1. 插入排序 1.1 直接插入排序 适用于数据基本有序且数据量不大的数组。
思想 :假定前i个元素有序,每次排序将第i+1个元素插入到有序部分中(采用比较和交换位置的方法),使得前i+1个元素有序
代码 :
1 2 3 4 5 6 7 8 9 10 void InsertSort (int * a, int length) for (int i = 1 ;i<length;i++) { for (int j = i;j>0 ;j--) { if (a[j]<a[j-1 ]) swap (a[j], a[j-1 ]); } } }
分析
1.2 折半插入排序 基于直接插入排序,既然每次都假定前i个元素有序,那么查找第i+1个元素插入到这个有序数组中适当位置的方法,就可以采用折半查找。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void LogInsertSort (int * a, int length) for (int i = 1 ;i<length;i++) { int temp = a[i]; int l = 0 , r = i; while (l < r) { int mid = (l+r)/2 ; if (a[mid]>temp) r = mid; else l = mid+1 ; } for (int j = i; j>l; j--) a[j] = a[j-1 ]; a[l] = temp; } }
分析
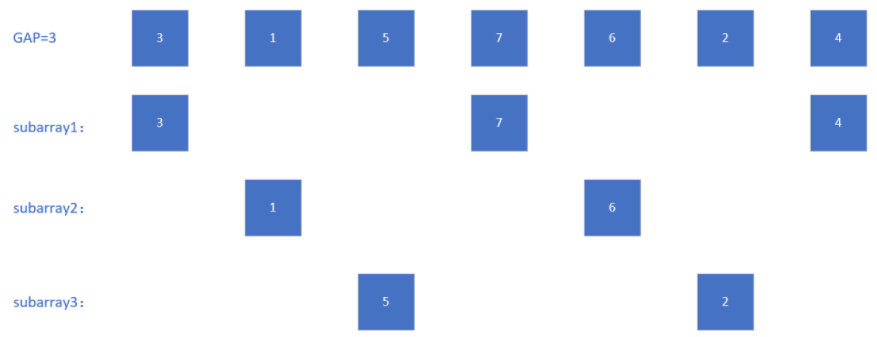
1.3 希尔排序 插入排序当数组规模较小且数组基本有序时速度很快,但数组基本有序的情况很少见。希尔排序的原理就是不断的使数组整体更加有序,最后再通过一次插入排序得以在很快的时间内使得数组完全有序。
实现: 选定一个gap,将数组按间隔gap划分为gap个子数组。
然后对每一个子数组进行插入排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void HellSort (int * a, int length) for (int gap = length/2 ; gap>0 ; gap/=2 ) { for (int i = 0 ; i<=gap; i++) { for (int j = i+gap; j<length; j+=gap) { for (int k = j; k>=i+gap; k-=gap) { if (a[k]<a[k-gap]) swap (a[k], a[k-gap]); } } } } }
分析
希尔排序是第一批突破$O(n^2)$的算法。因为排序算法的根本原理是消除数组中的逆序对,可以看到$O(n^2)$的算法一般每次迭代只能消除一对逆序对,而希尔排序由于跨度大,每次迭代可能消除多对逆序对,这也是它能突破$O(n^2)$的原因。
2. 交换排序 2.1 冒泡排序 从头到尾步进,碰到逆序对就交换位置,这样每一轮遍历都可以确定末尾元素的位置,进行n轮即可。
1 2 3 4 5 6 7 8 9 10 void BubbleSort (int * a, int length) for (int i = 0 ;i<length;i++) { for (int j = 1 ;j<length-i;j++) { if (a[j]<a[j-1 ]) swap (a[j], a[j-1 ]); } } }
时间复杂度:平均$O(n^2)$,最好$O(n)$,最坏$O(n^2)$
2.2 快速排序
确定分界点。在数组中随便取一个值,作为pivot
调整区间。使得pivot左边的值≤pivot,pivot右边的值≥pivot
按照上面两步递归处理左右两端
难点在于第二步,有两种做法:
暴力法(需要额外空间)
双指针(不需要额外空间)
1 2 3 4 5 6 7 8 9 10 11 12 void quick_sort (int q[], int l, int r) if (l >= r) return ; int i = l - 1 , j = r + 1 , pivot = q[l + r >> 1 ]; while (i < j) { do i ++ ; while (q[i] < pivot); do j -- ; while (q[j] > pivot); if (i < j) swap (q[i], q[j]); } quick_sort (q, l, j), quick_sort (q, j + 1 , r); }
时间复杂度:平均$O(nlogn)$,最好$O(n)$,最坏$O(n^2)$
2.2.1 快速选择(快排应用) 它是快速排序的变形,通常用于寻找未排序的数组中第k大的数 。
也就是O(n)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int quick_find (int l, int r, int k, int q[]) if (l == r) return q[l]; int i = l - 1 ; int j = r + 1 ; int pivot = q[i + j >> 1 ]; while (i < j) { do i++; while (q[i] < pivot); do j--; while (q[j] > pivot); if (i < j) swap (q[i], q[j]); } int leftLength = j - l + 1 ; if (leftLength >= k) return quick_find (l, j, k, q); else return quick_find (j + 1 , r, k - leftLength, q); }
3. 选择排序 3.1 简单选择排序 i从头开始,每次在i~length-1中找一个最小元素,与i位置的元素交换位置,i++。即每次可以确定位置i的元素,进行n次即可。
1 2 3 4 5 6 7 8 9 10 11 12 void sort (int q[], int length) for (int i = 0 ;i<length;i++) { int min = i; for (int j = i+1 ;j<length;j++) { if (q[min]>q[j]) min = j; } swap (q[i], q[min]); } }
分析
3.2 堆排序 把原数组初始化为大根堆,然后不断执行取出堆顶元素的操作(交换堆顶堆尾元素,然后整体size–固定堆尾元素,接着把新的结构“堆化”)。当size=0的时候,整个数组就变成升序。(对应的,小根堆可将数组降序排序)
关于堆的内容,参看数据结构部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <iostream> using namespace std;const int N = 100010 ;int q[N]; int n; int length;void down (int q[], int x) int maax = x; if (x*2 <= length&&q[x*2 ]>q[maax]) maax = x*2 ; if (x*2 +1 <= length && q[x*2 +1 ]>q[maax]) maax = x*2 +1 ; if (x!=maax) { swap (q[x],q[maax]); down (q, maax); } } void create (int q[]) for (int i = length/2 ;i>0 ;i--) down (q, i); } void pop (int q[]) swap (q[1 ], q[length]); length--; down (q, 1 ); } void HeapSort (int q[]) create (q); while (length) pop (q); } int main () scanf ("%d" ,&n); length = n; for (int i = 1 ;i<=n;i++) scanf ("%d" , &q[i]); HeapSort (q); for (int i = 1 ;i<=n;i++) printf ("%d " , q[i]); return 0 ; }
分析
4. 归并排序
确定分界点mid=(l-r)/2,把数组分为左右两部分
对左右两部分分别递归
归并(递归触底开始释放时,原数组的每一个元素都被拆分为一个个只有一个元素的数组,因此它们都是有序的,而归并操作又是一个排序的过程,所以每一次进行归并操作的两个数组都是有序的)
关键在于第三步归并,假定待排序数组为arr[ ]。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void merge_sort (int q[], int l, int r) if (l >= r) return ; int mid = l + r >> 1 ; merge_sort (q, l, mid); merge_sort (q, mid + 1 , r); int k = 0 , i = l, j = mid + 1 ; while (i <= mid && j <= r) { if (q[i] < q[j]) tmp[k ++ ] = q[i ++ ]; else tmp[k ++ ] = q[j ++ ]; } while (i <= mid) tmp[k ++ ] = q[i ++ ]; while (j <= r) tmp[k ++ ] = q[j ++ ]; for (i = l, j = 0 ; i <= r; i ++, j ++ ) q[i] = tmp[j]; }
分析
4.1 求逆序对的数量(归并排序应用) 逆序对:数组下标i<j,但value[i]>value[j],则(value[i], value[j])就被称为该数组的一个逆序对。如果a[j]比a[i]小,则它比a[i]到a[mid]所有的元素都小,且比a[l]到a[i-1]的所有元素都大 ,据此我们可以得到a[j]相对于左边数组的逆序对数量:mid-i+1 (即i到mid的长度)。另外归并操作是从两个1-1数组开始的,所以从一开始我们就可以假定函数可以返回对应区间所有元素的逆序对数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <iostream> using namespace std;const int N = 100050 ;typedef long long ll;int q[N];int temp[N];int n;ll merge_find (int l, int r, int q[]) if (l>=r) return 0 ; int mid = l+r>>1 ; ll res = merge_find (l, mid, q) + merge_find (mid+1 , r, q); int k = 0 ; int i = l, j = mid+1 ; while (i<=mid&&j<=r) { if (q[i]<=q[j]) temp[k++] = q[i++]; else { temp[k++] = q[j++]; res += mid-i+1 ; } } while (i<=mid) temp[k++] = q[i++]; while (j<=r) temp[k++] = q[j++]; for (int i = l, j = 0 ; i<=r; i++, j++) q[i] = temp[j]; return res; } int main () scanf ("%d" ,&n); for (int i = 0 ;i<n;i++) scanf ("%d" , &q[i]); ll re = merge_find (0 , n-1 , q); printf ("%lld\n" ,re); return 0 ; }
5. 基数排序 总的来看,原理是(只讨论排正整数)将数组中的数从低位到高位分别排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 void sort (int a[], int length, int digit) queue<int > q[10 ]; for (int i = 1 , count = 0 ;count<digit; i*=10 ,count++) { for (int j = 0 ; j<length;j++) { int value = (a[j]/i)%10 ; q[value].push (a[j]); } int location = 0 ; for (int k = 0 ;k<10 ;k++) { while (!q[k].empty ()) { a[location++] = q[k].front (); q[k].pop (); } } } }
分析
总结 n较小,数据较乱,使用选择排序;若数据基本有序,使用直接插入或者冒泡。