private: Trie* next[26]; bool isEnd; public: /** Initialize your data structure here. */ Trie() { isEnd = false; memset(next, 0, sizeof(next)); } /** Inserts a word into the trie. */ voidinsert(string word){ Trie* node = this; char letter; for(int i = 0; i<word.size();i++) { letter = word[i]; if(node->next[letter-'a']==NULL) { node->next[letter-'a'] = newTrie(); } node = node->next[letter-'a']; } node->isEnd = true; } /** Returns if the word is in the trie. */ boolsearch(string word){ Trie* node = this; char letter; for(int i = 0;i<word.size();i++) { letter = word[i]; if(node->next[letter-'a']==NULL) returnfalse; node = node->next[letter-'a']; } if(node->isEnd) returntrue; elsereturnfalse; } /** Returns if there is any word in the trie that starts with the given prefix. */ boolstartsWith(string prefix){ Trie* node = this; char letter; for(int i = 0;i<prefix.size();i++) { letter = prefix[i]; if(node->next[letter-'a']==NULL) returnfalse; node = node->next[letter-'a']; } returntrue; } };
#include<iostream> usingnamespace std; intconst N = 100010; //字符串最大长度 int trie[N][26]; //用来模拟trie树的数组 int idx; //最近使用过的结点(当前数组下标) int cnt[N]; //如果存在子字符串,它记录了停止位置;若有多个相同字符串,它记录了总数量。
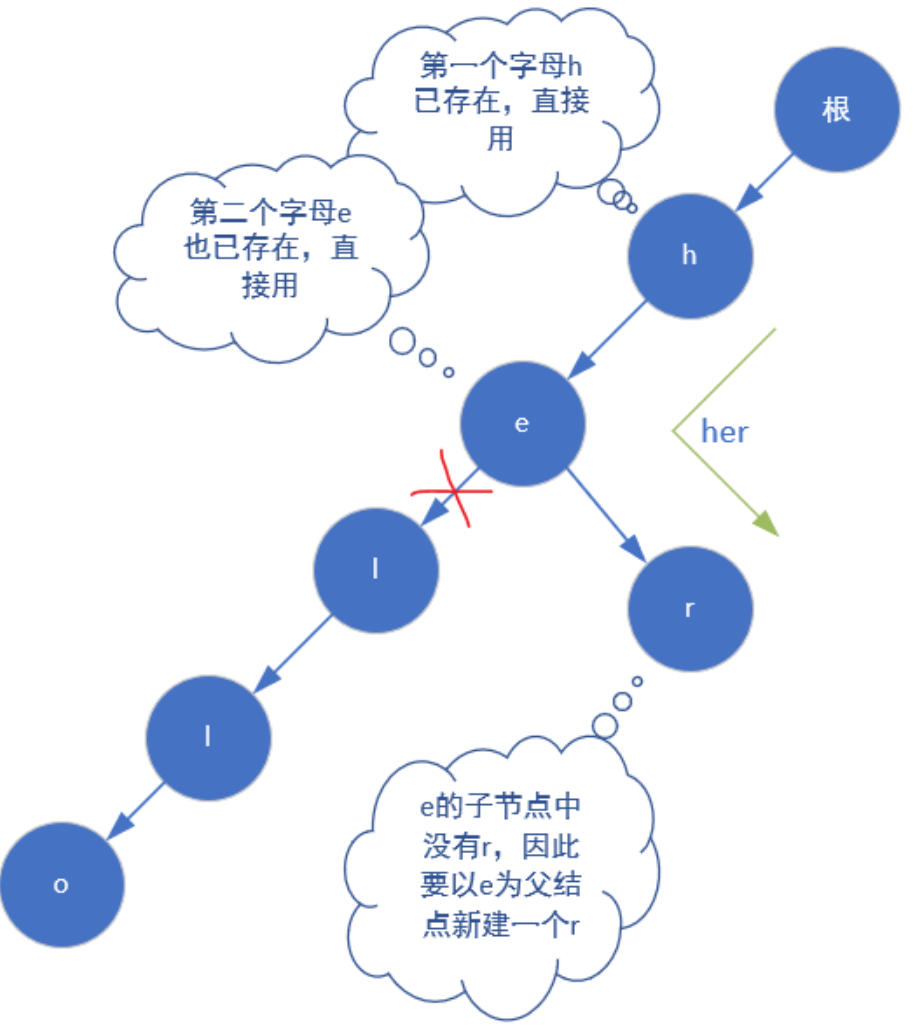
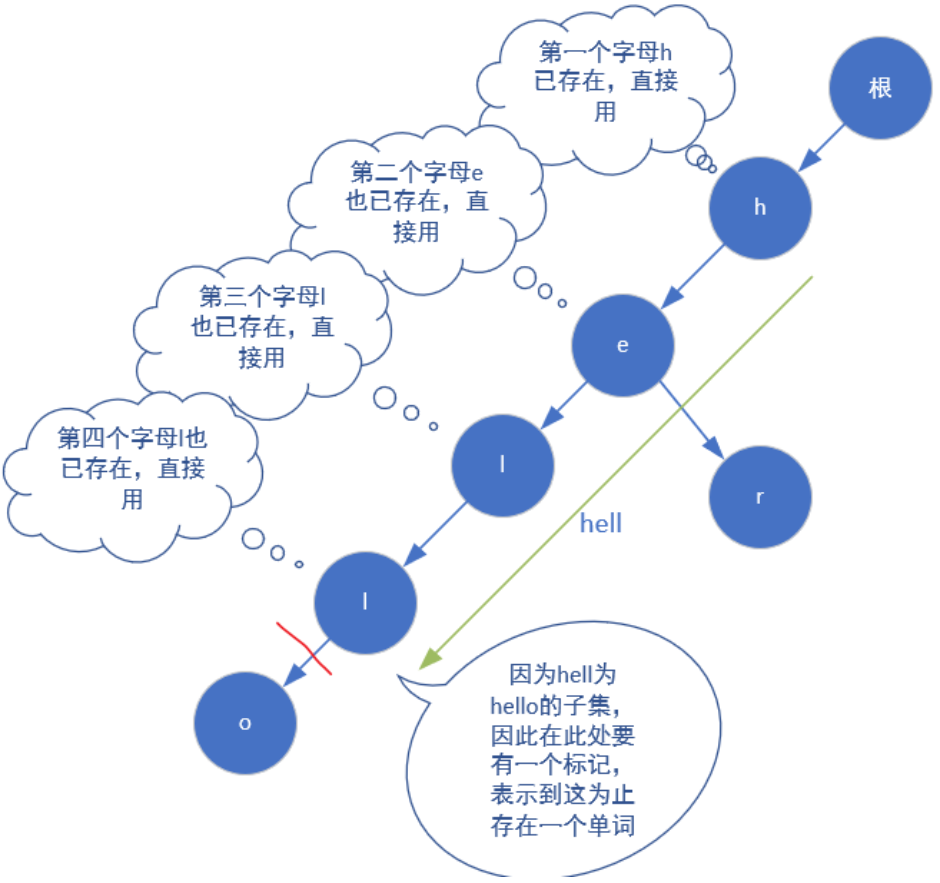
voidinsert(string a) { int p = 0; //操作指针 for(int i = 0;i<a.size();i++) { int u = a[i]-'a'; //将小写字母映射为0~25 if(!trie[p][u]) trie[p][u] = ++idx; //如果当前结点p没有u这个子节点,则创建它(把它放到idx的下一个位置) p = trie[p][u]; //把操作指针移动到p结点的子节点u处 } /*可以看到,上面的p代表了所有结点,而无法反映当前所在树的层数。因此每一步我们能获取的信息 只有:数组中p下标对应的结点的有没有儿子u,而没有用到层数的概念. 比如trie[0][3]=3代表了根节点的值为d(即3+'a')的子节点存储在数组下标为3的位置,之后又有trie[3][2]=4就代表数组下标为3位置的结点(也就是d)的值为c(即2+'a')的子节点,该子结点保存在数组下标4的位置。*/ cnt[p]++; //记录string a的出现次数 }
intquery(string a) { int p = 0; for(int i = 0;i<a.size();i++) { int u = a[i]-'a'; if(!trie[p][u]) return0; //如果某个结点不匹配,就代表string a不在trie树中 p = trie[p][u]; //如果匹配,就把操作指针移动到当前结点的子结点位置,继续比对 } return cnt[p]; //返回string a出现的次数 }
/*自定义Trie树类*/ classTrie{ public: Trie(){ memset(this->next, 0, sizeof(next)); isEnd = false; } voidinsert(string str){ Trie* node = this; int length = str.size(); for(int i = 0;i<length;i++){ if(node->next[str[i]-'a']==NULL) node->next[str[i]-'a'] = newTrie(); node = node->next[str[i]-'a']; } node->isEnd = true; } /* If the prefix of str is recorded in Trie, return it's prefix Else return empty string */ string Prefix(string str){ Trie* node = this; int length = str.size(); string re = ""; for(int i = 0;i<length;i++){ if(node->next[str[i]-'a']==NULL) return""; re += str[i]; //Record the prefix we are finding node = node->next[str[i]-'a']; if(node->isEnd) return re; //If meet a prefix before hit the end of str, we found the prefix of str in Trie. } return""; }
private: Trie* next[27]; bool isEnd; };
classSolution { public: string replaceWords(vector<string>& dictionary, string sentence){ Trie* head = newTrie(); string re = "";
for(int i = 0;i<dictionary.size();i++) head->insert(dictionary[i]); //将所有词根插入Trie树
classWordDictionary { public: /** Initialize your data structure here. */ WordDictionary() { memset(next, 0, sizeof(next)); isEnd = false; } /** Adds a word into the data structure. */ voidaddWord(string word){ WordDictionary* node = this; int length = word.size(); for(int i = 0;i<length;i++){ if(node->next[word[i]-'a']==NULL) node->next[word[i]-'a'] = newWordDictionary(); node = node->next[word[i]-'a']; } node->isEnd = true; } /** Returns if the word is in the data structure. A word could contain the dot character '.' to represent any one letter. */ boolsearch(string word){ returnsearch(word, *this); } boolsearch(string word, WordDictionary& root){ WordDictionary* node = &root; int length = word.size(); for(int i = 0;i<length;i++){ if(word[i]=='.'){ //如果当前字符为'.' for(int j = 0;j<26;j++){ //遍历所有26个字母,尝试匹配到Trie树的下一层 if(node->next[j]){ if(search(word.substr(i+1), *node->next[j])) returntrue; } } returnfalse; //如果说遍历了所有26个字母都无法匹配到Trie树的下一层,说明匹配失败 } if(node->next[word[i]-'a']==NULL) returnfalse; node = node->next[word[i]-'a']; } return node->isEnd; }
private: WordDictionary* next[26]; bool isEnd; };
/** * Your WordDictionary object will be instantiated and called as such: * WordDictionary* obj = new WordDictionary(); * obj->addWord(word); * bool param_2 = obj->search(word); */
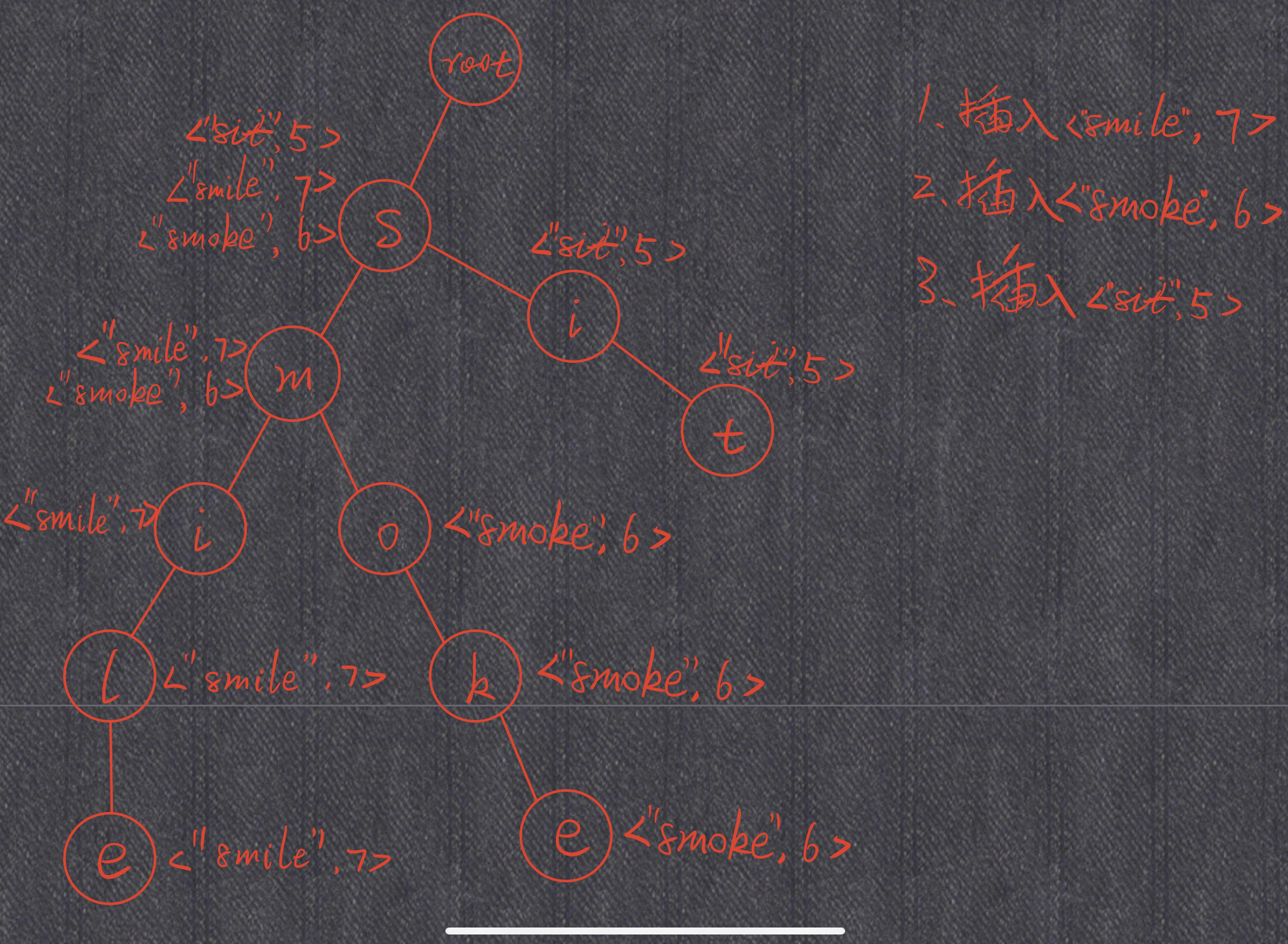
/** Initialize your data structure here. */ MapSum() { for(int i = 0;i<26;i++) next[i] = NULL; isEnd = false; } voidinsert(string key, int val){ MapSum* node = this; int length = key.size(); for(int i = 0;i<length;i++){ int x = key[i]-'a'; if(node->next[x]==NULL) node->next[x] = newMapSum(); //每走到一个节点,都往该节点的哈希表中写入当前请求insert的【string、value】对(如果该键值对已存在,则更新它;不存在,则创建) node->next[x]->count[key] = val; node = node->next[x]; } node->isEnd = true; } intsum(string prefix){ int length = prefix.size(); MapSum* node = this; for(int i = 0;i<length;i++){ //指针在前缀树中走到prefix末尾 int x = prefix[i]-'a'; if(node->next[x]==NULL) return0; node = node->next[x]; } /*计算当前节点的哈希表中所有键值对的值的总和*/ int re = 0; for(auto i = node->count.begin(); i!=node->count.end(); i++){ re += i->second; } return re; } };
/** * Your MapSum object will be instantiated and called as such: * MapSum* obj = new MapSum(); * obj->insert(key,val); * int param_2 = obj->sum(prefix); */