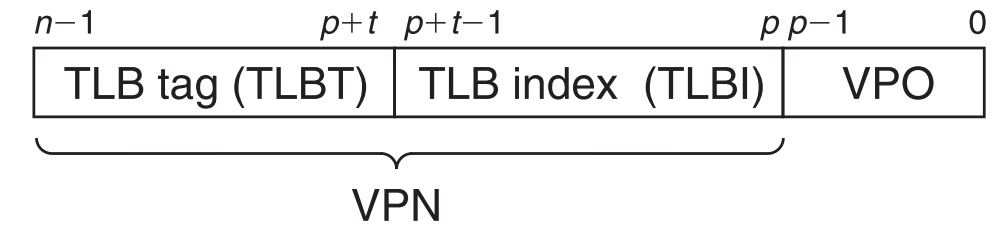
与我们之间讨论的SRAM cache matching相同(《memory hierarchy -> cache hit原理》),携带VA的指令先通过TLB index选择set,再通过TLB tag选择line,如果前两步都match了,这次就算是cache hit,最后通过VPO定位具体数据,拿到对应的PA。
9.6.2.1 TLB hit
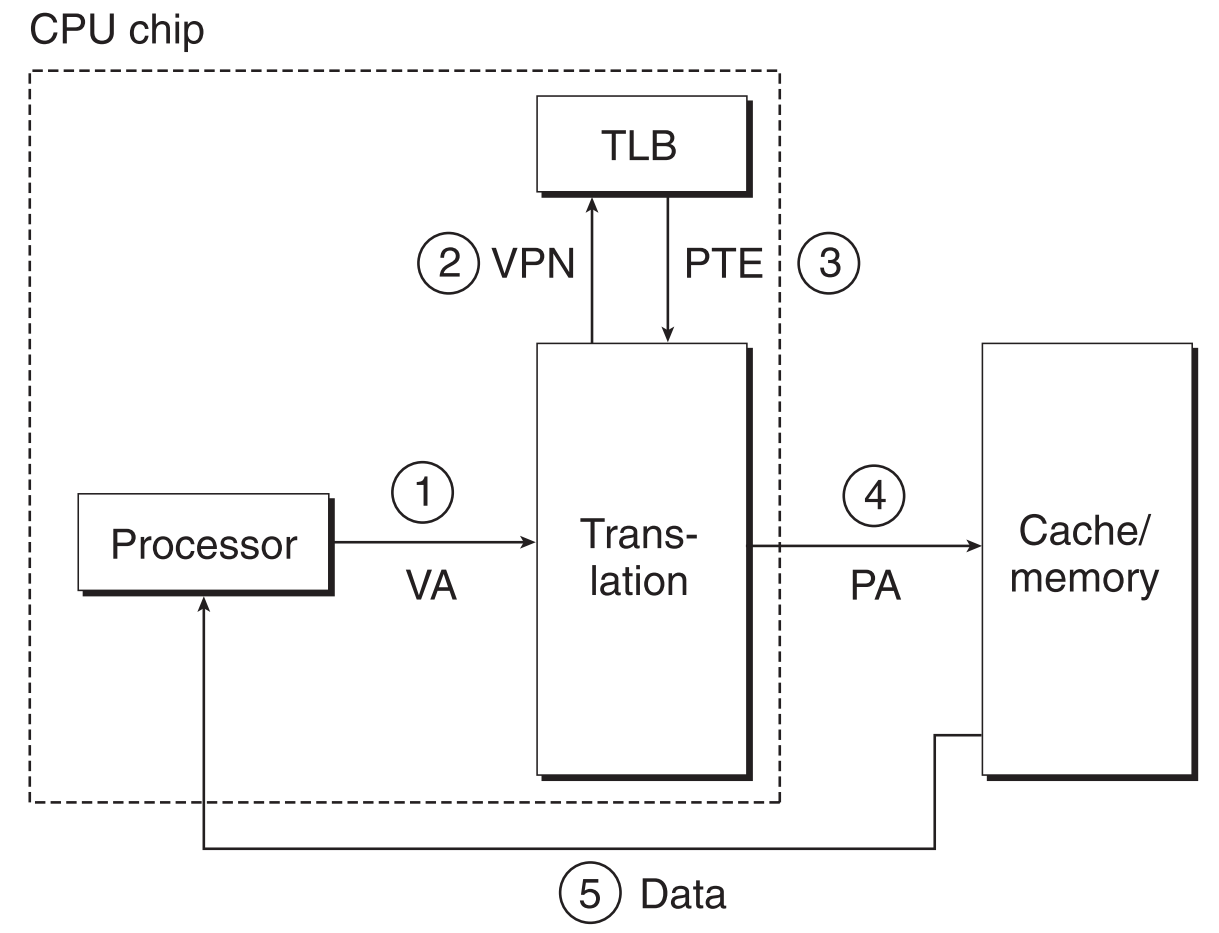
- CPU生成virtual address,发送给MMU
2&3. MMU从TLB中取到对应的PTE
MMU把VA转换为PA,然后发送给PM
PM执行指令的内容,将结果返回给CPU
9.6.2.2 TLB miss
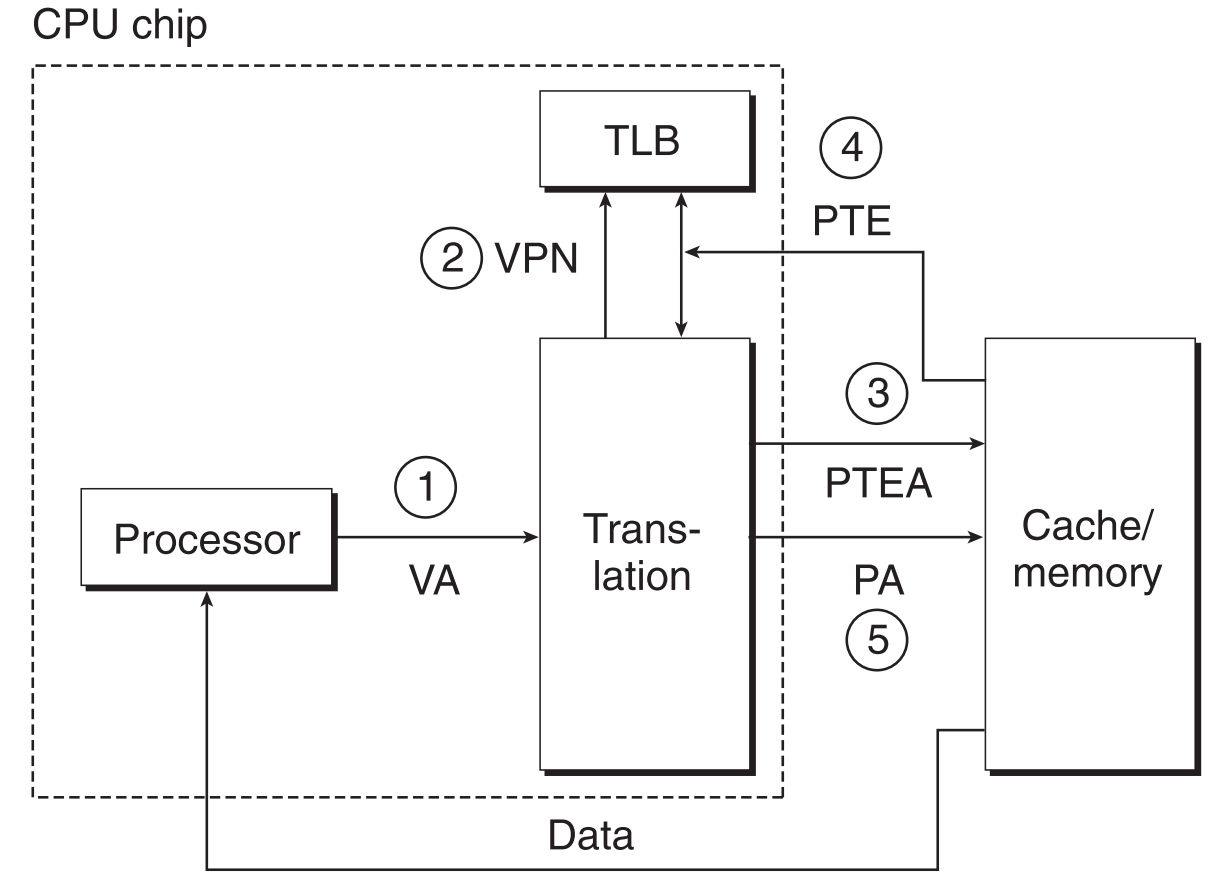
- CPU生成virtual address
- MMU先去TLB中找对应的PTE,但没找到
- MMU只好自己拿着VPN去PM中查物理地址了
- 查到后,将这次查询的结果缓存到TLB中
- MMU进行地址转换,然后将物理地址发送到PM
- PM执行指令的内容,将结果返回给CPU
9.6.3 Multi-Level Page Tables
page table是常驻在物理内存中的,且大多数情况下,page table的绝大部分都是unallocated,这就造成了很大的资源浪费,毕竟物理内存是寸土寸金啊。
为了节省PM的资源,大神们发明了多级page tables
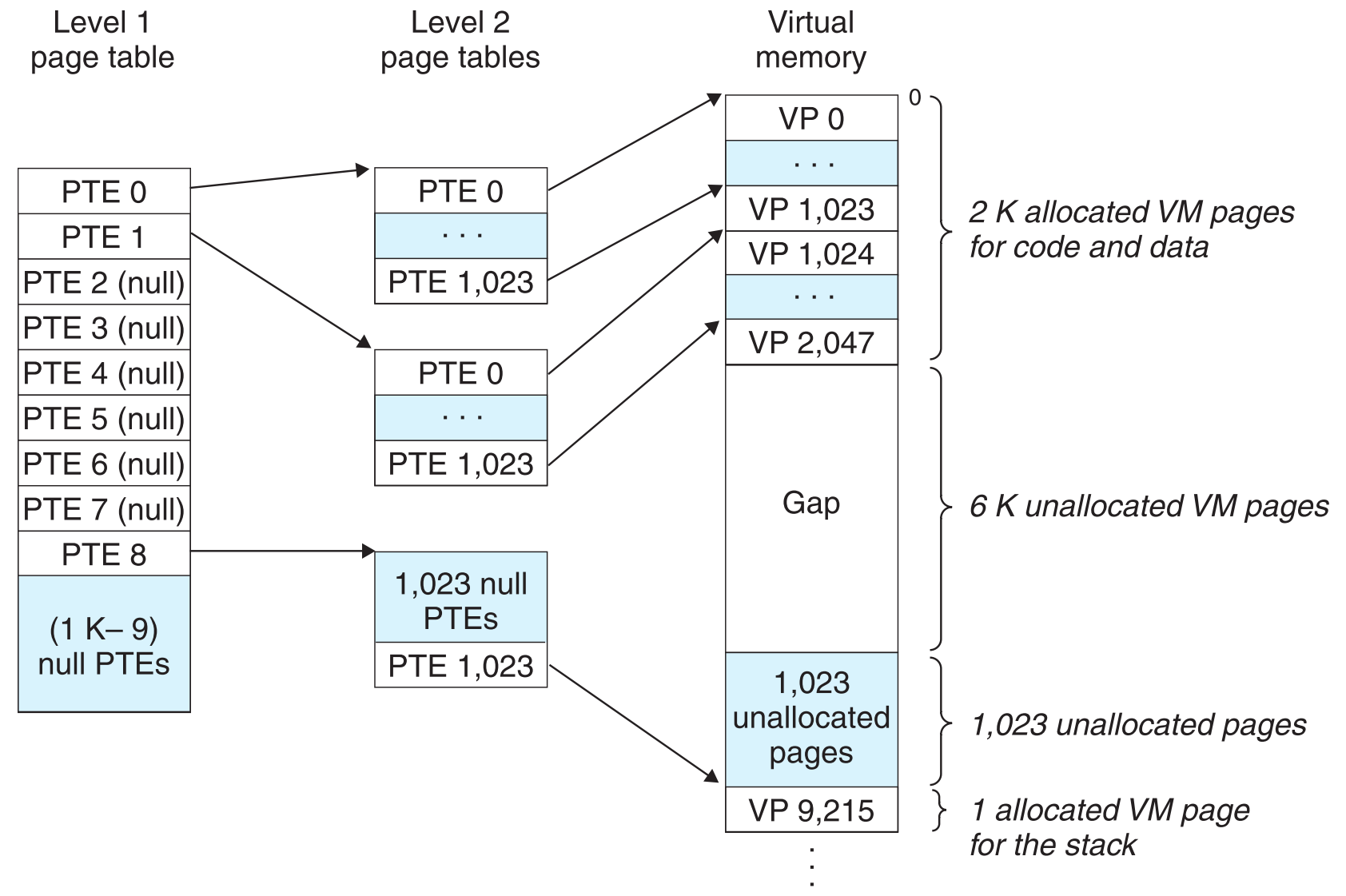
显然,我们只要让level 1的page table常驻在物理内存中即可,level 2的page tables则通过page in与page out的方式在需要时创建,这极大的减轻了物理内存的压力,也节省出了很多空间,但相应的会增加时间?
在多层page tables的背景下如何进行地址转换呢?
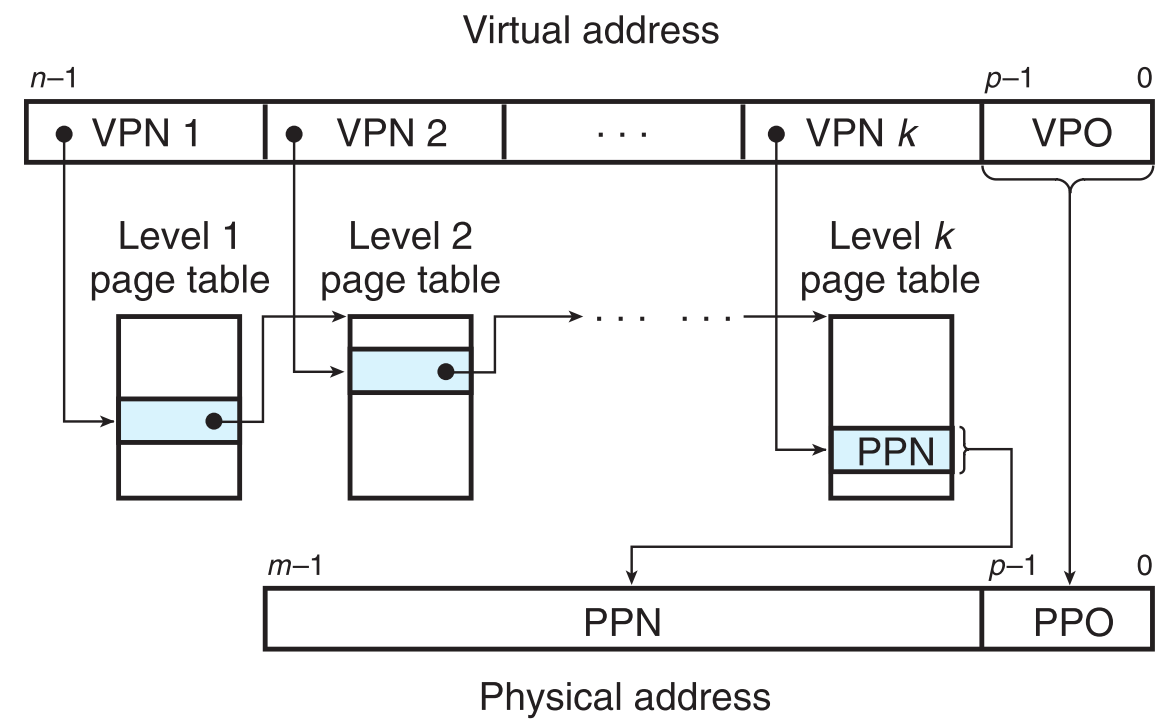
有小朋友就会问了,这VPN转换这么多层,是不是会太慢了?
其实不然,有了TLB技术,大多数情况下根本不需要去进行地址转换,在实际情况中,多级page tables与单个page table的效率几乎没有区别,Locality真是一个神奇的性质。TLB+多级页表,完美的配合,既节省了PM空间,又提升了地址转换的效率!
9.6.4 Sum Up!完整的地址转换过程
现在把上面的内容合并起来讨论
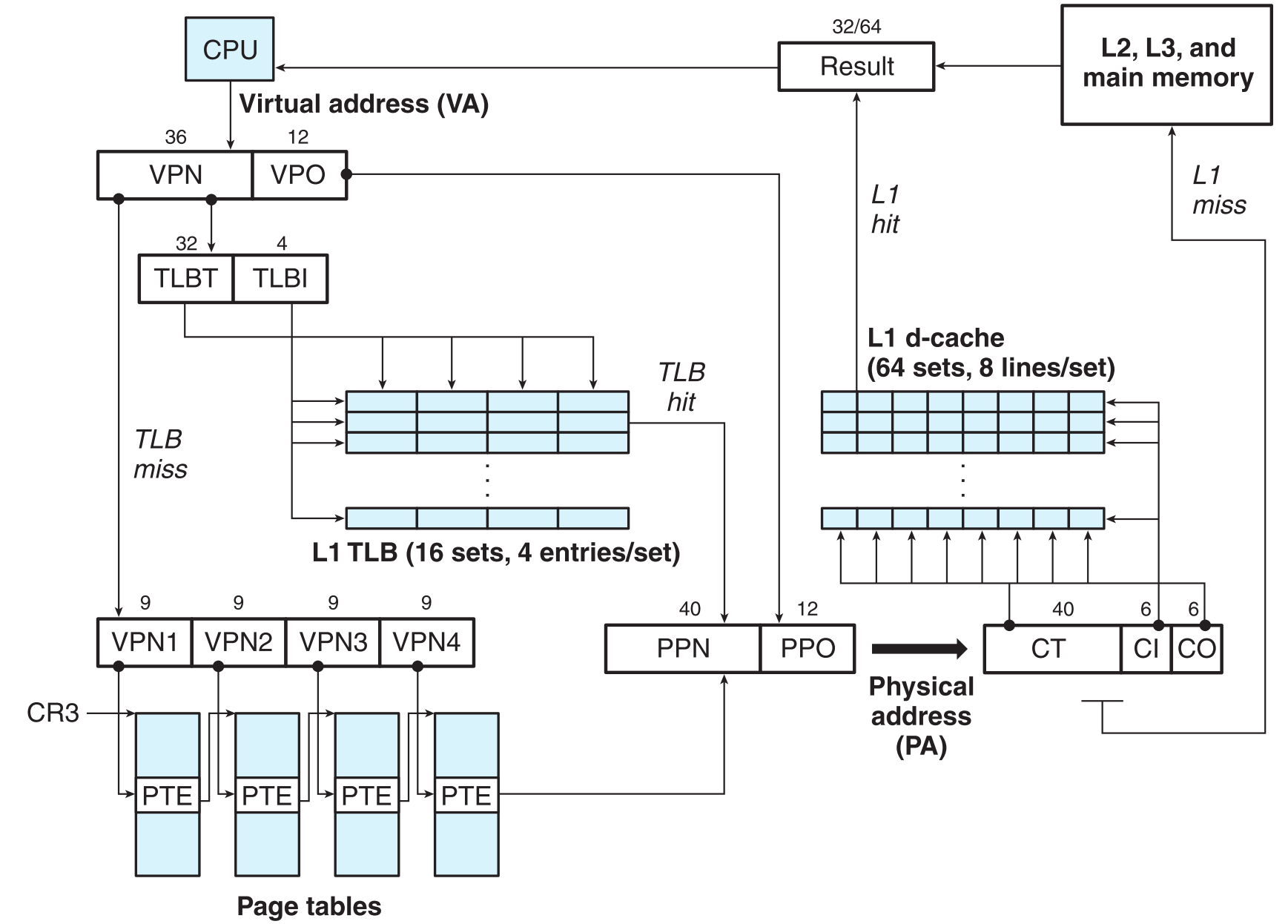
其中CT、CI、CO分别代表cache tag、cache index、cache offset
现在我们可以看到更加详细的虚拟内存图了
9.7 Memory Mapping
将disk中一段内容映射到虚拟内存中一串连续的页中,这个过程就叫memory mapping,disk上能够与虚拟内存映射的object分为两种:
普通文件
比如executable object file等,这个file会被分为N个pages,每一个page都是其对应VP的初始内容。因为demand paging技术,在CPU真正“触碰“到某一个页之前(即CPU请求的virtual address落在某一个未被cache的VP区域内之前),这个页是不会被page in到物理内存中的。如果申请的虚拟内存空间大于其对应文件,多出的虚拟内存空间会用0填充
匿名文件(Anonymous file)
匿名文件是由内核所创建的,它的内容为全0。
如果CPU“触摸”了匿名文件中的某个VP所属的区域,内核就会去PM中寻找一个victim page,如果这个victim page is dirty(即这个页面在被缓存后数据被改动过,《memory hierarchy》-写策略中有详述),就会把它更新到disk上,然后再用全0覆盖这个victim page;否则就直接用全0(匿名文件任何一页的内容)覆盖这个victim page,并更新page table中对应的PTE。
因此匿名文件存在就是为了把一个已经被cached的页给uncache掉。
这些映射到匿名文件的VP被称为demand-zero pages。
无论是以上的哪种文件,一旦属于它的VPs被初始化了,它就会通过一个内核维护的文件:swap file,在disk和memory之间被来回传输。swap file中总是维护着当前进程所能够申请的最大数量的VPs。因此,swap file的大小决定了VM的空间大小。
9.7.1 Shared Objects Revisited
前面我们已经介绍过,如果多个进程各自的某一块空间映射同一片disk区域,只要它们都将这块区域标识为shared,则在物理内存中只需要缓存一份这片disk区域的数据,之后所有进程都共享物理内存的这一片区域即可。
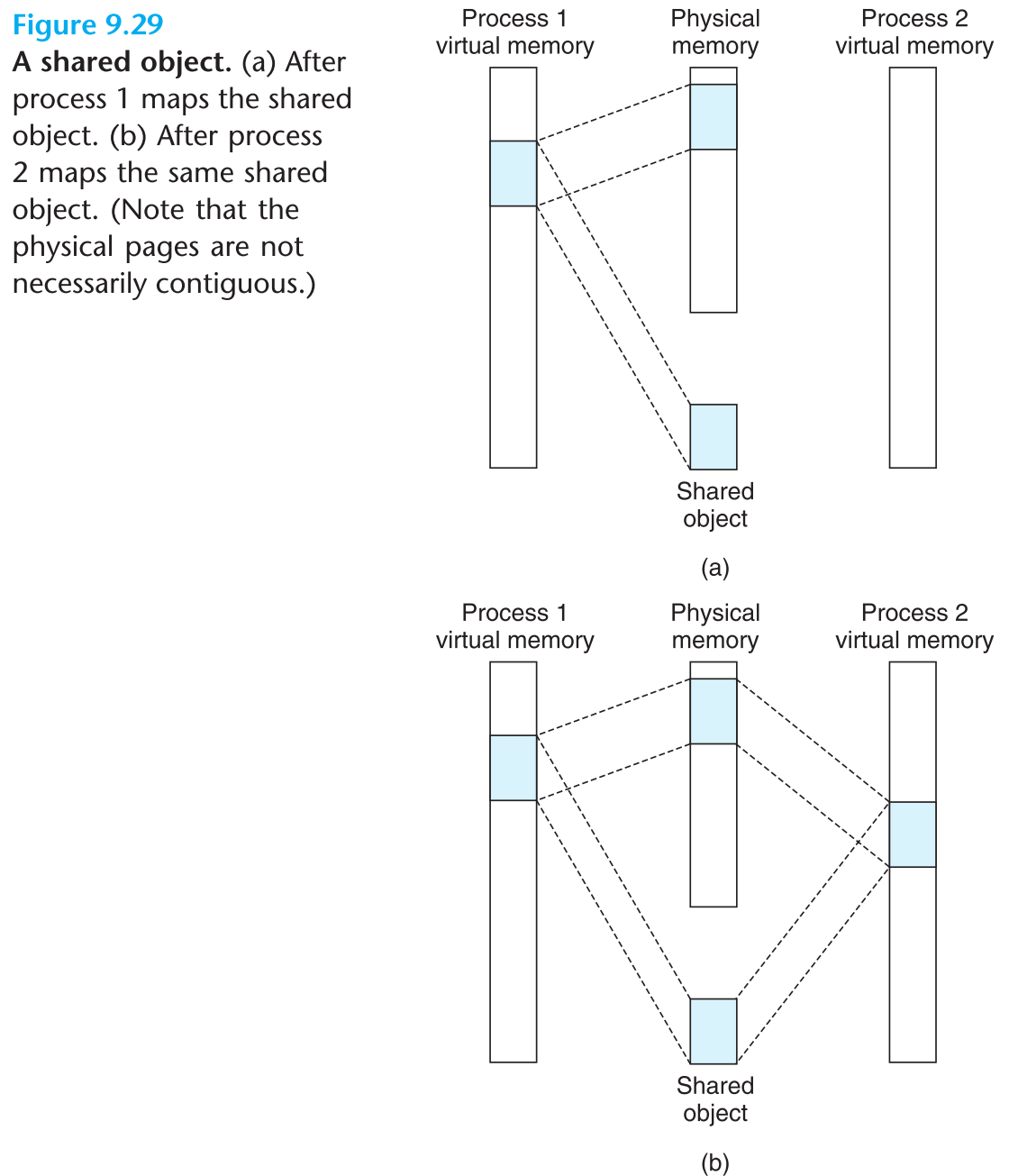
事实上,当多个进程各自的某一块空间映射到同一片disk区域,但是它们都将这块区域标识为私有时,物理内存中一开始仍然只需要缓存一份这片区域的数据,然后让所有进程共享这一片物理内存块。
可是这样做不就相当于数据非私有的了?
别急,我们先不考虑写入的情况,也就是说只要没有任何一个进程对这块区域进行写操作,它们完全可以share这一块区域。
那如果有进程对这区域write怎么办呢?
答案是使用copy-on-write技术。
这些存在共享区域的进程都会在自己的page table中把属于自己共享区域的所有PTEs都标为只读,并且会给整个共享区域做一个标识:private copy-on-write。
当这些进程中的任意一个对自己的共享区域进行写操作时,因为是写只读数据,会触发一个protection fault,fault handler觉察到这个写操作是在private copy-on-write区域中的,就不会报错,而是:
它先去PM中找到该共享区域的缓存,把写操作目标地址所属的整个page(注意只是一个page)从中复制一份放到PM的其他位置,然后更新该进程的page table:让写操作目标地址对应的PTE指向刚复制的新page,并将该page的写操作开放,接着CPU重新执行一次写操作,这次就把数据写到了刚生成的私有page上了。这样就抽象出了进程私有内存空间的感觉。
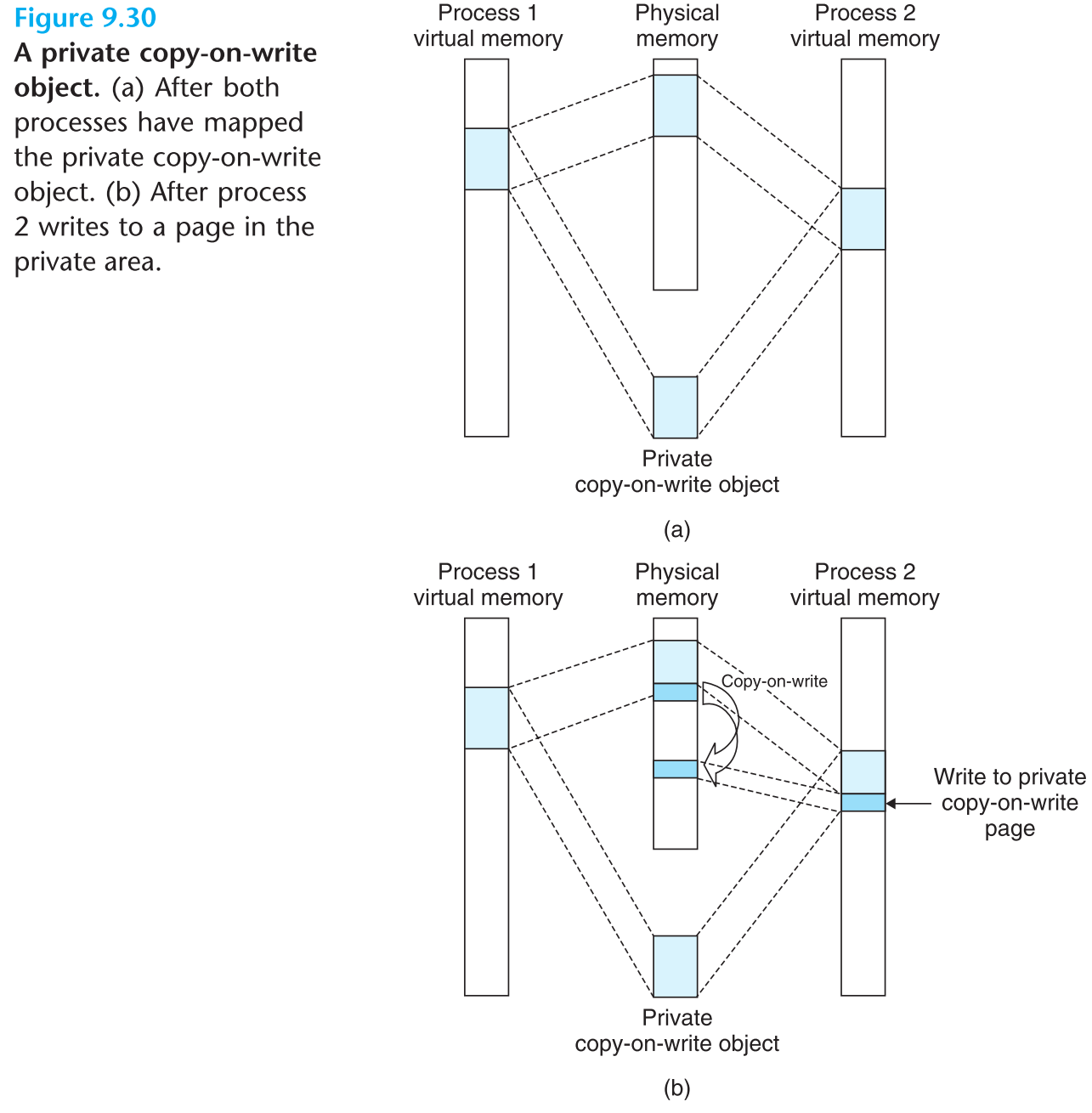
这种多个进程,当它们各自的某一块私有区域都映射到同一块disk区域上时,可以先把这一块区域视为公有,只将一份该区域的数据缓存到PM中。如果所有进程都只是读取该区域的内容,那么完美运行;只有当某一个进程对该区域write时,才会利用内存保护的handler把该write目标地址所属的page从共享区域复制出来一份,然后重新执行一次对该复制出的副本page的write,从而把这次write操作给私有化。这种copy-on-write策略极大的节省了珍贵的物理内存空间。
事实上fork函数的实现就是基于copy-on-write,调用它时,系统只需要创建一个当前进程的副本进程(当然要赋予新的PID),然后把副本进程的全部空间设为private copy-on-write,所有pages设为只读,这就抽象出了两个独立的进程。
有了虚拟内存合memory mapping的基础,我们还可以完善execve()的原理。
execve()的功能是先创建一个当前进程的子进程,然后在子进程中执行另一个程序
9.7.2 The execve Function Revisited
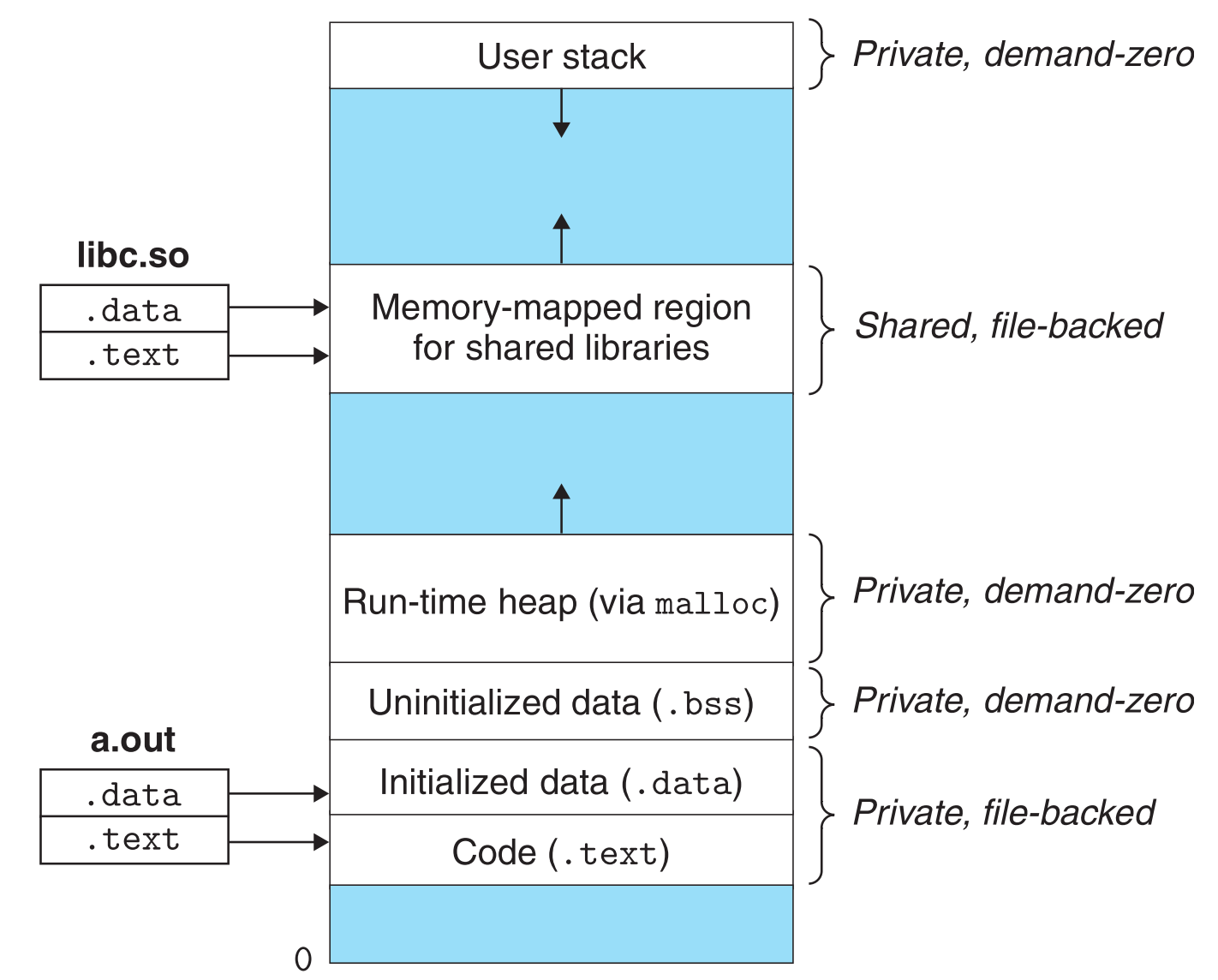
假如execve()在当前进程中被调用,它的参数为a.out,那么先要执行一个fork(),然后系统会对新进程进行如下动作:
- 初始化进程的虚拟内存。因为fork()创建的新进程是原进程的副本,因此要先把新进程中的数据给清空
- 建立私有区域的映射。以将要加载的程序a.out为蓝本,在新进程中创建对应的数据结构(code区、data区、bss以及栈),并将进程中所有的区域都标识为private copy-on-write。
将disk上程序文件的data部分和code部分映射到VM的data区和text区。
将VM的bss、stack和heap区映射到disk上的anonymous file上(即映射为全0) - 建立共享区域的映射。如果程序使用了dll,则这些dll被动态链接的过程,就是系统找到它们在disk上的位置,然后将它们映射到VM中共享区域的过程。
- 控制交还。将program counter指向子进程代码的入口点。
最终子进程内存如下图所示
9.8 Dynamic Memory Allocation
假如我们要创建一个数组,它的大小为n,而这个n在写程序时是不确定的(比如要从键盘读入n,或n是在程序运行时才被计算出来的),有两种方案可供使用:
- 申请一个固定长度的超长全局数组(浪费巨量空间)
- 使用动态内存分配
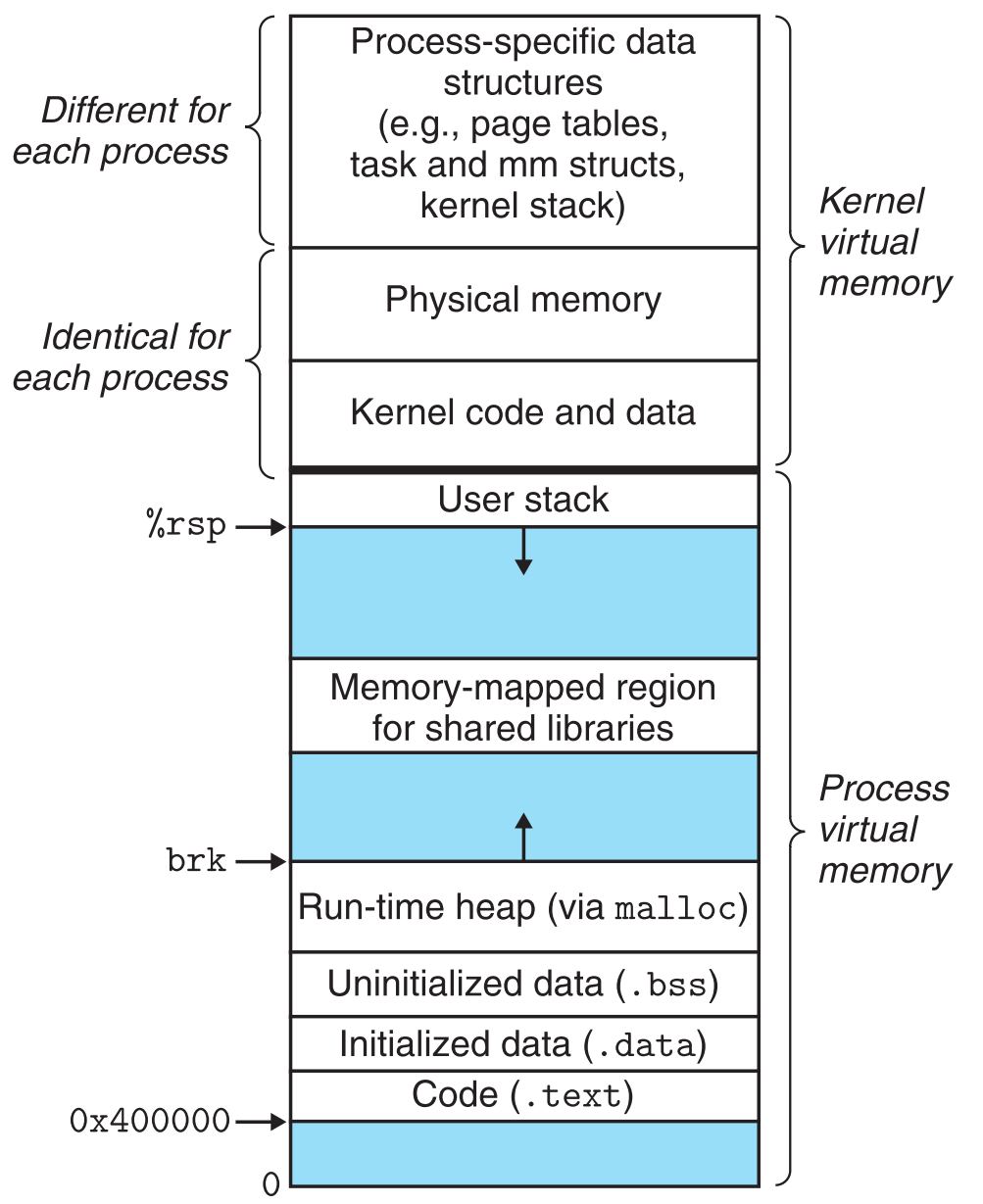
我们可以很方便的借助allocator来实现动态内存分配,内核为每一个进程维护了一个指针brk,它总是指向本进程中heap的首地址。allocator借助它来定位heap的位置。
allocator总是将heap视为一个个大小不一的块,每一个块都是其VM中一段连续的地址空间,它有两种状态:allocated or free。
如果某一个块被allocated了,说明应用程序已经占用这个块,它之后可以往里面写入数据了(注意某个block被allocate后其中可能已经有上次使用留下的垃圾数据,也可能是全0,我们无法确定,因此动态分配内存后一定要对空间初始化)。
若某一个块是free的,说明它还没有被占用。
有两种allocators,它们之间的区别只在于负责执行free的实体不同。
explicit allocator。它要求应用程序显式的free内存,比如C中的malloc,用完后必须显式的free掉申请的内存;比如C++的new,用完后必须要用delete来释放内存。
implicit allocator。 这种allocator会不停地寻找不再被使用的动态内存,将它们free掉,因此它还有一个别名:garbage collector,java就使用了这种allocator。
其实allocator不光能管理heap,还有其他作用。
9.8.1 The malloc and free Functions
假设每个格子存放一个字(4 bytes)的数据,块之间用粗线隔开,示例如下:
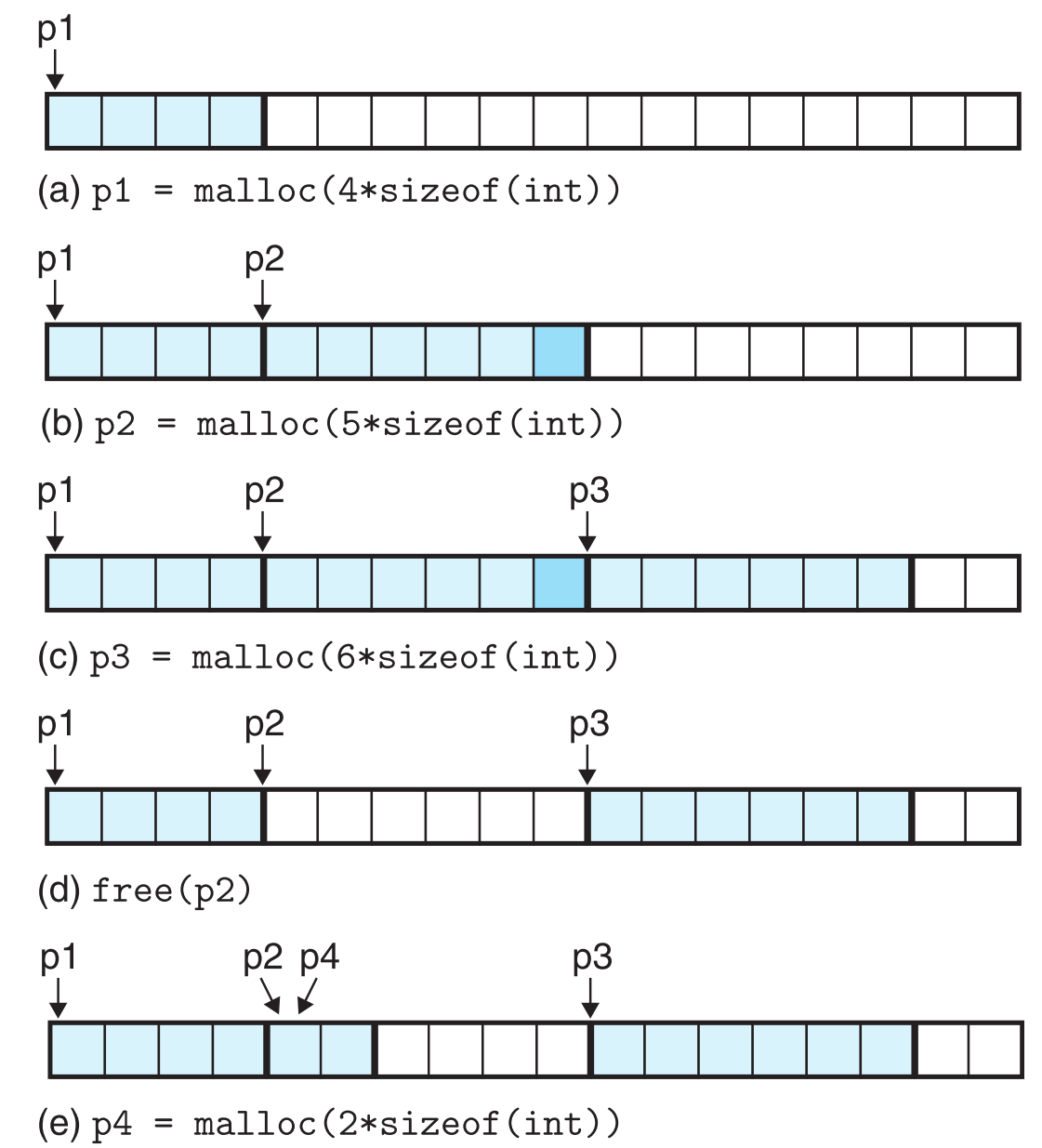
要注意的是(d)步骤,把p2给free掉后,p2依然指向原来的位置,但这时它已经是垃圾了,且如果之后不小心使用了它,会产生难以修复的bug,这也是为什么free掉指针后要将它置为NULL的原因。
9.8.2 Allocator Requirements and Goals
Allocator在设计上有很多要求,比如数据对齐(为了能处理任意类型的变量),不能为了节省空间(填补block之间的空隙)而移动allocated block。
所有的这些要求都是为了实现两个目标:
- 最大化吞吐量(maximize throughput)
比如一个allocator能在1s内完成500次allocate和500次free,它的吞吐量就是1000/s。为了提高吞吐量,可以降低每一次allocate和free操作所需要的时间。 - 最大化内存利用(maximize memory utilization)
allocator本身也是程序,那么利用好每一点内存当然也是它的设计目标。
这两个目标是互相制约的,因此应该尽最大努力在它们之间寻找一个平衡点。
9.8.3 Fragmentation
heap在经过多次的allocate&free后,必然会有很多夹在两块allocated blocks之间的free block,由于它们占有的空间太小了,以至于几乎每一次申请内存都不会轮到它们。这些位置尴尬的free blocks就被称为Fragmentations,它们就是实现最大化内存利用的绊脚石。
fragmentation被分为两种:
Internal fragmentation
比如allocator为了空间对齐,会在申请的实际空间后追加一点空白区;或者申请的heap空间小于allocator规定的最小值,也会在其后追加空白区以满足最小值要求。这两种情况产生的内存空隙称为internal fragmentation。External fragmentation
比如我们要动态申请大小为n的数组,此时整个heap中所有的free blocks加起来>n,但没有任何一个单独的block是大于n的,在这种情况下heap中所有的free blocks都改名叫做external fragmentation。
可以看出量化External fragmentation是非常困难的,因为它相比internal fragmentation的计算(申请后实际空间的大小 - 申请的空间大小),还多了一个参数: 未来,如果之后的每一次申请内存的大小都小于任何一个free block,那它就根本不存在External fragmentations了,但问题是,我们步可能预知未来。
9.8.4 Implementation Issues
为了在提高吞吐量和提高内存利用之间寻找一个平衡,实现allocator时必须考虑以下问题:
- Free block organization。如何动态维护所有的free blocks?
- Placement。我们应该把刚申请的内存放在哪个free block中?
- Splitting。完成Placement之后,如果该free block中多出了很大空间怎么办?
- Coalescing。如何处理一个刚刚被free的block,它旁边有没有free的block,能否把它们合为一个大的block?
为了解决上述问题,我们先来了解一下free block的结构。
9.8.5 Implicit Free Lists
这是一种heap中简单的block结构

进而根据这样的结构,heap就可以被分为一系列free和allocated块的组合了。(block之间以粗线分隔)

为啥叫这样的block为implicit free lists呢?
因为以此block结构组成的heap中,所有的free blocks都可以被隐式的追踪到(方法是遍历所有blocks,通过它们的header的最低一个位判断是否未free block,遍历结束的标志是某个block size为0)。
这种结构最大的优点就是简单,缺点也很明显,每次追踪free block都要消耗大量的时间。
无论是基于alignment还是allocator本身设计的要求,minimum block size是allocator设计中一个必然存在的条件,没有任何一个block能够小于这个size。
9.8.6 Placing Allocated Blocks
每次程序动态申请内存时,假定为k bytes,allocator会在heap中寻找大于k bytes的free block,然后把它明确为allocated状态。问题是free block不一定只有一个,当有多个时,该选择哪一个free block呢?
有三种placement policy:
- first fit
顾名思义,直接选择第一个满足要求的free block。
优点: 会在list尾部留出大块的free block
缺点: 会在list的前部留下许多小的fragmentations,导致之后的搜索时间变长(因为每次都会从头开始搜索) - next fit
与first fit类型,区别在于每次搜索完成后,下一次搜索从上次的结束位置开始。
优点: 每次不用从头开始搜索,即使list前部有很多细碎的fragmentations也不会影响其之后的搜索时间
缺点:内存利用率低 - best fit
搜索最小的满足要求的free blck。
优点: 比first fit和next fit的内存利用率都要高
缺点: 如果应用在implicit free list结构上,它的搜索时间会非常久
内存空间非常珍贵,因此使用best fit比较合理。为了降低它的搜索时间,大神们为它量身定做了一种block格式。
《9.9.11 Segregated Free Lists》
9.8.7 Splitting Free Blocks
当allocator定位到了一个free block时,这个free block有可能远大于申请的内存,这时它可以选择不管不顾直接用这块free block,这样虽然实现起来简单了,却会留下许多的internal fragmentations。因此碰到这样的情况,allocator可以选择把free block多出的那部分切掉,让它自立门户,剩余的部分则刚好与要申请的内存大小匹配(稍微大一点作为padding)。
9.8.8 Coalescing Free Blocks
有时候会碰到这样的情况

一段连续的free space被划分成了多个free blocks,这会引发false fragmentation问题。因为完全有可能这个连续的free space很大,但其中的free blocks却都很小,进而都变成fragmentations了。
在这种情况下,allocator会对这些free blocks进行coalescing,即将它们合并为一个大的free block。
coalescing可能发生在两个时刻:
- immidiate coalescing。
每当对某个block进行free时,就将它与其相邻的free block合并。
优点:执行速度快
缺点:容易造成thrashing(一个free space被反复的splitting和coalescing) - deferred coalescing。
滞后的合并,有多种选择。比如在某次allocation fail时,触发中断把整个heap中所有的free blocks能合并的全部合并,然后重新尝试一次allocation。
优点:不会引起thrashing
缺点:实现复杂
一般allocator都是采用deferred coalescing
当某次allocation fail时,如果进行了deferred coalescing之后空间还是不够,allocator就会向内核请求扩大heap的空间(调用sbrk()),然后把新空间加入到自己的block list中。
9.8.9 Coalescing with Boundary Tags
回忆我们讨论过的implicit free list结构。
每一个block只知道自己的size $\Leftrightarrow$ 每一个block只知道其下一个block的起始地址,不知道其上一个block的起始地址。
这样我们就可以把该list结构视为链表了。
要将某个block B与其相邻的两个blocks合并,显然将B与其下一个block合并是非常简单的(直接找到其下一个block起始地址,判断其tag是否为free,若是,则B直接将自己的size+下一个block的size即可)。
然而合并B和其上一个block怎么办呢?根据链表的特性,难道我们每次都要遍历嘛?
神人们又想出一个方法,在block的结构尾部加上一个footer,它是header的复制。
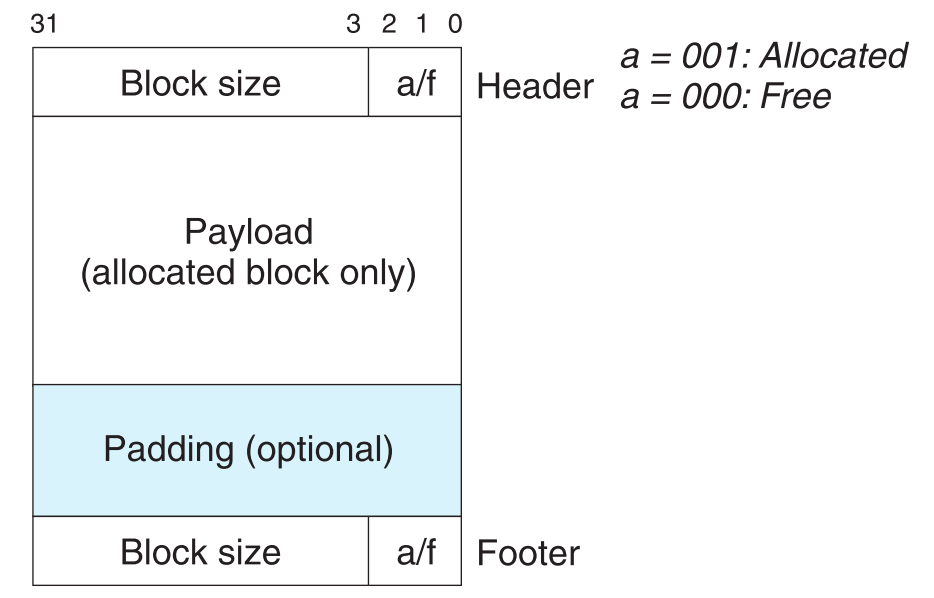
这样B就可以直接通过自己的首地址减去 4 bytes定位到它上一个block的footer。
这样一来,coalescing这个动作就完全变成常数级的了。
看起来很美好,但实际上block的结构一定要精打细算。比如有些应用程序会大量的申请释放小块的内存,在这种情况下footer多出的这一个字的空间就是一笔非常大的开销了。
不过我们发现只有当一个block是free状态时,才需要footer。因此我们可以在每一个block中用一个bit(free/allocated校验)来表示它的上一个block是否为free,这样一来所有allocated blocks都不需要footer字段了。当一个block是free状态时,照常按header和footer的结构来存储;而当这个block被allocate时,就可以直接当footer字段不存在,直接拿来存payload,然后把它下一个block中的校验bit设置为allocate状态即可。
用于校验的bit被称为boundary tags。
加上了footer后, 整个heap就从原来的单链表变成双链表了。
payload:有效载荷,实际数据量
9.8.10 Explicit Free Lists
事实上程序本身并不关注free blocks,那是allocator的事,因此我们可以把所有的free blocks全给单拎出来组成一个list,并将它以某种数据结构表示,比如双链表:
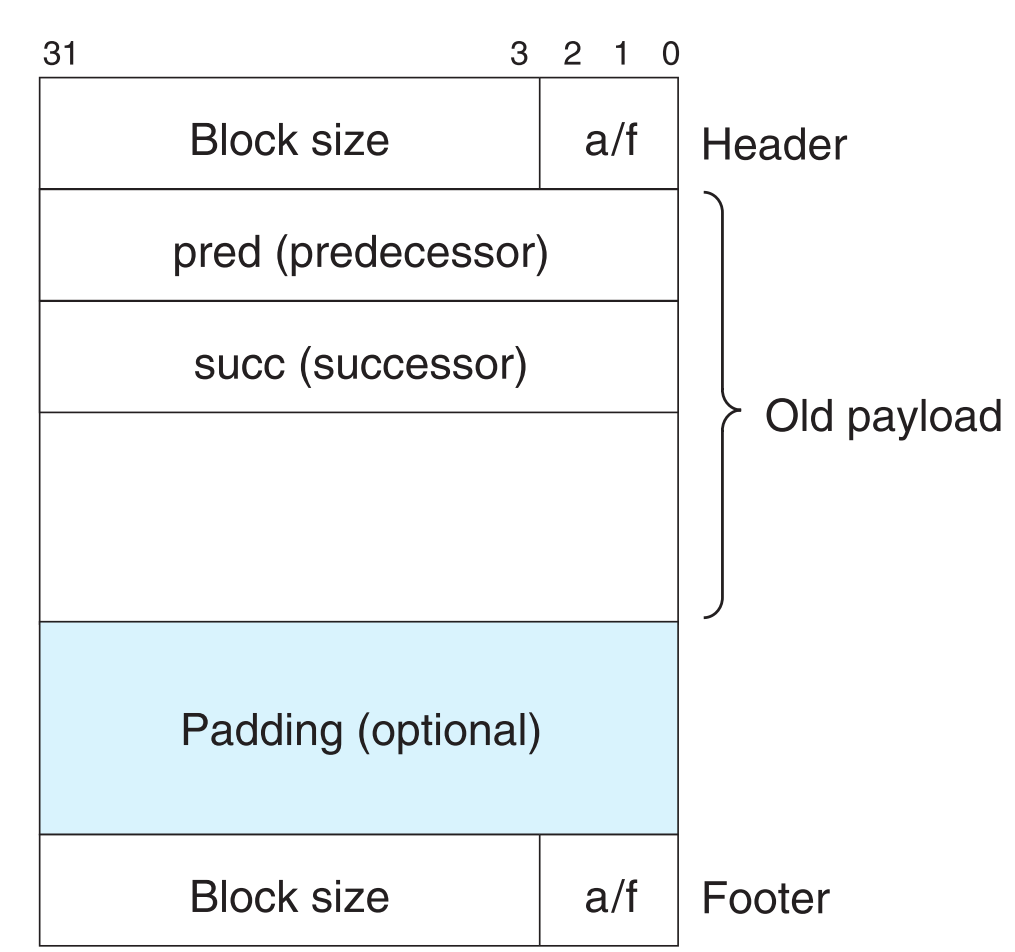
维护free list有两种方法:
- last-in first-out (LIFO)
整个list就像栈一样pop/push新的free block。 - address order
将所有的free blocks按照地址从大到小的顺序拜访。
这种结构的缺点也很明显,所有free block必须能够放下所有的维护信息,因此block的最小size变大。
9.8.11 Segregated Free Lists
为了降低allocation的时间,segregated free list诞生了,它的作用是维护多个free lists,每一个list中维护size相近的free blocks。这样free lists就被称为size classes。allocator需要维护的是所有的free lists,把它们按照size从小到大放置,申请内存时直接定位到某个size class中寻找合适的free block,如果该class中没有合适的,就跑到下一个class中寻找。
segregated free list有很多种,它们的区别就在于如何定义size class。下面我们介绍一种基本的实现:
Simple Segregated Storage
这种基本的lists结构中任意size class中所有的blocks大小都是相等的(而非大小相近),因为它会把一个size class中所有的blocks的size都变成最大的那个block的size(比如list{16,3,4,51,8}会把所有值都变为51)。
因为每次都会直接定位到与申请的内存大小相符的size class,并最终在里面选择一个大小相符的block,因此根本不需要使用split技术了
执行allocation时,只需要找到对应size class,如果该class不空,就直接选择第一个block作为allocate的对象,并把它从free list中删除;如果该class为空,则allocator会发起中断后直接向操作系统申请额外的空间(通常是此次申请内存大小的倍数),然后把这个额外的空间分为几个与此次申请内存大小相等的blocks,把这些blocks连起来组成一个新的free list,然后重新执行一遍allocation。
执行free时,只需要找到对应的size class,然后把此次free掉的block放在该class的最前面即可。
这样一来,allocation和free都是常数级的操作了;而且这种结构中已经不存在splitting和coalescing的概念(仅simple版无),且size class直接就表示了它其中所有blocks的大小,因此每个block的header和footer都可以不要了,这样每个block用于存储信息的开销更小了;又因为allocate和free操作都只对list的第一个元素进行操作,因此不需要使用双链表浪费空间了,单链表完全可以胜任,现在block中唯一需要留下的信息属性就是其后继指针。
该结构的缺点就是非常容易产生internal fragmentation。
9.9 Garbage Collection
garbage collection(之后简称GC)会自动的扫描heap中的垃圾内存,并free它们。
在GC的眼中,内存是这样的
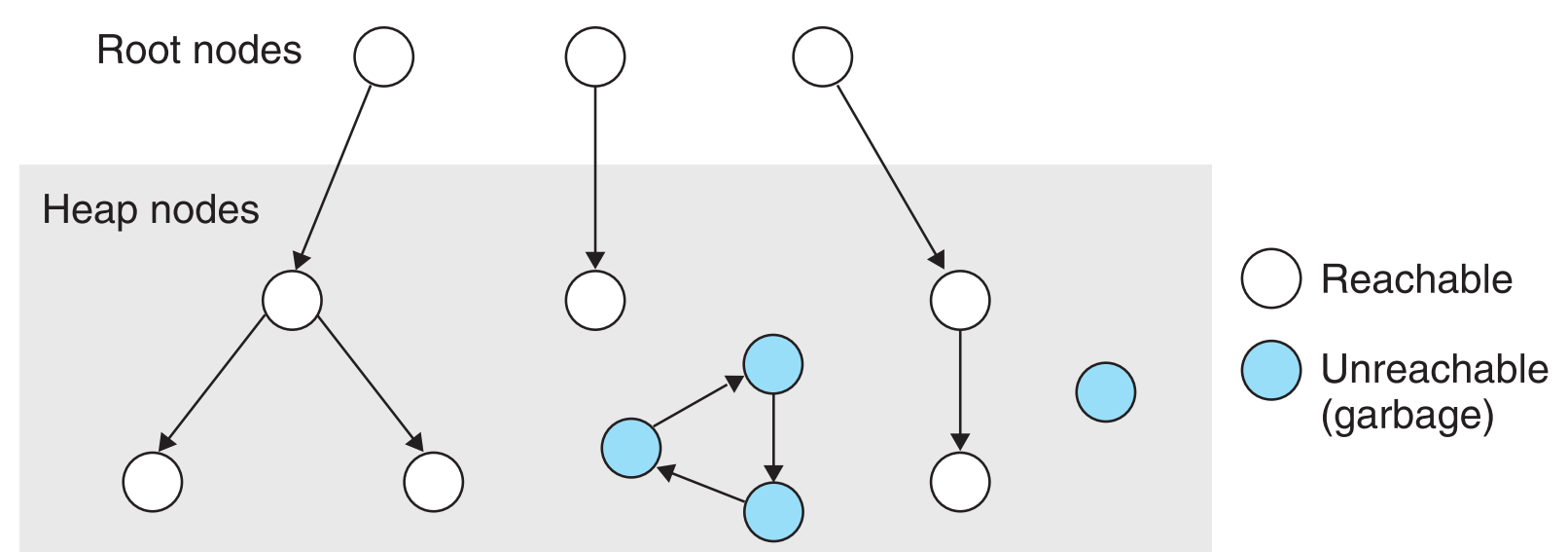
它总是把内存视为有向图,图中的节点被分为root nodes和heap nodes。
- 每一个heap node对应了一个allocated block
- 每一条有向边 a$\Rightarrow$b 表示block a中某个位置存在一个pointer指向block b中的某一个位置
- root node表示heap之外的位置,则root node $\Rightarrow$ heap node代表一个heap之外的pointer指向了heap之内的某个block的任意位置。
root node代表的位置可能是registers,或栈内的变量,或VM中的全局变量
在任何时候,只要某个节点与root是连通的,说明这个节点reachable,它仍在使用中;所有与root不连通的unreachable节点都是垃圾。GC的作用就是周期性的找到这些垃圾节点,把它们free掉。
9.9.1 Mark&Sweep Garbage Collectors
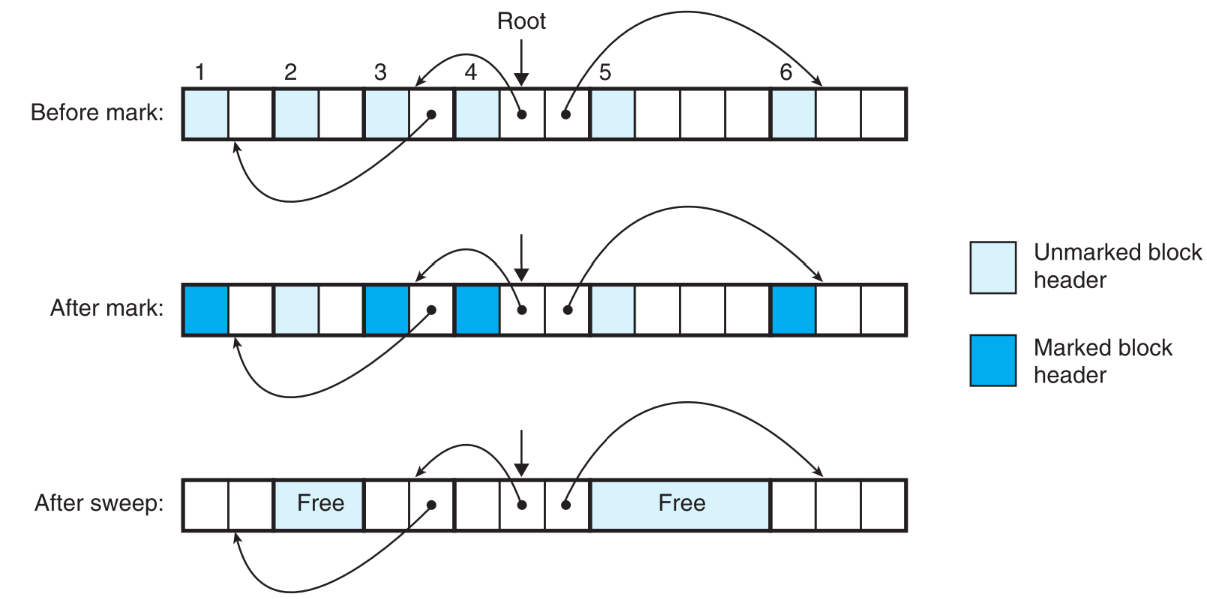
这种GC的执行分为两个阶段。
第一阶段Mark,把所有与root连通的heap nodes标识为Marked nodes。
第二阶段Sweep,free掉所有unmarked heap nodes。
通常用block中header的某个bit来标识其是否被mark
用图来表示这两个阶段的效果(每个小格代表一个字,每个block之间以粗线隔开,箭头表示引用)
9.9.2 Conservative Mark&Sweep for C Programs
为C设计的collector必须为conservative collector,它的特点是会遗漏处理一些垃圾内存,为什么会这样设计呢?
因为C不会对指针变量加上任何的标识,这就意味着如果我们定义了某个int变量它的值刚好是一个有效的地址,系统根本无法分辨它到底是值还是指针,因此基于地址搜索的collector同样也无法分辨,它只能把这些模棱两可的地址保留,这样至少不会出错。
9.10 Common Memory-Related Bugs in C Programs
scanf写错
把scanf(“%d”, &val)写成scanf(“%d”,val),程序就直接把val当地址读取了。认为动态申请的内存初始值为0
在大多数情况下,heap中塞满了垃圾数据,用之前一定要手动对它们初始化栈溢出
在栈中开辟空间后,如果往里面塞的数据比空间本身要大,就会发生栈溢出。因此往栈中写入数据时一定要检查其长度。认为指针类型长度总是等于int类型长度
有些机器的指针类型并不是一个字长,为了移植性应该注意这个问题。另外指针类型长度我们在《逆向-C反汇编-指针基础》中已经详细讨论过了。优先级
比如1
2
3
4void sub(int* size)
{
*size--;
}是不对的,要记住“*”的优先级是很低的,注意加括号。应该改为:
1
2
3
4void sub(int* size)
{
(*size)--;
}局部变量不初始化直接使用
1
2
3
4
5int *stackref ()
{
int val;
return &val;
}这样我们直接拿到了该函数局部变量val在栈中的地址,假设为p。然而我们知道栈只是一块临时的区域,是会被多个函数轮流使用的。当stackref函数return后p依然指向刚刚栈中的位置,但这时该位置可能属于另一个函数了,如果现在不小心给p赋了一个值,那就相当于直接改动当前函数栈的数据,程序直接崩溃。
使用已经被free掉的函数指针
养成习惯在free掉函数指针后,将其置为NULL内存泄漏
某函数中动态申请内存后忘记释放。1
2
3
4
5void leak(int n)
{
int *x = (int *)Malloc(n * sizeof(int));
return; /* x is garbage at this point */
}如果这个函数不断的被使用,heap就会被不断的塞满,最终爆掉,需要长时间运行的程序尤其要注意这个问题。