《计网》Introduction
1.1 什么是计算机网络?
1.1.1 概述
- 其实现在看来 computer network 这个名词已经不准确了,我们现在所使用的网络中有成千上万种不同类型的hosts / end systems(比如游戏终端、手机、手表、数字电视等)。
- 所有的hosts通过communication link(数据链路)和packet switches(包交换机)来相互通信。
- 不同的communication link的数据传输速率是不同的,当网络中的一个host想要跟另一个host发送信息时,它会首先把数据分段,并给每一个数据段添加一个header,这样就把一整个数据流变成了一个个离散的packet,放在网络链路上传输,这些packets最终会在接收端被拼装组合成原始的数据,被接收端所识别并处理。
- packet switches用于接收和发送packets,目前有两种主要类型:router和link layer switches,其中链路层交换机通常用于网络的接入层,而路由器通常用于网络的核心层。
- 一个packet从发送端到接收端经过的所有communication link和packet switches形成了一条路径,称为route / path。
- 所有end systems通过ISPs(internet service providers)来接入互联网,ISP有很多种:电信公司、大学ISPs、机场或咖啡店的wifi盒子、蜂窝网络ISPs。不光ISP本身的种类繁多,它提供的网络接入方法也各式各样:本地宽带接入(modem或DSL),高速的局域网接入,移动无线网络接入。网络的主要功能就是把end systems互联起来,那么把end systems接入网络的ISPs之间也必须是互联的,即每一个ISP本身也处于由communication link和packet switches组成的网络之中,特点是ISPs是有等级之分的,同一等级的ISPs之间通过高一级的ISPs互联
- end systems,packet switches和其他网络设备通过protocol来控制信息的发送和接收,比如IP协议定义了router和end systems之间传输的packet的格式。
- protocol就目的就是为了形成一个标准,只有大多数设备都遵守一个标准,复杂的计算机网络才有实现的可能。如今Internet standard是由IETF开发的,这些标准的文件通常被称为RFCs(Requests for Comments);Ethernet和wireless WiFi是由IEEE 802开发的。
1.1.2 互联网提供的服务
我们可以从另一个视角来定义计算机网络:它是为某些应用程序提供服务的基础设施。应用程序比如:多人网游,网络直播、社交媒体等,它们都涉及了多个end systems之间互相交换数据,因此这些类型的应用程序也被称为distributed applications。
我们可以通过IP定位某一个终端,但是我们知道一个终端上是可以同时运行多个进程的,如果要实现distributed application,就必须要在能找到目标终端的同时,找到目标进程。socket interface就是通过制定一系列的规则,让所有遵守某一规则的发送端能够将数据发送到接收端的某一指定进程。
就像邮寄一样,假如Alice(进程A)要给Bob(进程B)写信(发送数据),它只需要遵守邮局的一系列规则:包信封,贴邮票,放入信箱(socket interface),邮局就可以先找到Bob家(IP地址),然后把信交给Bob(目标进程,其他的进程为Bob的家人)。
1.1.3 Protocol是个啥?
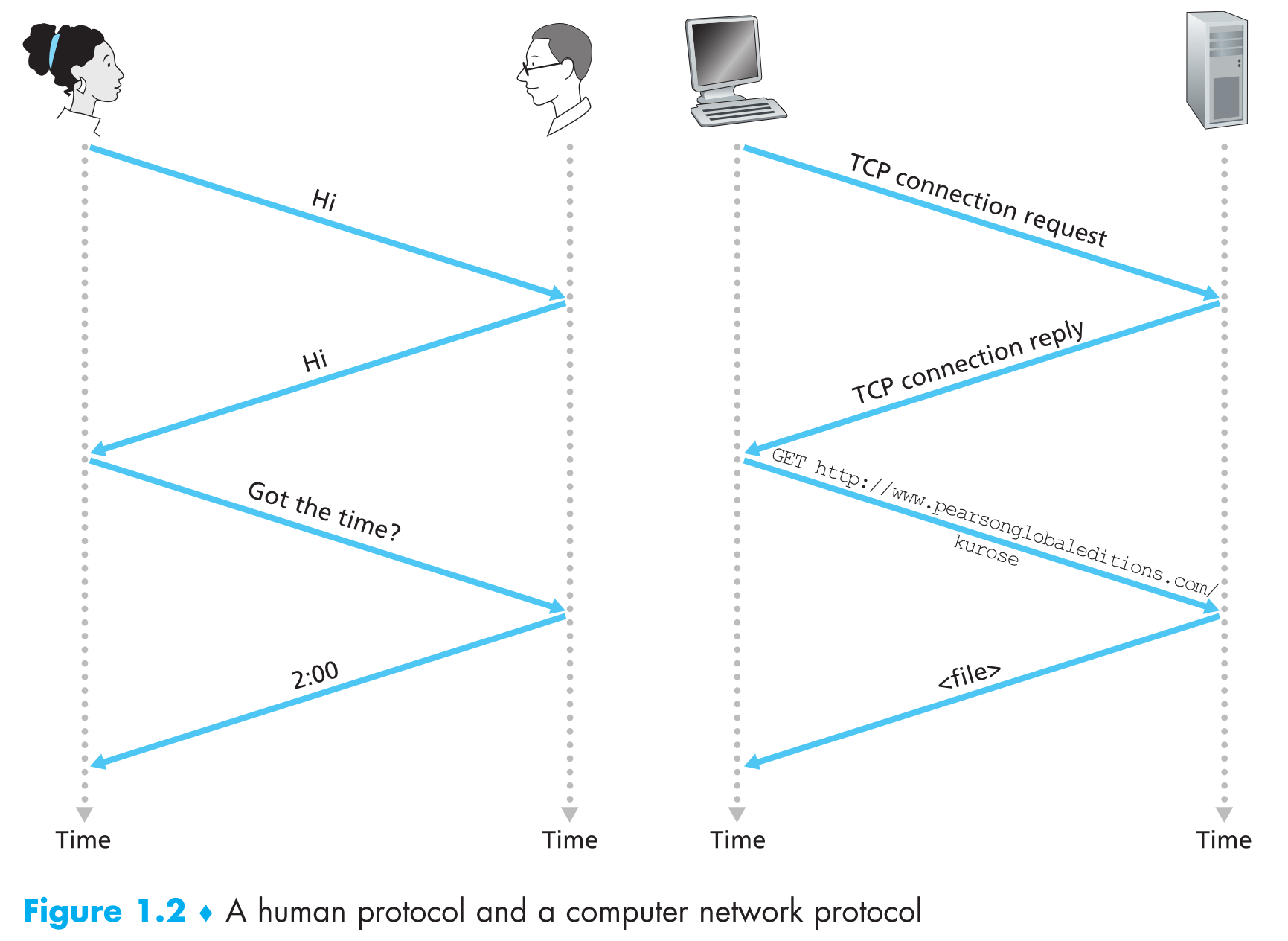
Network Protocols
互联网上所有涉及两个以上终端之间信息交互的动作都要遵守protocol。比如两台物理相连的PC之间有硬件实现的protocol,它控制这两台电脑网卡之间物理链路上的bit flow;end systems之间有软件实现的拥塞控制protocol,它来控制发送端和接收端之间packets传输的速率。
Protocol的定义
A protocol defines the format and the order of messages exchanged between two or more communicating entities, as well as the actions taken on the transmission and/or receipt of a message or other event.
1.2 The Network Edge
所谓网络的边缘,就是终端设备(end systems)所处的位置,它们是网络的主要用户,互联网存在的主要意义就是为了将这些终端设备互联起来,比如PC、server、移动通信设备等都属于终端设备。终端设备通常也被称作hosts。
hosts按功能通常被分为两种:clients和servers,clients通常是个人设备,而servers往往是一个规模较大的data center,为clients提供服务。
1.2.1 Access Networks
从物理上将边缘设备(end systems)与第一个路由器(边缘路由器)相连的网络,叫做access networks,它们是边缘设备进入互联网的第一道门。
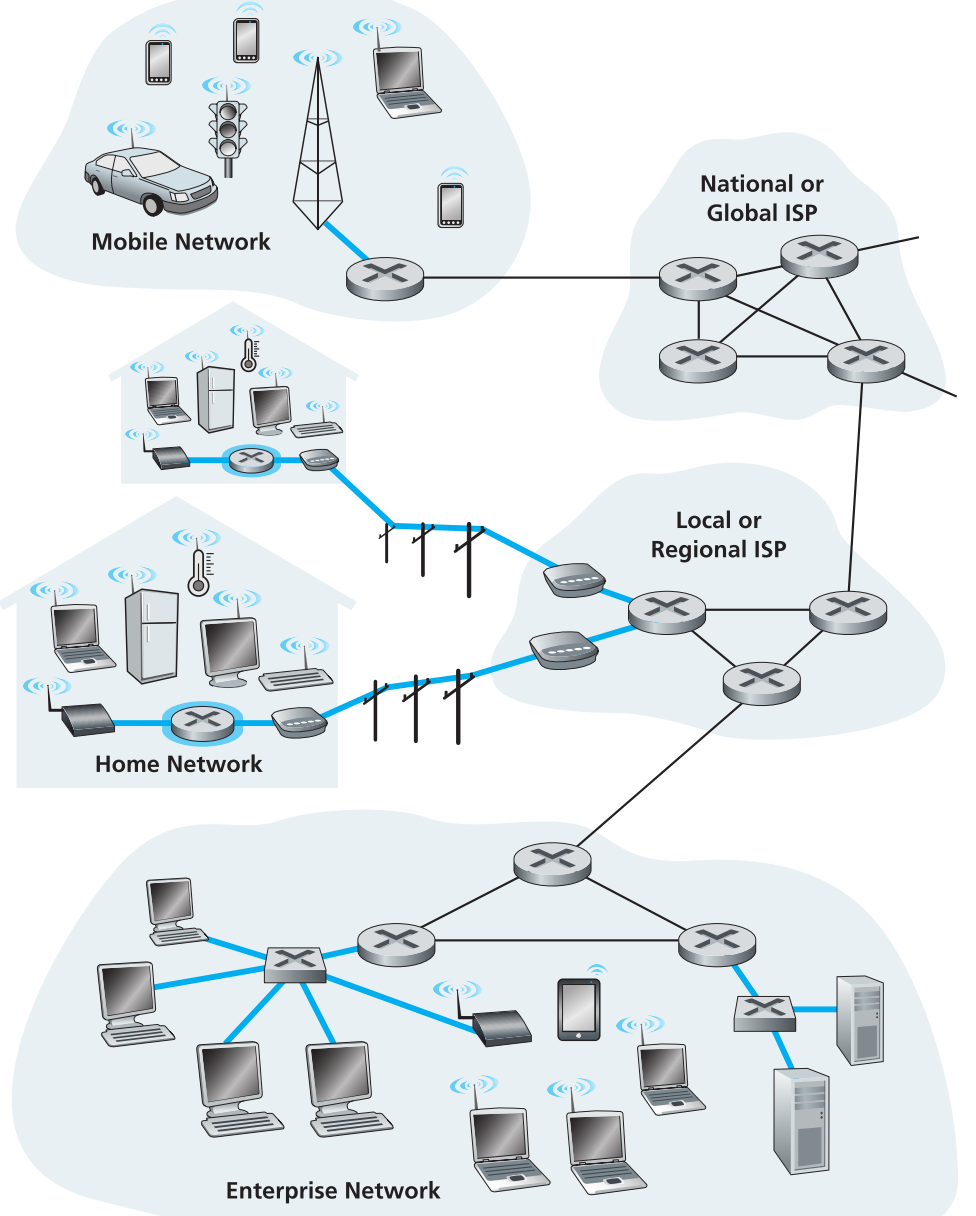
粗线所示部分就是互联网的接入层。
1.2.1.1 家庭接入互联网
目前最流行的本地接入宽带方案是:digital subscriber line(DSL)和cable。
1.2.1.1.1 DSL
普通家庭一般通过本地电话公司提供的local wired phone access来接入DSL,这种情况下,本地的电话公司就是ISP。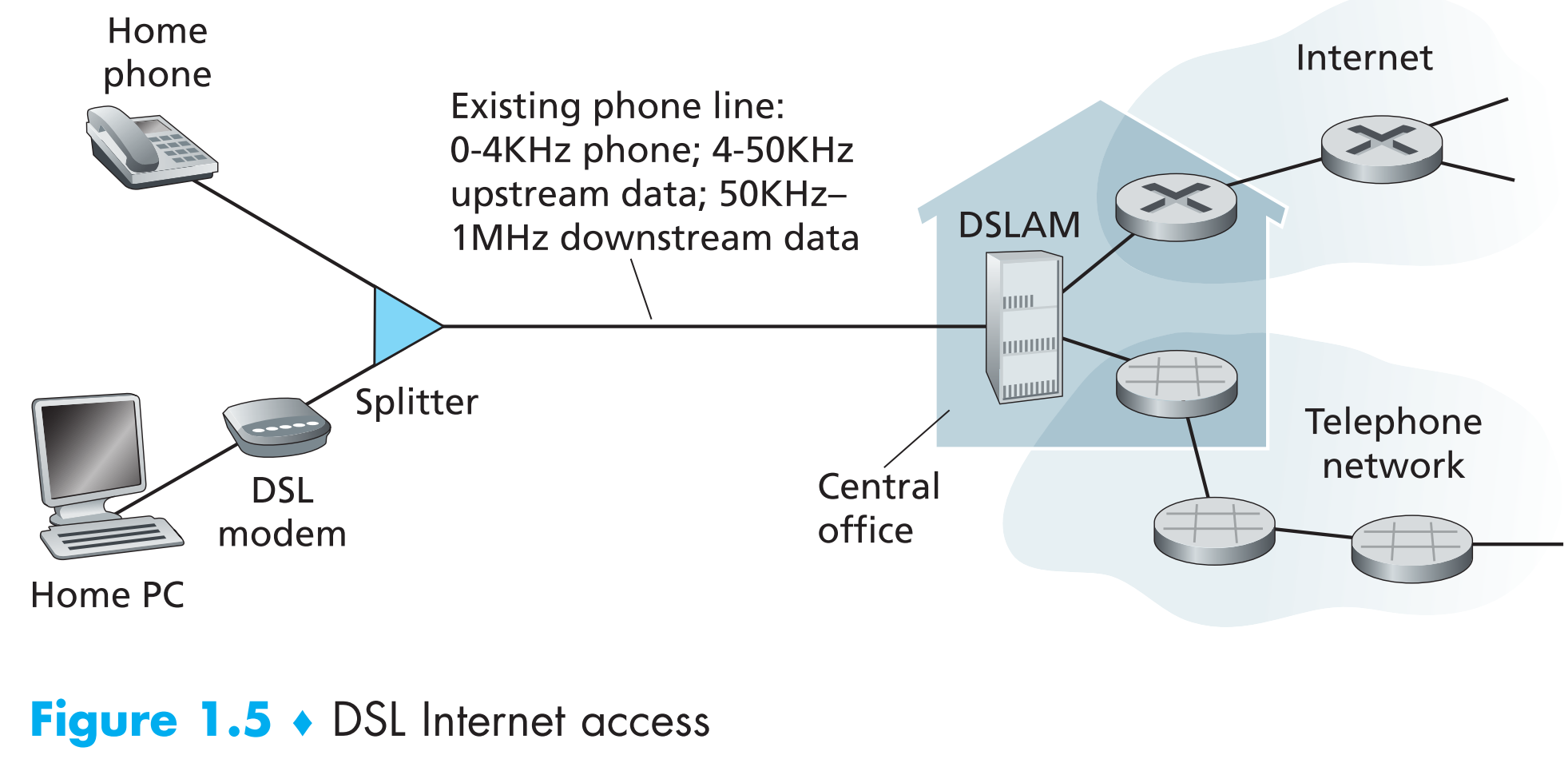
每一个用户的DSL modem占用一条电话线(双绞铜线),以此来与DSLAM(digital subscriber line access multiplexer)交换数据。用户的DSL modem将数字信号转换为高频的模拟信号来放在电话线上传输,模拟信号到达DSLAM后又会被转换为数字信号来
处理,反之同理。
DSL方案中的电话线通常会同时传输数据信号和传统的电话信号,比如某条电话线会同时有三个信道:上传、下载、传统电话信号,让它们共存的方法是让不同信号处在不同的频率,这样一线三用极大的提高了电话线的利用率。
继续看上图,信号到达用户这边的splitter时,它会把电话信号和数据信号划分开,然后将数据信号发送给DSL modem。在ISP的central office那边,DSLAM将用户发来的电话信号和数据信号分开,然后将数据信号发送至互联网,将电话信号发送至电话网络。
通常一个DSLAM供几千个用户使用。
1.2.1.1.2 cable
DSL利用了电话公司的基础设施,类似的,cable internet access利用了有线电视公司的基础设施。
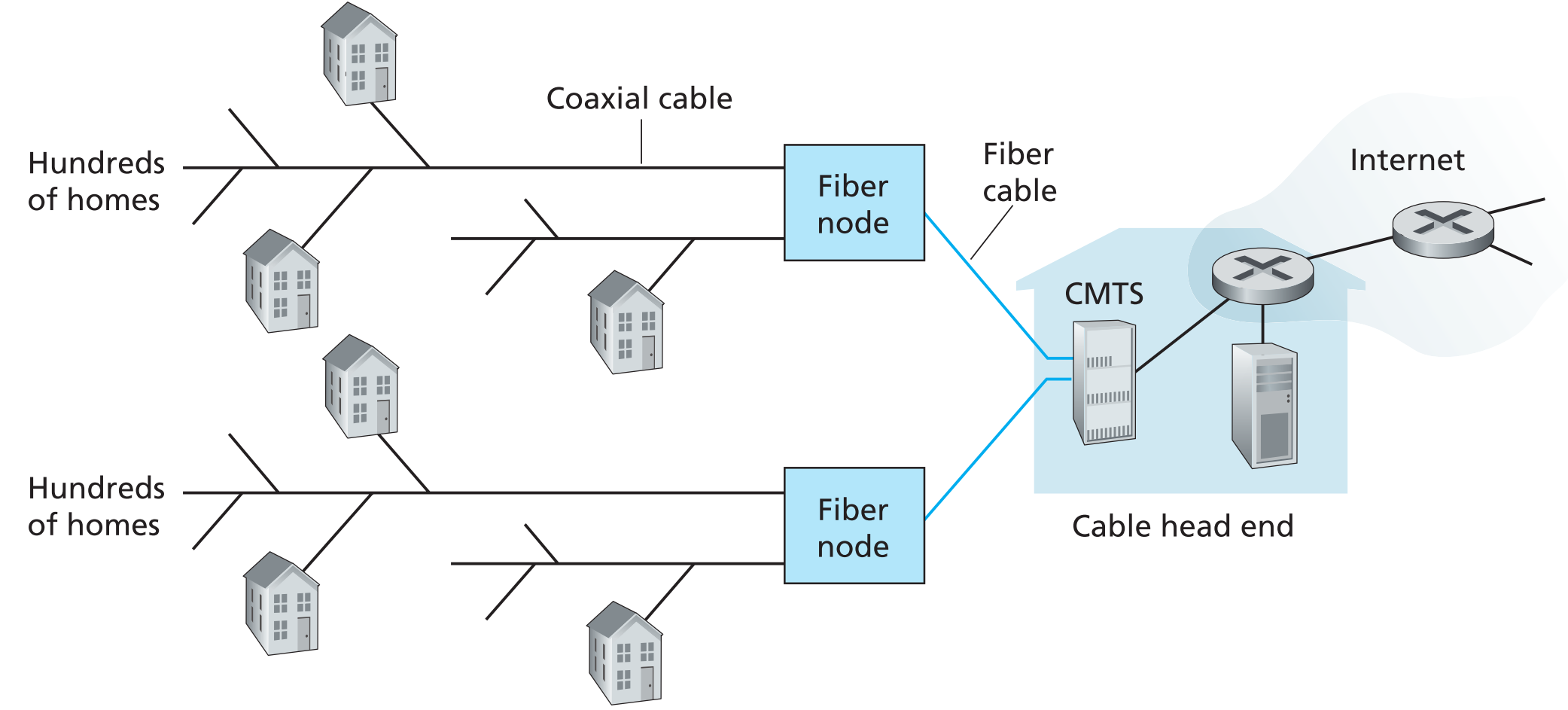
CMTS牵出多根光缆,每一根光缆链接一个fiber node,每一个fiber node与coaxial cables(同轴电缆)相连,用户通过接入coaxial cables来链接互联网。因为这种网络系统同时使用了同轴电缆和光缆,所以也被称为hybrid fiber coax(HFC)。
1.2.1.1.3 光纤到户(FTTH)
它比前两种方案要快得多。正如它的名字fiber to the home,其原理就是用光纤直连用户和central office。
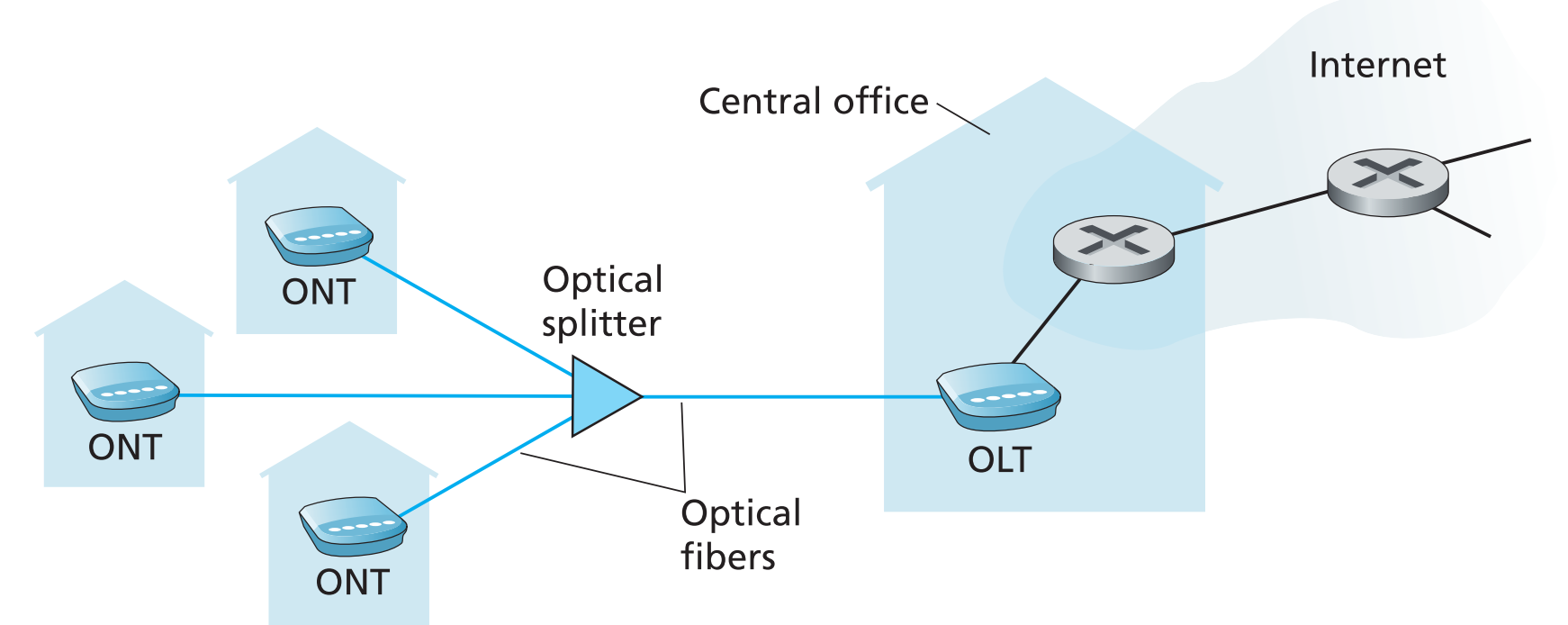
1.2.1.2 公司(以及某些家庭)接入互联网
大学,公司以及某些家庭会使用局域网(LAN)来链接end systems和edge router,使用最广泛的LAN技术是Ethernet(以太网),
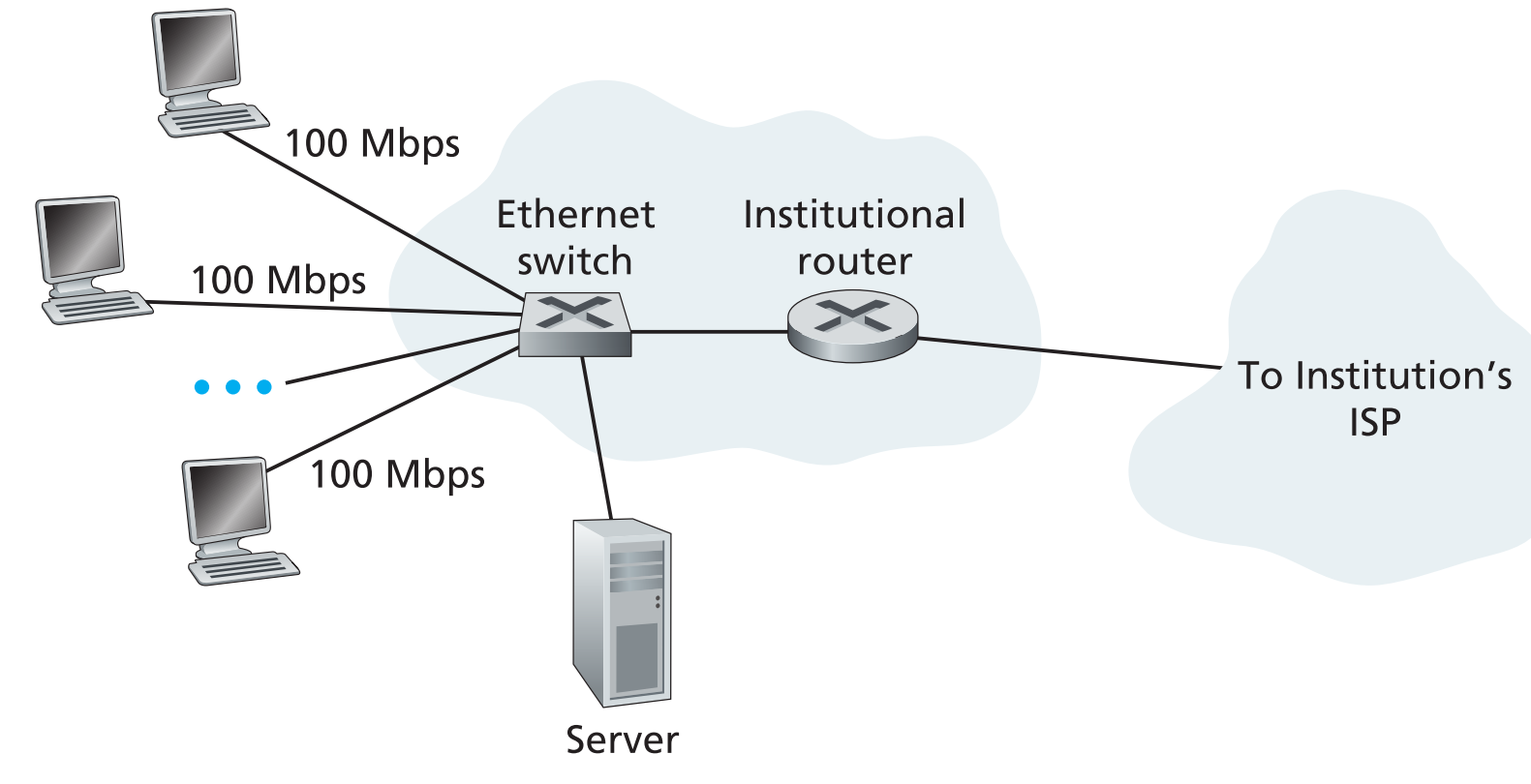
用户可以通过双绞铜线(twisted-pair copper wire)链接到Ethernet switches,由这些Ethernet switches组成的网络再去连接更大的网络。
无线局域网诞生后,越来越多的人选择使用无线网络连接互联网。比如咖啡店中,顾客的无线设备通过连接access point来接入店铺的局域网(无线设备必须在access point附近10m内),店铺的局域网最终与互联网连通。无线局域网基于IEEE 802.11技术,IEEE 802.11技术通常被称为wifi。
1.2.1.3 大范围无线接入:3G和LTE
与使用wifi必须在接入点10m内不同,蜂窝网络(3G/4G等)允许用户在基站10km内连接互联网。
LTE(long-term evolution)是基于3G技术的,但是它的传输速率比3G快得多。
1.2.2 physical media
在网络上传输的每一个bit都是通过电磁波或者光脉冲发送,在physical medium上传输。典型的physical medium包括:双绞铜线,同轴电缆,多模光纤、地面无线电频谱,卫星无线电频谱。
物理媒介主要被分为两类
- guided media(导向型媒介)
电磁波是通过固体媒介传播的,比如光纤,双绞线或者同轴电缆。 - unguided media(非导向型媒介)
电磁波通过空气或者外太空扩散传播,比如无线局域网或者数字卫星信道。
搭建物理链路(双绞线、光纤)的花费通常低于其他网络设备的费用。在物理链路搭建的花销中,人工费用可能比材料费用高出一个数量级。因此现在建筑物完工前一般都会把所有的物理媒介给安装好,来避免后续可能的增加物理媒介的人工费用。
1.2.2.1 双绞铜线(Twisted-Pair Copper Wire)
最常用(99%),价格较低的导向性传输媒介就是双绞铜线,几百年来双绞铜线一直都被用于电话网络。
双绞铜线由两根绝缘的大概1mm粗的铜线缠绕组成,两根线交缠在一起是为了减少附近其他双绞线的电子干扰,通常一个线缆是由一捆双绞线+外层保护皮组成,其中每一根双绞线对应一个传输链路。
局域网中一般使用Unshielded twisted pair(UTP)。
随着光纤的出现,双绞线的市场份额有所降低,但是由于它价格相对便宜,并且速度也不算慢(最高10Gbps),所以在LAN中还是主要使用双绞线。
1.2.2.2 同轴电缆
同轴电缆由两个同心铜导体组成,通常用于有线电视系统(相当于可以当作网线了)。
在有线电视网络中,发送端将数字信号转换成特定频率的模拟信号,这个模拟信号会被多个接收端接收,因此同轴电缆可以被当作导向型的shared medium,也就是说,如果电缆直连到多个end systems,那么每一个end system都会收到其他end systems发送的信息(类似于广播)
1.2.2.3 光纤
光纤很细,易折断。它运输的光脉冲,每一个脉冲代表一个bit,因此它的传输速度非常快(几百G每秒),光纤不受电磁场的干扰,信号衰减的距离也非常远,这些特性使得光纤被大量的用于超远距离导向型数据传输(跨洋网络工程)。只不过光纤的价格非常昂贵。
1.2.2.4 地面无线电信道
地面无线电信道通过电磁波传递信号,不需要物理线缆连接,能穿墙。不过极易受环境因素影响,传输距离也不能太远,因为信号衰减的很快。
1.2.2.5 卫星无线电信道
一个通信卫星连接多个地面基站,卫星接收某一个频段的信号,然后用repeater生成新的信号,将其发送到其他频段。
一般用于通讯的卫星有两种:地球同步卫星,近地轨道卫星。
- 地球同步卫星总是在地球上方的同一位置(通常距离地表36000km,随着地球自转),这样远的距离导致它的信号传输延迟非常高,一般在人迹罕至的地区才会使用地球同步卫星通讯。
- 近地轨道卫星(LEO satellites)比地球同步卫星距离地表更近,且并不总是位于相对地球相同的位置,它们绕着地球旋转,可以彼此通信,也可以和地面基站通信。
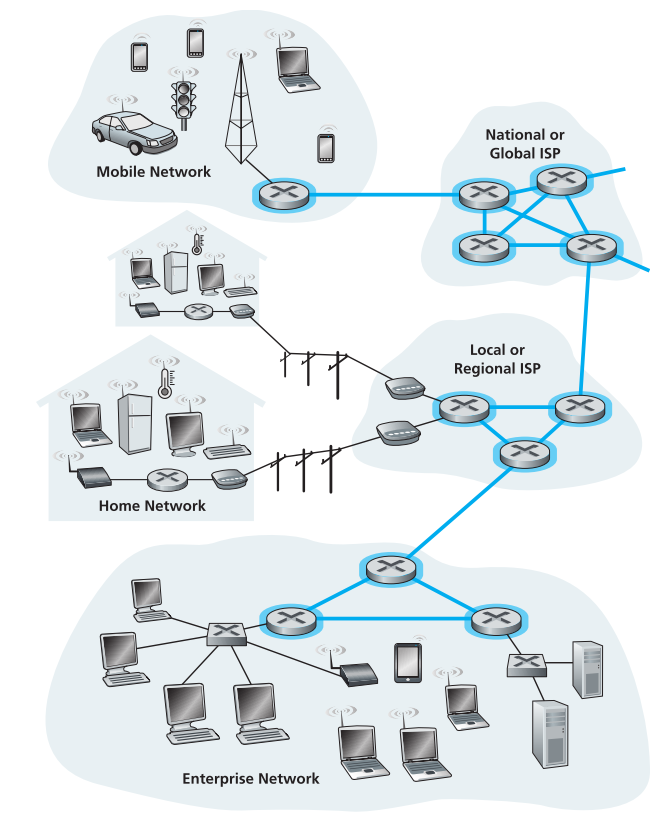
1.3 The Network Core
加粗部分为network core,这一区域的主要作用就是高速地为end systems之间传输信息。
1.3.1 Packet Switching
互联网中,end systems之间互相交换 messages ,message中可以包含任何信息(数据,图片,文本等)。发送端会将message拆分为多个packets后发送,经过 communication links(交换链路) 和 packet switches(包交换机,通常指带router和link-layer switches) 传输,最终发送到接收端。
1.3.1.1 Store-and-Forward Transmission
应用存储转发机制的packet switch每次会等到完整的收到一个packet后才会将其发送(packet在物理链路上是逐bit传输的),即packet switches都会用一个input buffer来缓存还未接收完整的packet数据,直到把完整的packet接收完毕,将packet取出,清空缓存。
1.3.1.2 Queuing Delays and Packet Loss
当一个packet switch收到一个完整的packet后,并不会立即将其发送。
一个packet switch通常连接了多条出链路,它会为每一条链路建立一个output queue。接收到的完整的packets都会先被解析,确定了该发往哪条链路后,将其存储在该链路的output queue中(具体存储在哪条链路的output queue查看该switch上的端口转发表/路由表即可得到),等待被发送。
建立这样的延迟发送机制非常有用,它是解决链路拥挤的关键手段,虽然这种机制带来了queueing delays,但相比链路拥堵,这点代价要小得多。
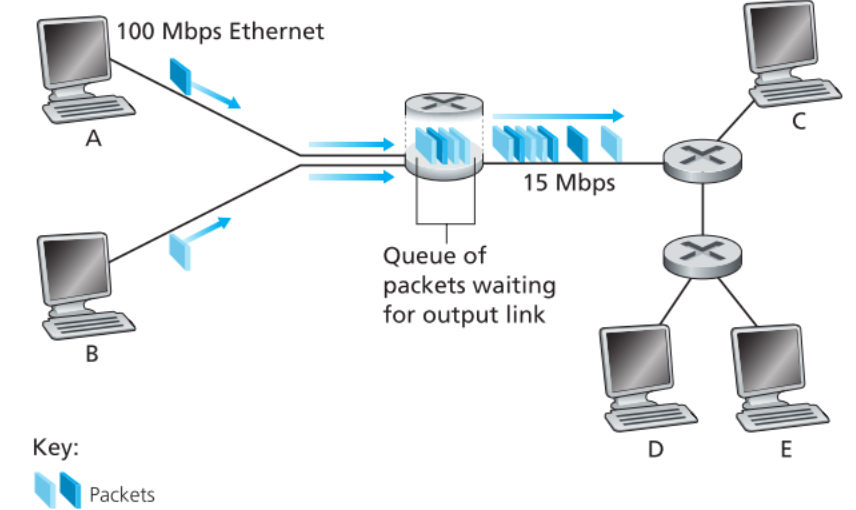
不过由于output queue本质上是一个buffer,它容量有限,当packet switch的某一条链路上的output queue完全被塞满时,后续到达的packets或者output queue中的某一个packet会被直接丢弃,这就是 packet loss (丢包)。
1.3.1.3 Forwarding Tables and Routing Protocols
一个packet switch(以router为例)有多个出口,那么它是如何知道一个packet应该被发往哪一个出口呢?
互联网中的每一个end system都有自己的IP地址,如果终端A想发送信息给终端B,则终端A发送的报文的头部就包含了终端B的IP地址。报文在发送的过程中会经过很多个routers,每一个router都有一张路由表,上面记录了到目标IP应该走哪个出口。router的路由表展现的是它对整个网络拓扑的认知情况(但它的认知不一定正确)。
router收到一个packet后,会检查它头部中包含的目标IP,然后根据路由表,将该packet从相应的出口发出。
路由表是怎么生成的呢?手动还是自动的?后面我们都将学习到。
1.3.2 Circuit Switching
在网络中传输数据的方式除了packet switching(分组交换),还有Circuit Switching(电路交换)。
电路交换时,两个终端的信道始终处于被占用状态,这条信道就专用于他们两个之间通信,其他终端不能占用该信道,即使双方此时没有互相发送数据。
而分组交换则反之,它不会持续占用信道,只在有信息传输时(on demand)短暂的占用信道,因此一条信道可以被任意个终端使用,缺点是当某一对终端短暂占用信道传输数据时,其他终端若此时要使用此信道就必须排队等待前面的终端使用完毕。分组交换不同于其前身报文交换,它传输数据的单位不是一整个报文,而是比报文更小的分组。
有线电话就是电路交换的典型应用,一个终端若想要与另一个终端联系,就必须先在他们之间建立连接,然后他们之间经过的所有的转接点都要持续的维护并保持这个连接的状态,以维持这次通话。电路交换在计算机网络中也类似,两个终端要通信,必须先建立连接,他们之间经过的所有router都要维护这个连接的状态,给这个连接持久性的分配一部分恒定的带宽,因此通过circuit switching交换信息的两个终端之间的信息传输速度的恒定的。
1.3.2.1 电路交换网络中的multiplex
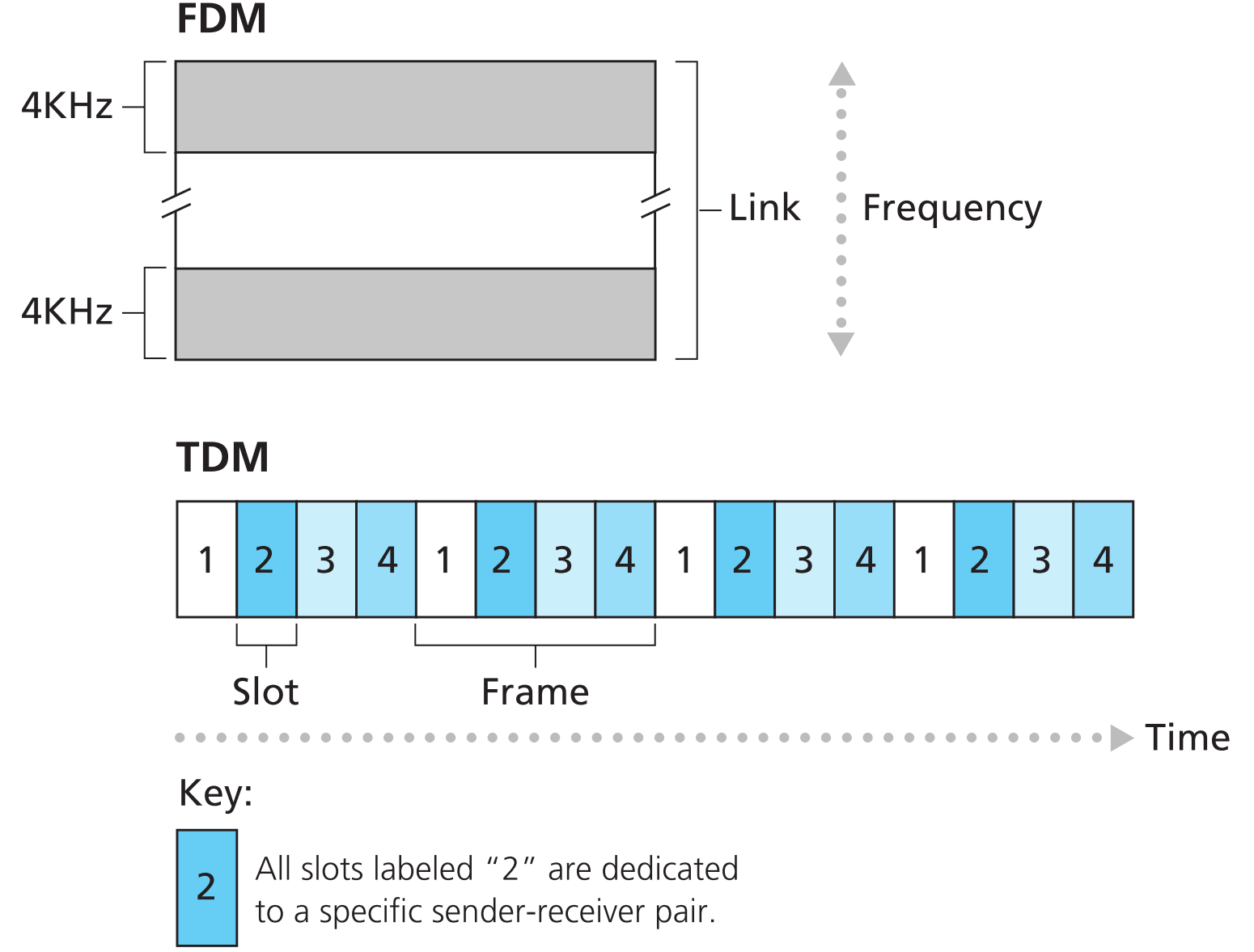
电路交换网络中的链路一般都应用了frequency-division multiplexing (FDM)或time-division multiplexing (TDM)。
所谓FDM,就是将一个固定带宽的链路划分为n个频道,每个频道分得固定的1/n的带宽。
而TDM,则是把一个固定带宽的链路划分为n段时间,每一个用户可在每一个周期的1/n时间内拥有所有带宽。
电路交换网络经常被人诟病的一点,两个建立持久性连接的终端,在他们之间无数据交换时,仍然会占用信道资源,这种时间段被称为silent periods,对网络资源会造成很大的浪费。
1.3.2.2 packet switching vs. circuit switching
packet switching支持者的观点主要为:
- 每个用户分的更大的带宽
- 比电路交换更简单、高效
不过根据packet switching的特性,它不适合被应用在实时性强的通信中(比如电话、视频会议),这种实时通信是circuit switching的长处。
两种数据交换方式各有千秋,但从比例上看,如今主要使用的方式其实是packet switching。其原因在于,互联网的80%用户的80%的联网时间都处于空闲状态,或仅收发极少量的数据,就跟个人PC的CPU有80%以上的时间都处于空闲状态是一个道理。
1.3.3 A Network of Networks
现在我们已经对end systems如何接入网络有一个初步的了解了,所有end systems(个人PC,智能手机,servers)都通过ISP接入互联网,这些ISP不一定是电信部门,它们可能是学校或者商业公司等。
ISP之间当然也要形成一个网络,这样才能够达到让所有end systems互联的效果。最原始的方法就是让每一个ISP与其他所有ISP直连,但在如今的网络规模下,这是不可能实现的。
现实情况下,如今的互联网大概是下面这个样子。
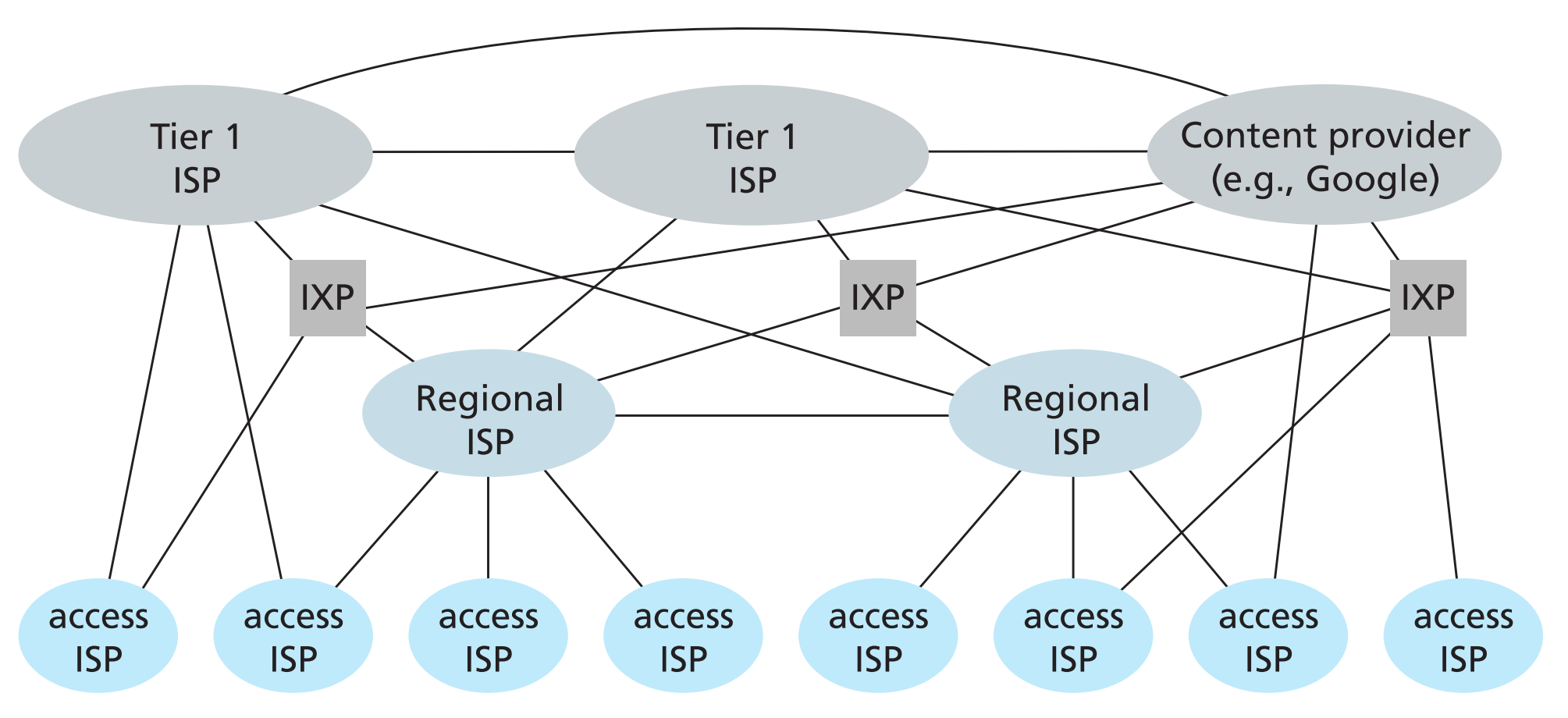
如图所示,ISP的网络是严格分级的,从access ISP到regional ISP到tier 1 ISP,上层对于下层是provider,下层对于上层是customer,customer通过provider转发数据需要缴费(tier 1 ISP当然不用给任何人缴费,因为它是终极provider),处于同一层的ISP之间可以互相peering,谁都不需要给谁缴费即可相互交换数据。
通过建立IXP(internet exchange point)可以使两个不同层的ISP互相peering。
另外还有content provider,比如google,它有自己的私有网络,依靠自己的私有tcp/ip协议,连通自己的所有数据中心,这样它就可以绕过Tier 1 ISP,不需要向它们支付费用,直接给下层ISP转发数据。
不过因为有些数据必须要通过Tier 1 ISP转发,所以google的content provider还是有一部分要链接Tier 1 ISP,并向其支付费用的。
1.4 Delay, Loss, and Throughput in Packet-Switched Networks
网络传输过程中的延迟是无法避免的,比如物理链路本身的信号衰减,网络设计本身的缺陷等,人们只能尽可能的把网络传输损失降低。
1.4.1 Overview of Delay in Packet-Switched Networks
数据在端到端的传输过程中,会经过很多转发节点(交换机、路由器等),每经过一个节点和该节点的一条出边,都会产生nodal delay,nodal delay分为几种类型
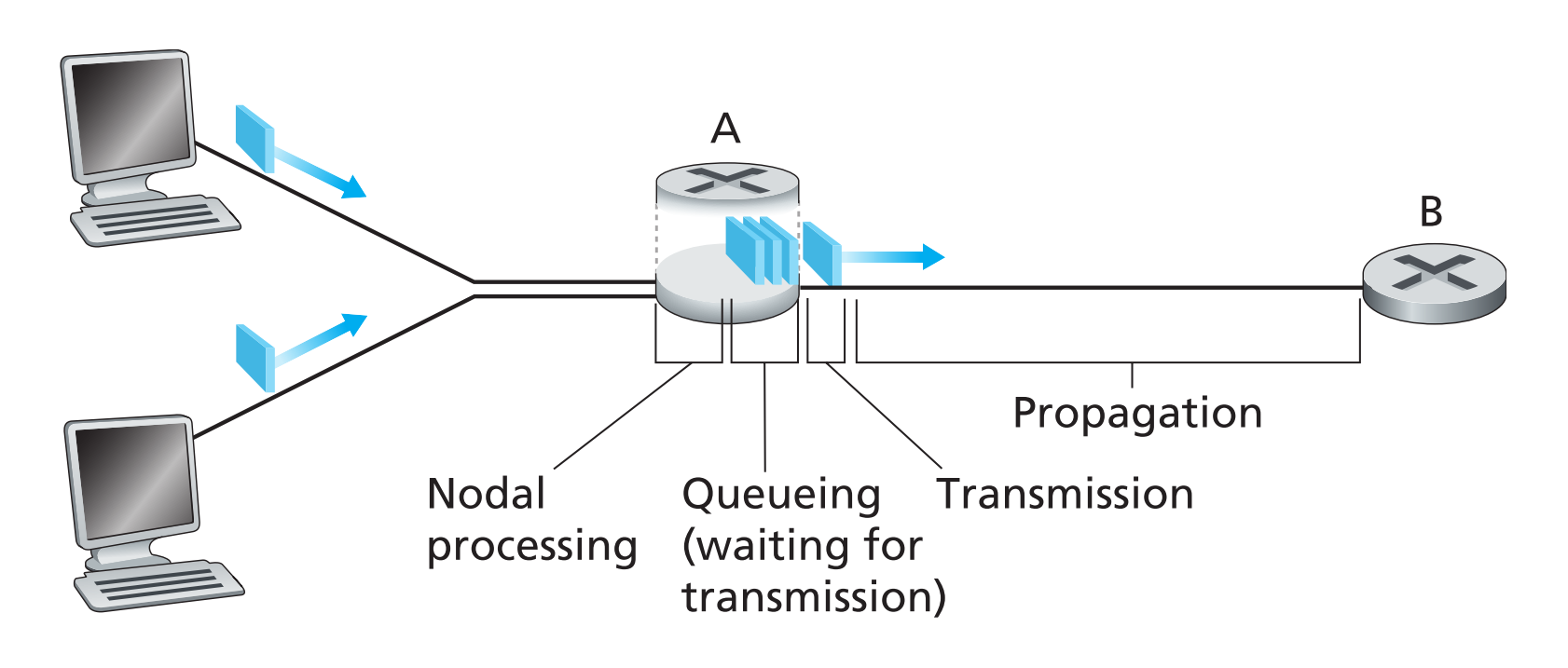
1.4.1.1 nodal processing delay
某一个节点接收到传来的packet时,首先解析这个packet的header并决定要发往哪一条出链路所用的时间就是一部分processing delay,另一部分是检查该packet的bit error所以消耗的时间。
processing结束后,packet就被发到对应链路出口的queue中。
1.4.1.2 queuing delay
packet在对应链路出口的queue中排队等待发送的时间就是queuing delay,如果某个packet前面有很多packets也在排队等待发送,那么queuing delay可能等很久,相反如果队列是空的,那么就没有queuing delay。
1.4.1.3 transition delay
一个packet被完全“放”到链路上,整体开始在链路上传输所需要的时间就是transition delay,比如一个packet长度为L bits,它当前所在节点的发送速率为R bit/s,发送时延就是L/R。
1.4.1.4 propagation delay
一个packet被完全放到链路上发送后,直到它的最后一个bit被下一节点接收完成,这一段时间就是传播时延,【两节点之间的链路长度➗这段链路的传播速率】即可得到。
注意,不要一概而论地认为这四个中的任意一个delay微不足道,是否微不足道要看比例,比如很多人会错误地认为transition delay可以忽略不计,其实如果发送的报文非常大,但是两个节点之间的链路距离非常短,那么transition delay的影响瞬间就大了很多。
1.4.2 Queuing Delay and Packet Loss
1.4.2.1 queuing delay
queuing delay是与具体某一个packet息息相关的,比如同时10个packet同时被塞入队列,那么第一个packet压根就不会有queuing delay,而最后一个packet的queuing delay则非常高,因此通常使用概率与统计的方法来定量分析queuing delay。
queuing delay在什么情况下会对网络传输速度产生较大的影响?
- packet被塞入queue中的速率
- 节点的transmission rate
假定每个packet长度均为L bits,每秒有a个packets被塞到队列中,该节点的发送速率为R bit/s。那么队列的数据接受率就是aL bits/s,再【假设我们的queue无穷大】,则La/R通常用来估算queueing delay的程度,这个比值被称为traffic intensity,当La/R>1时,队列接收数据的速率大于发送速率,那么queue将会被无限扩大,queuing delay也会趋向于无穷大。
因此,路由节点的traffic intensity一定不能大于1.
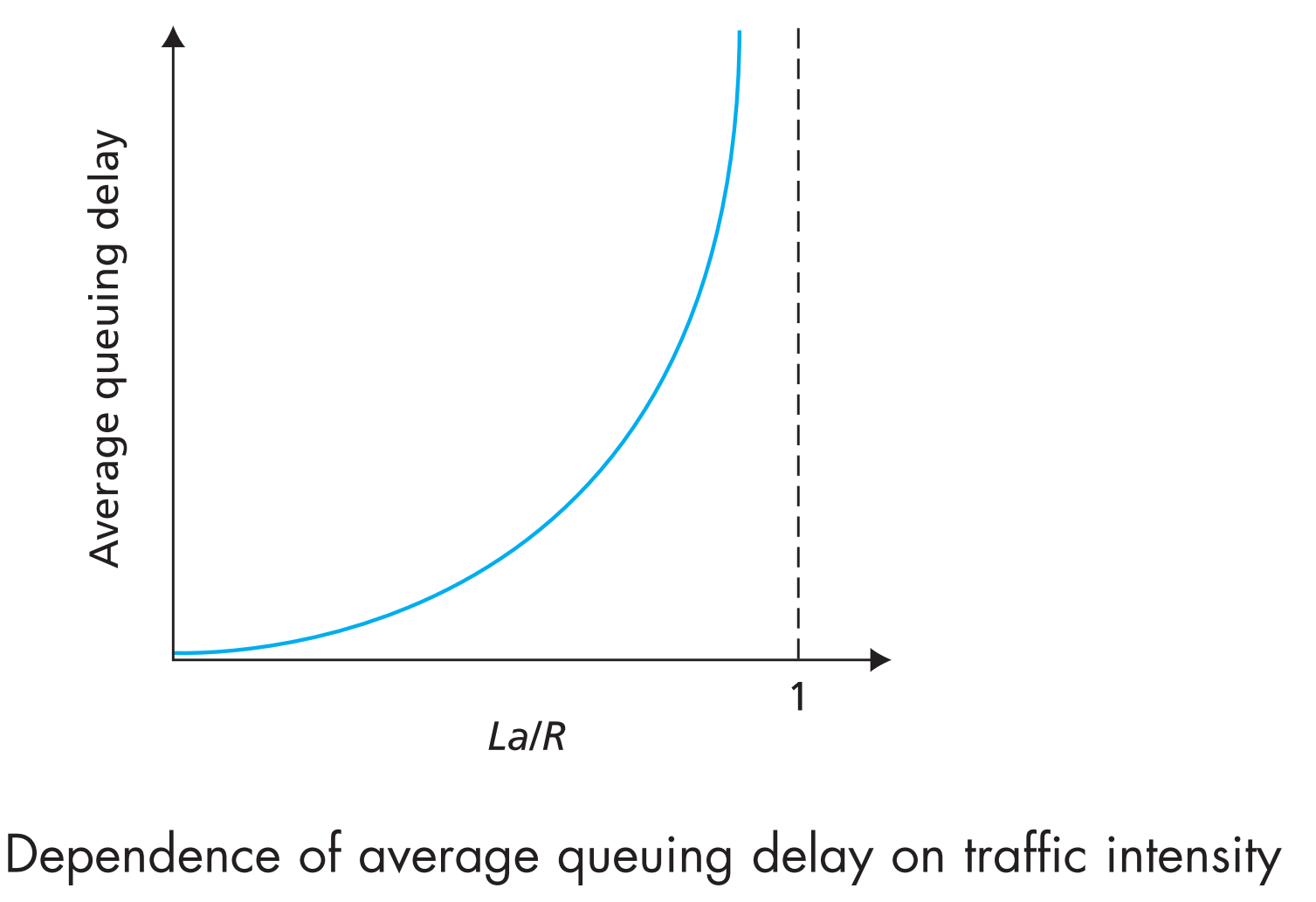
现实情况下,队列的数据接收率是不存在的,所有packet都是随机的被塞入队列中。虽然如此,应用traffic intensity来做一个大概的估计对学习来说已经足够了。
1.4.2.2 Packet Loss
上一小节我们得到了结论:当traffic intensity大于1时,queuing delay会趋向于无穷大。
这并不符合实际情况,一个router再怎么高端,它的queue终究是有限的,当一个packet到达某个router时,如果该router的队列已经被塞满了,那么这个packet就会被drop掉,这就是packet loss(丢包)。
因此,网络性能的好坏不光取决于4种delay,还取决于丢包率,在可靠性需求比较高的环境中,我们不能容忍任何一个包丢失,后面我们将会学习routers如何处理丢包问题。
1.4.3 End-to-End Delay
我们已经讨论一个router以及它的一条出边产生的delay(nodal delay),端到端delay就可以很轻易的求出,假设发送端和接收端之间有N-1个routers,那么end-to-end delay就是: N个nodal delay之和
1.4.3.1 traceroute
使用traceroute命令可以轻松测量端到端延迟,并得到途中经过的所有节点IP。
假如端到端之间有N-1个routers。发送端输入traceroute命令后,就会向接收端发送N个特殊报文,每个报文被标号1~N,对应传输路径上的N个节点。当第i个节点收到第i号报文时,它不会将其转发,而是将自己的信息发回到发送端,同样的,接收端收到第N号报文时,也会将自己的信息发送给发送端。
按照RFC标准,tranceroute会发送3*N个报文,即会对每一个节点的信息进行三次重复测试。
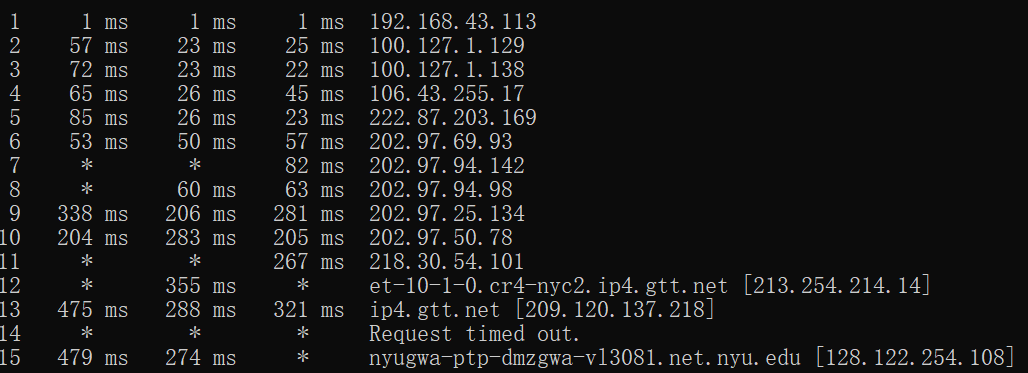
如图,第一列就是报文编号,之后三列是三次测试(从source到当前节点的端到端延迟,即路径上所有节点产生的4种delay之和,*表示测试失败),最后一列是IP地址。
在一个节点的三次测试的delay大多不同,甚至发送端到6号节点的延迟比到2号节点的延迟要低,其原因就是每个packet的queuing delay差距可能非常大。
1.4.3.2 其他延迟
end systems也可以故意地带来延迟,要么是为了遵循某一些protocol,要么是为了满足一些应用程序的需求。
1.4.4 Throughput in Computer Networks
除了delay和packet loss,端到端的吞吐量(throughput)也是影响网络性能的重要因素。
比如A向B发送一个文件, instantaneous throughput 就是B在某一瞬间接收文件的速度(bits/sec),这个我们都有体验,比如用吸血雷下载文件时一般都会展示瞬时吞吐量。假设B接收这个F bits的文件用了T秒,则average throughput就是$F/T;bits/sec$,
可以把link比作水管,数据传输比作流水,不管你外界的水管再大,如果接到你家里的水管很小,那么水流量依然很小,因此端到端的吞吐量往往取决于传输速率最小的那一条链路。
现实中的网络也是如此,如今全世界网速的瓶颈主要在接入层。
1.5 Protocol Layers and Their Service Models
1.5.1 Layered Architecture
所有网络协议(包括实现这些协议用到的软硬件)按照类别被划分为多个layers,下层为上层提供services。比如第n层要实现可靠传输,可能就要使用n-1层的不可靠传输,然后在本层对它加上一些类似超时重传的机制来实现。
应用层和传输层的协议,几乎总是用纯软件的方式来实现的;而物理层和链路层的协议就几乎都是用硬件(网卡)的方式来实现的;网络层通常是软硬件结合的方式。
这种分层的结构的优点在于,它使得每个层次之间相互独立,方便后续的更新。但是缺点也是存在的:1. 高层与低层之间的功能有些重叠;2. 某一层功能的实现依赖于其他层的信息,这样层次之间没有做到完全独立。
总的来说,每一个layer种包含了多个protocols,因此每一个layer也可以被称为一个protocol stack。
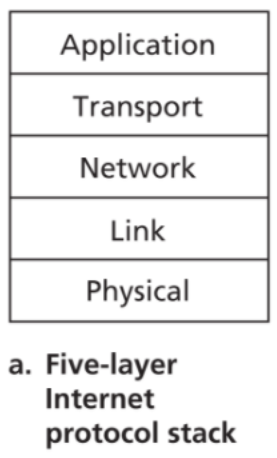
下面来简单的介绍一下网络的五层协议栈。
1.5.1.1 Application Layer
HTTP、SMTP、FTP、DNS这些都是应用层协议。应用层协议分布式地部署在多个end systems上,比如两个终端上的应用程序之间想要通信,就必须同时遵守相应的应用层协议。
在应用层传输的packet又被称为message
1.5.1.2 Transportation Layer
TCP和UDP是传输层的两个协议,它们的功能就是在终端之间运输message。TCP提供可靠传输和拥塞控制,但速度较慢;UDP提供不可靠传输,但速度较块。
在传输层传输的packet又被称为segment
1.5.1.3 Network Layer
网络层的功能是在终端之间运输segment。著名的IP协议定义了datagram的格式,以及end system和routers使用datagram中信息的方法,互联网中所有的网络设备都必须运行IP协议。
不仅如此,网络层还有很多routing protocols,它们定义了路由更新的方式。
在网络层传输的packet又被称为datagrams
1.5.1.4 Link Layer
网络层提供的是端到端的datagrams传输服务,而链路层提供的是两个相邻节点之间的frame(header+datagram)传输服务。
link layer提供的服务类型取决于当前链路采用的链路层协议。比如有些链路层协议提供可靠传输(注意与传输层的可靠传输区别,一个作用于任意两end systems之间,一个作用于两相邻节点之间),有些提供不可靠传输。
典型的链路层协议有以太网、PPP、wifi等。
在链路层传输的packet又被称为frames
1.5.1.5 Physical Layer
链路层的功能是在两个相邻节点之间传输整个frame,为它提供服务的,物理层的作用则是在相邻节点之间逐bit的传输frame。
physical layer中的协议取决于当前链路所使用的媒介类型(双绞线、光纤等),每一种媒介类型都对应了一种物理层的协议。
在物理层传输统统都是bits
1.5.1.6 OSI reference model
以上几个层次属于TCP/IP协议栈。要知道的是,协议栈不止有一个,TCP/IP协议栈其实是由OSI七层参考模型演变过来的。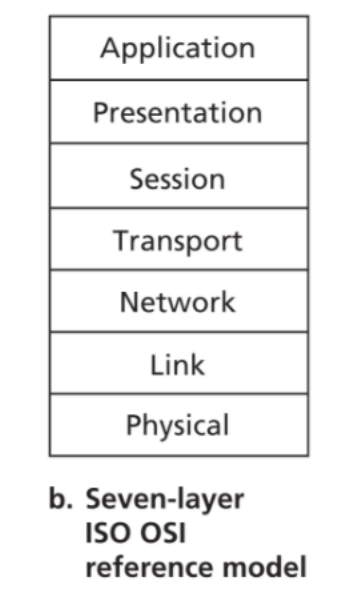
可以看到它比起TCP/IP协议栈多出了两个层:
- Presentation layer。因为不同机器对数据的表示方法是不同的,表示层的作用就是把这些不同形式的数据统一起来,具体的功能包括数据压缩、数据加密以及数据描述。
- Session layer。对交换的数据进行约束以及同步,比如建立一些检查点,当通信故障时可以恢复到最近的检查点。
为什么实际上被广泛使用的TCP/IP协议栈中去掉了这两层?这两层不重要吗?
事实上,这两层是否重要完全取决于开发网络应用的人觉得这两层的功能是否重要,如果觉得重要,就去实现对应的功能,觉得不重要,就不管它。
因此没有必要专门抽象出两层来描述,并不是所有应用都需要使用其中的功能,按需取之,里面全都是可选项。
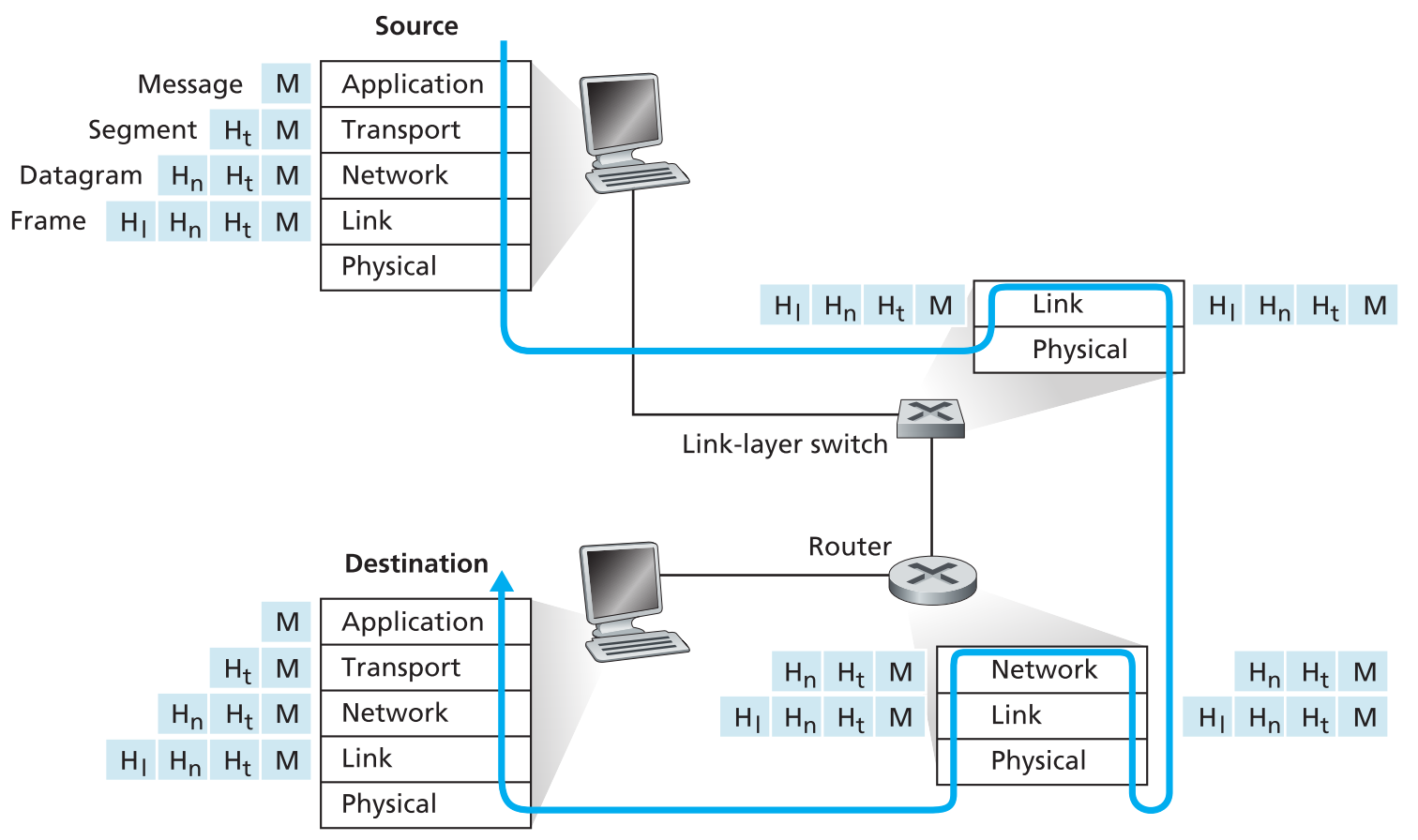
1.5.2 Encapsulation
信息在网络中传输的过程大致如下
可以看到并不是所有的网络设备都需要实现全部的5层协议,链路层交换机只需要实现低两层,而路由器只需要实现低三层,因为对于传输来说,解析到那一层就已经足够了。
这张图中还包含了一个重要的概念:encapsulation。注意看Source部分,一个message从应用层开始往下一直到被发出,每经过一层都要被封装一次,每次封装的过程就是给当前packet加上一个header的过程。
图中Message被发送到传输层,被封装上了一个传输层header,这时massage就被视为一个payload,它和传输层header共同组成了segment;接着这个segment被视为payload,传输到网络层,被加上网络层header后它们共同形成了datagram;再将datagram视为payload,将其传输到链路层,被加上链路层header后它们共同形成了frame,最后frame被发送到物理层,以bit的方式在链路上传输。
当然这只是一种简化的模型,到后面我们将会学习到,一个message可能会被拆分为多个segments发送,每一个segment都有一个header,而接收端还要去重组这些segments。