《CSAPP》Exception Control Flow
8.1 Introduction
在计算机启动时,program counter(简称PC)会不断的读取内存地址中的指令并执行。PC在执行完某条指令后又跳转到另一个地址并执行其中的指令,这个过程叫做处理器的control transfer,一系列这样的过程叫做control flow。
最简单的一种“平滑”的control flow是PC 顺序的读取连续地址中存储的指令并执行 。
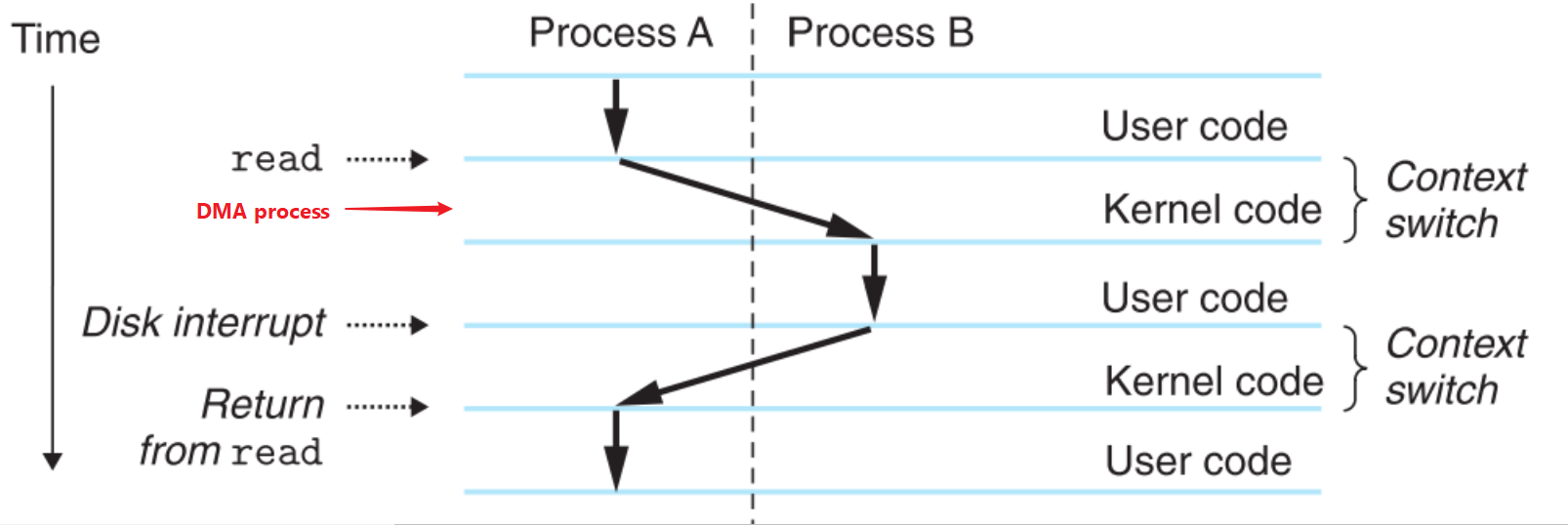
但是因为任何程序几乎一定要用到函数或循环,平滑的control flow只是理想状态,它必然会被程序内部的jump、call或者ret等指令打断,不仅如此,它还会被程序之外的因素打断。比如从disk读取数据,在数据从disk传输到内存的过程中,CPU会利用这段时间去干其他事,等到数据完全读取到内存中后,disk会对CPU发出中断指令告诉它可以去内存中取数据了(参看《memory hierarchy》相关内容),这中间就产生了程序之外因素引起的中断,这种类型的中断(或者说“平滑”的control flow中发生的跳跃变化)被称为exception control flow(ECF)。
计算机系统中的每个层级都可能发生ECF,如硬件层的中断,操作系统层面kernel的context switches,应用层中进程之间的控制转换,程序中使用nonlocal jump直接跳转到别的函数中。
ECF是I/O、进程和虚拟内存等技术的基础,了解它可以帮助我们理解应用程序是如何与操作系统进行交互的。
8.2 Exceptions
Exceptions(异常机制)是由硬件和操作系统共同实现的,因此它在不同的操作系统中的长相虽然不一样,但底层实现的逻辑其实都差不多。
定义:exceptions是控制流为了响应处理器状态的改变(简称事件)而发生的突变。
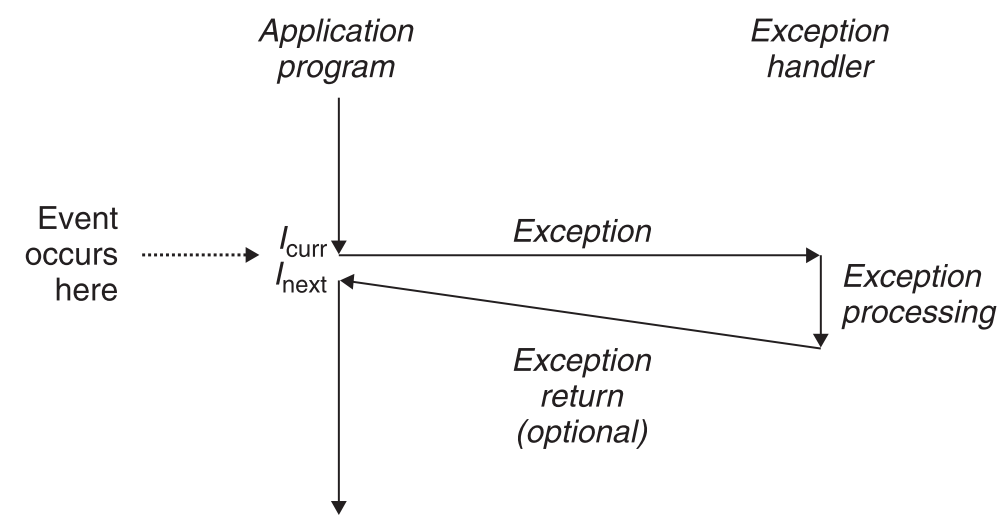
事件可能直接与当前正在执行的指令相关,比如数字运算溢出、除0操作;也可能与当前正在执行的指令无关,比如I/O请求完毕(比如读取disk数据)。
总之,每当处理器捕捉到了一个事件,它就会转而去查询一个跳转表(exception table),在这张表中找到对应的专用于处理这类事件的句柄(exception handler)并调用。
句柄和指针的区别:我们可以随意修改指针指向的内容。而句柄不同,它是和操作系统沟通的指针,不应该被随便修改,所以windows将它命名为handler来与普通指针相区别。
当该句柄执行完毕后,根据事件的类型会发生以下三件事之一:
句柄把控制交还给事件触发时正在执行的指令。
句柄把控制交还给事件触发时正在执行的指令的下一条指令。
句柄直接中止当前程序。
8.2.1 Exception Handling
现在我们来看看硬件和软件之间是如何协作来实现Exception的。
系统中每一个类型的Exception都由一个Exception Number(唯一,非负整数)来标识。其中一部分number是由处理器的设计者指定的,这类Exceptions与程序当前执行的指令相关(除0、违规读写内存、断点、数字运算溢出);另一部分由内核的设计者指定,这类Exceptions与程序当前执行的指令无关(system call、或来自I/0的信号)。
- 开机启动操作系统阶段
操作系统会分配一块空间给exception table,并将其初始化,完成后这张表的第k个条目就是用于处理编号为k的excetpion的句柄地址。
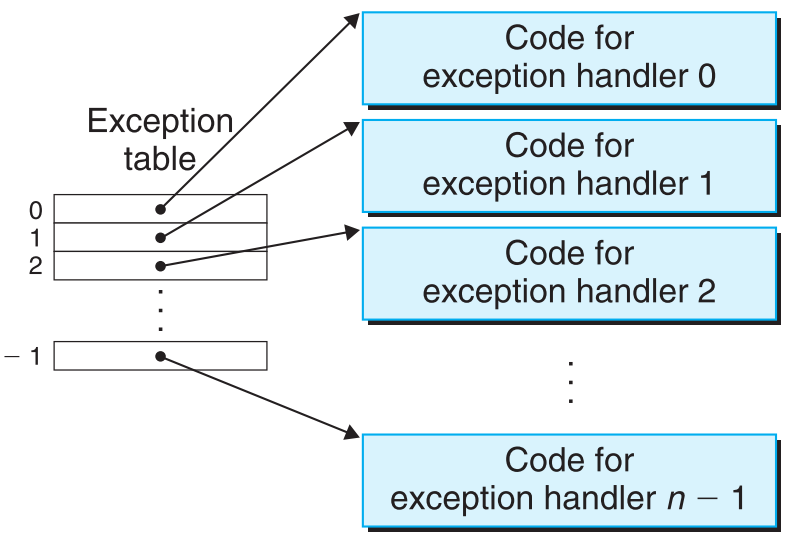
- 在操作系统运行阶段(系统开始跑其他程序了)
当处理器捕捉到一个事件时,它会自动判断这个事件属于哪类异常,然后把它与这类异常的标号k绑定。接着拿着这个k去查exception table,找到对应的处理异常k的句柄并调用。Exception table的首地址存储在一个特别的寄存器中:exception table base register
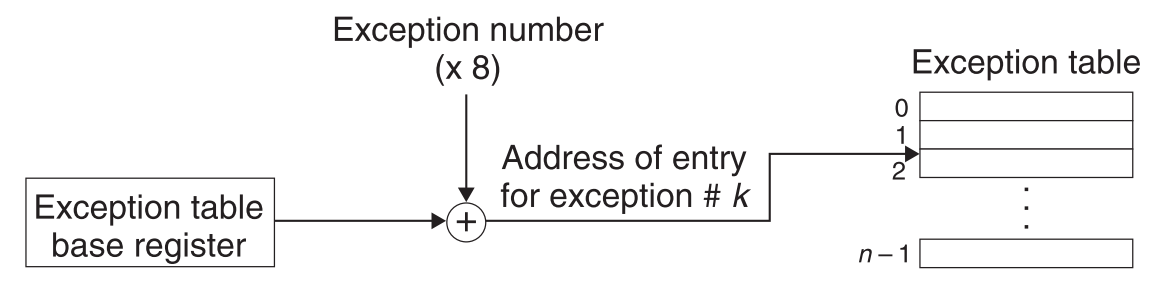 )
)
8.2.1.1exception handler与普通函数的区别
普通函数执行时,它唯一的返回地址会被push到栈上。
excetpion handler执行时,根据exception类型的不同,它的返回地址可能是事件触发时正在执行的指令地址或者事件触发时的正在执行指令地址的下一条指令地址。另外,所有的exception handler都运行在内核态(它可以使用所有的系统资源),处理器不光会将它的返回地址入栈(不是用户栈,而是内核栈),还会将一些必要的用于重启被中断的程序的参数入栈(比如x86系统将EFLAGS寄存器们入栈,这些寄存器中就存储了程序的状态信息,详细可参看的逆向篇内容《汇编基础:标志寄存器》),当exception函数运行完毕时,它会执行一个特殊的指令,该指令将处理器和数据寄存器恢复为用户态,然后把控制交还给之前被中断的程序。
8.2.2 Classes of Exceptions
Asynchronous exceptions是由非当前运行的指令引起的(如I/O信号),Synchronous exceptions是由当前运行的指令引起的(如除0或非法读写内存)

8.2.2.1 Interrupts
I/O信号引起的中断被称为Interrupts,正因为它并不是由当前执行中的指令所引起的,而是由硬件这样的外部因素引起的,因此它被归类为异步的(Asynchronous)中断。用于处理interrupts的handler被称为interrupts handler。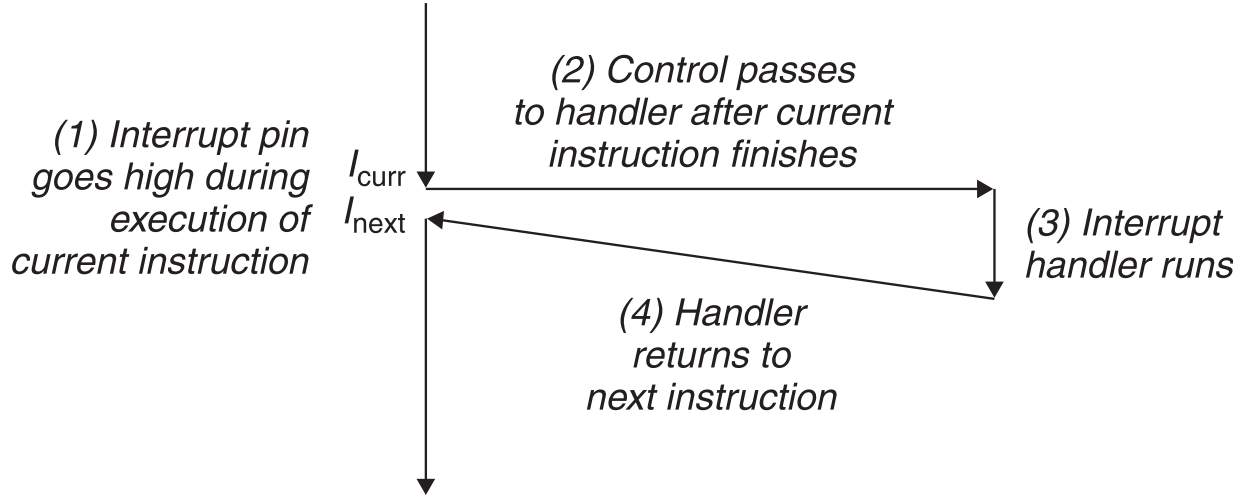
一方面I/O设备先发信号给处理器,使得处理器上的interrupt pin电位变高,然后把能够标识自己的exception number放入系统总线。另一方面,当执行完当前指令时,处理器发现自己的interrupt pin电位变高了(它就知道有interrupt发生了),就会去系统总线中读取exception number,然后调用对应的interrupts handler并执行。当handler执行完毕后,它会把控制交给引发Interrupts的指令的下一条指令,然后程序就继续从该指令开始执行了。在外部看来就好像这个exception从来没有发生过一样。
8.2.2.2 Traps and System Calls
Traps是由程序内部正在执行的指令引起的,因此它是同步的(synchronized)。与interrupt handlers一样,trap handlers也会在返回时把控制交给引发Trap的指令的下一条指令。Traps最重要的作用就是给用户提供内核函数的接口,也就是system call。
我们写的程序中经常要用到一些内核函数,如读文件,创建新进程,结束进程等,我们不能够直接调用内核函数,需要trap handler作为中间人去帮我们调用相应的内核函数。
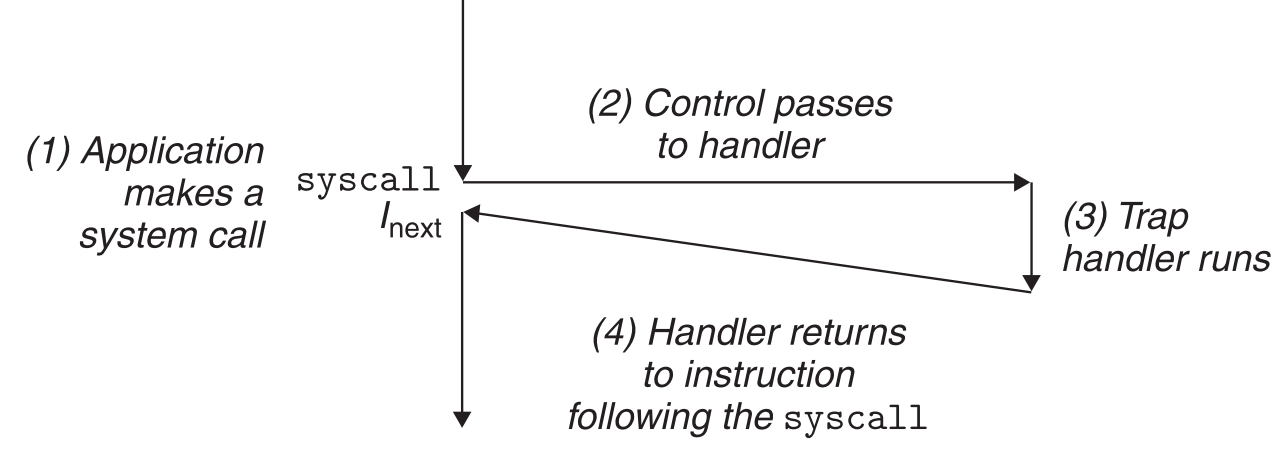
从程序员的视角来看,sysytem call和普通的函数没啥区别,事实并非如此。普通函数在用户态运行,它能够执行的指令类型是受限制的,并且在运行中它只能访问属于自己的栈空间。而内核函数则运行在内核态,它可以运行所有类型的指令,并且可以访问任意内存空间。
8.2.2.3 Faults
引发Faults的是那些有可能被handler纠正的错误。发生Faults时,处理器把控制交给Faults handler,它开始尝试对这个错误进行纠正,如果纠正成功,则handler结束运行,把控制交还给引发Faults的指令(注意并不是它的下一条指令),从它开始继续执行。如果纠正失败,就会把控制交给内核函数abort来中止程序。
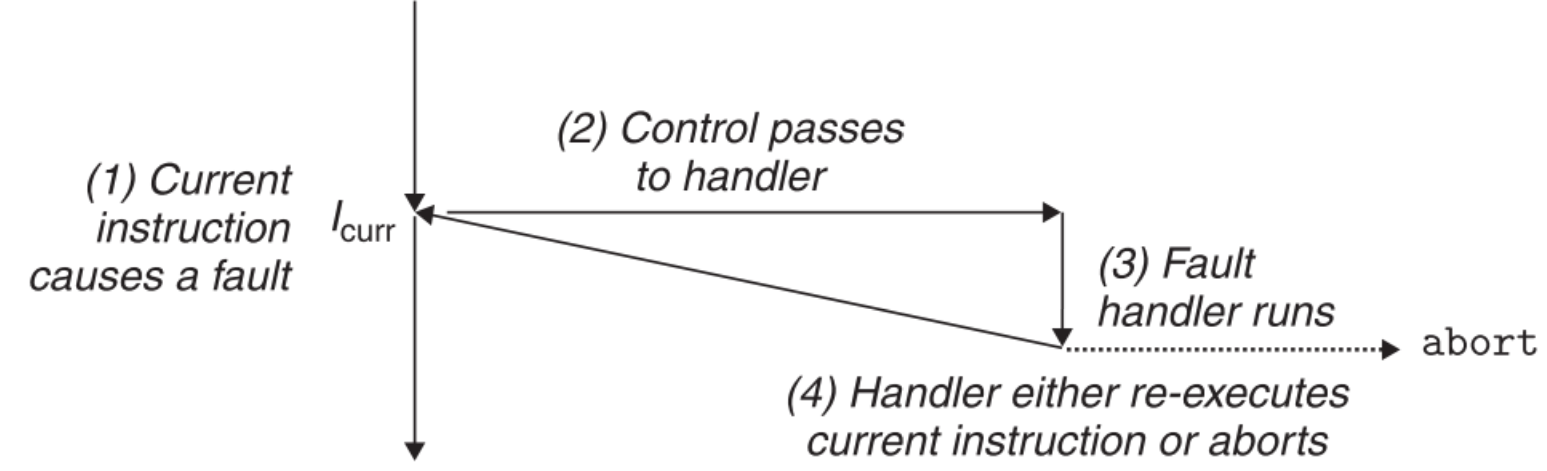
一种经典的Fault就是page fault exception。当指令请求读取虚拟内存中的某个地址时,如果这个地址所属的page还没被cache到虚拟内存中,就必须要先去disk中把这个page取到虚拟内存里,再读取其中的目标地址,这就引发了Fault(为什么从disk读取数据到内存会引发中断之前已经讨论过)。Fault handler的作用之一正是去disk中把需要的page取到虚拟内存中,然后把控制返还给引发Fault的那条指令(请求读取虚拟内存中某地址),从它开始继续执行(相当于它被执行了两次),这一次当然不会引发Fault了,程序继续往下运行。(这部分具体内容在下一章详细说明)。
8.2.2.4 Aborts
只有无法被Faults handler纠正的严重错误才会引发Aborts,Aborts handler永远不会把控制交还给程序,而是传给内核中的abort routine来让它终止程序。
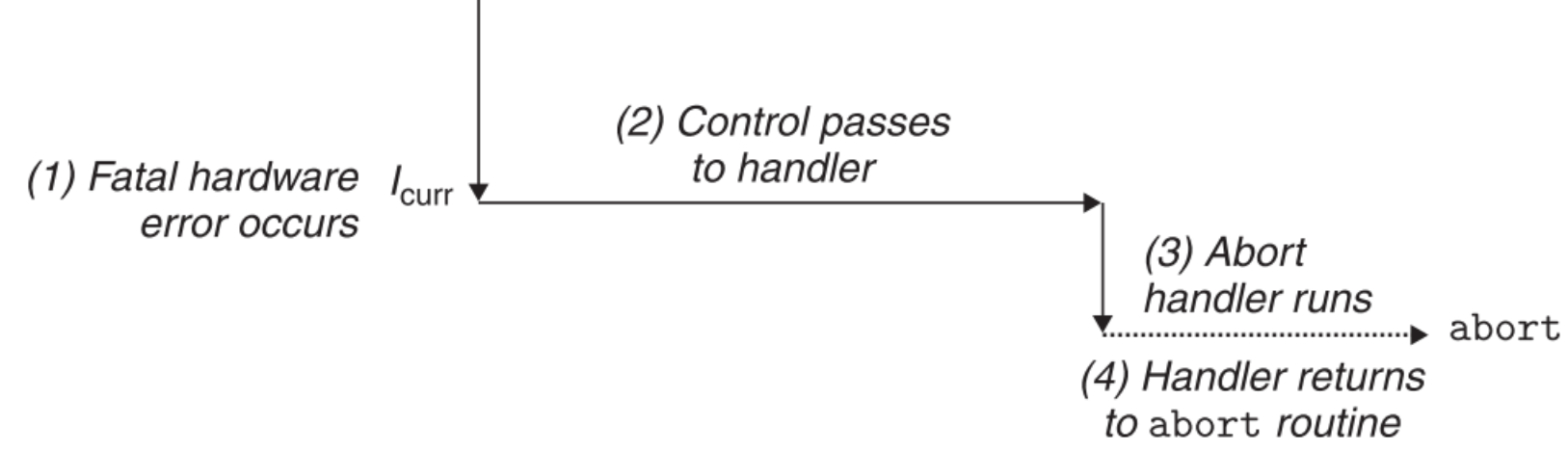
可以发现,凡是在return时会把控制交给事件发生时正在执行指令的下一条指令的exception,都不是由错误引起的,因为return到下一条指令的目的就是要让程序保持事件发生前的状态,继续正常执行,让外部看起来好像没发生过中断一样;而return到引发事件的那条指令的目的,就要做一些修正,然后重新执行当前指令。
8.2.3 x86-64系统中的Exceptions

| Exception | Description |
|---|---|
| Divide error | 除0时触发,无法被修复直接abort,报错提示为“Floating exceptions |
| General protection fault | 引用未初始化的内存地址或者对只读区域进行写操作等都会触发,无法被修复直接abort,报错提示为”Segmentation fauls” |
| Page fault | 这是一种可以被恢复的fault,前面已经介绍过 |
| Machine check | 因严重的硬件错误所引发,直接abort |
8.2.3.1 x86-64的System Calls
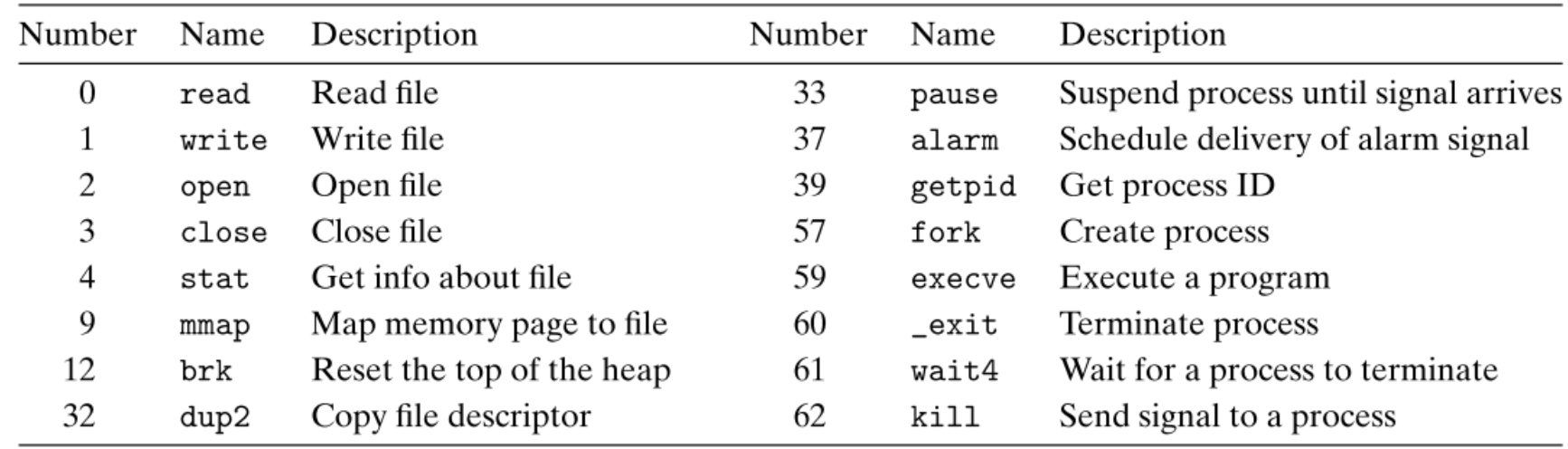
程序员几乎不会直接调用System Call,因为那太麻烦了,还需要我们处理一系列的问题,所以各种语言几乎都会把System Calls包装好,把最顶层的接口提供给我们。
在linux中,system calls的参数都是通过寄存器传递的
8.2.3.1.1 栗子
1 | int main() { |
直接用system call “write”来取代printf,第一个参数就是系统函数write的编号1,第二个参数要write的字符串,第三个参数为字符串的长度。如果要打印其他格式,还要对它进行一些包装。
相比之下printf(“hello, world\n”)是不是简单多了?
8.3 Processes
进程:执行中的程序实例,内核利用ECF机制抽象出了进程的概念。
系统中的每一个程序都是在某一个进程的上下文环境(context)中运行的,这个context包括了所有程序正常运行所需要的states(比如保存程序装载在内存中的code和data区,通用寄存器的内容等)。
从我们的角度来看,每一个运行中的程序就像是独占了CPU和内存一样,实际上我们知道事实绝非如此,那么这一切到底是如何实现的呢?
8.3.1 Logical Control Flow
比如我们在系统上同时运行了三个程序A、B、C,则它们会把处理器(单核)的一个物理控制流划分为三个逻辑控制流。
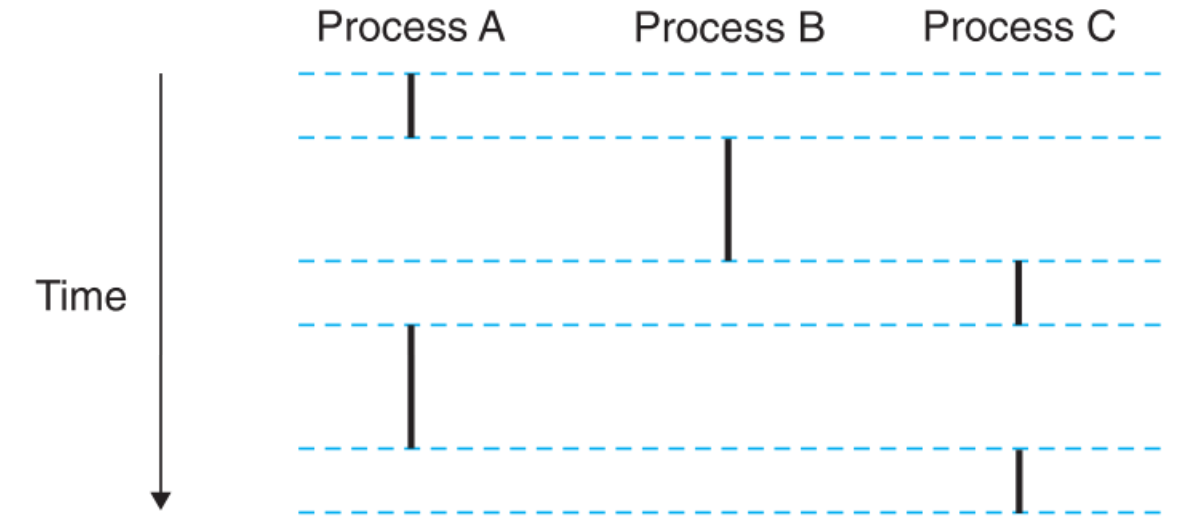
每个进程都会在某一段时间内独占物理控制流执行,虽然中途CPU的资源会被其他进程抢占过去,但是由于CPU的运行速度非常快,以至于程序切出又切回的这段时间我们根本感觉不到,并且每次切换都会进入到某个进程独立的上下文空间中,这样在切回某进程时它的状态还是与切出时一模一样,因此给我们带来一种单个进程独占CPU的资源的感觉。
8.3.2 Concurrent Flows
逻辑控制流有许多形式:比如Exception handlers、进程、线程等。
当多个逻辑控制流在同一时间间隔内同时运行时,我们就称它们为Concurrent Flows,即它们是并发的。
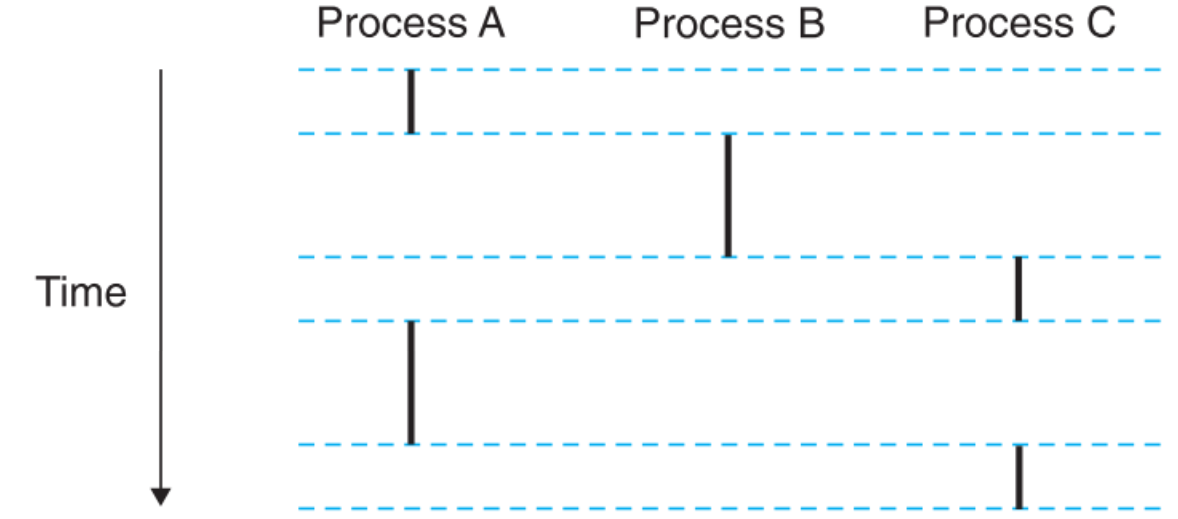
如上图A与B,A与C之间都是并发的(时间线重叠),而B与C之间不是并发(分别在不同的时间段执行)。
可以看到,图中有单一进程被时间划分为多个小段(如A被分为两段),进程在每一个小时间段内执行一下,这些时间段被称为进程的时间片(time slice),并发的过程就是给进程划分时间片(time slicing)的过程。
并发这个概念与处理器是单核还是多核无关,只要两个进程运行的时间线重叠,无论它们是跑在同一个CPU上(伪同时运行),还是分别跑在两个CPU上(真同时运行),都被称为并发。
而我们常说的并行(parallel,真同时运行)是并发的子概念,它特指多个进程在不同CPU上同时运行。
8.3.3 Private Address Space
每一个进程都有自己的私有地址空间,其他进程无法访问这段空间。私有地址空间的结构都是一样的:
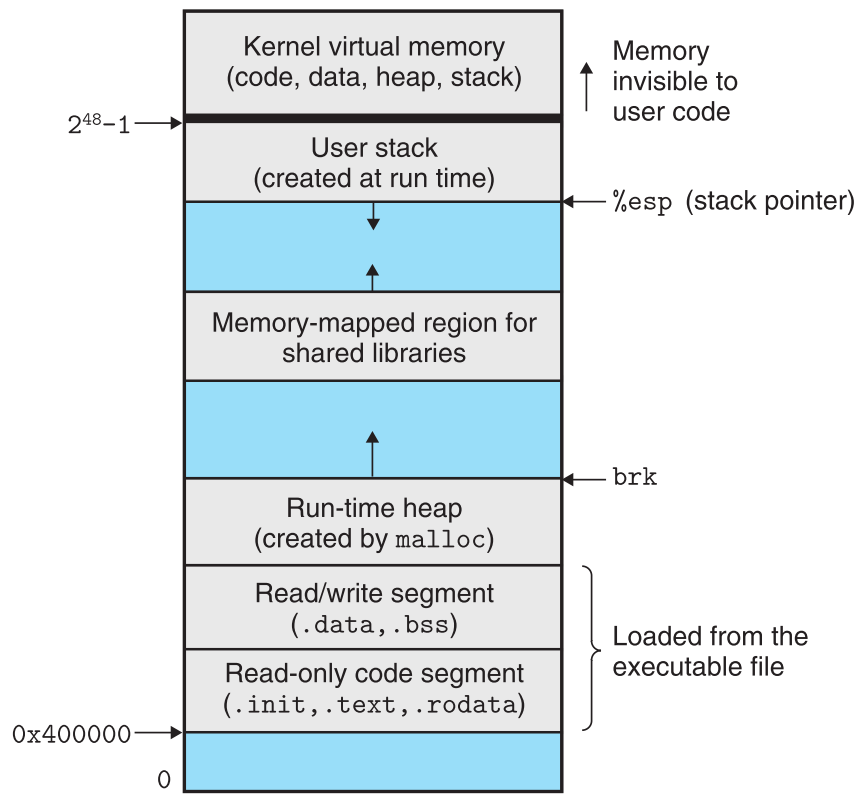
8.3.4 用户态与核心态
为了抽象出内核的概念,处理器上必须有一系列的机制来限制普通程序可以使用的指令以及可以访问的地址空间。处理器上的一些控制寄存器会提供mode bit来表示当前进程拥有的权限。
当mode bit为1时表示当前进程跑在内核模式, 此时它可以执行所有指令并且访问系统中的任意地址空间。
当mode bit为0时表示当前进程跑在用户模式,该进程无法执行一些指令(比如暂停处理器,改变mode bit,直接发起I/O操作等)。同时它也不能直接访问内核区域的地址空间,只能通过包装好的system call来间接访问。
任何进程最开始都是跑在用户态的,想将其改变为内核态唯一的方法就是通过exception(interrupt、fault或者system call)。当进程触发exception时,control被传递到exception handler,因为exception handler是运行在内核态的,因此进程会被转变为内核态,当它return后,处理器会把mode bit置为0,使它变回到用户态。
注意handler是由于中断而被调用的,它运行时原程序处于暂停状态,因此它并不与原程序并行,而是与原程序同属于一个进程。
8.3.5 Context Switches
操作系统通过Context Switches来实现多进程并行,而Context Switches技术正是由8.2.2的那些技术拼接封装实现的。
内核为每一个进程维护了一个Context。所谓Context,就是内核为了重新执行那些被抢占了的进程所需要的信息。
| 信息 |
|---|
| general-purpose register |
| floating-point register |
| status registers |
| PC |
| 该进程的用户栈 |
| 内核栈 |
除此之外,还有一些内核的数据结构
| DS | function |
|---|---|
| page table | 描述地址空间 |
| process table | 描述当前进程 |
| file table | 描述当前进程打开的文件信息 |
在进程的运行期间,内核可以决定是否要暂停它,转而去执行其他进程。这些决策(scheduling)都是通过内核中的scheduler做出的。当内核schedule了一个新的进程,它就会先将当前进程的运行资源收回,然后通过context switch把控制交给其他的进程,context switch的过程如下:
- 保存当前进程的context
- 恢复将要运行进程的context
- 将control传递给将要运行的进程
当内核执行某个用户调用的system call时,可能发生context switch
当这个system call运行到一半需要暂停等待某个事件发生时(比如使用read从disk上读取数据),CPU会利用中途等待数据传输的时间,进行context switch执行其他进程。
interrupt也会引起context switch
系统一般都要让进程周期性的被interrupt,这样做的原因是避免算法的缺陷导致某个进程长期拿不到CPU资源,用户就会觉得很卡。每隔一小段时间中断一下,然后看看当前进程是不是已经执行了足够长的时间,决定要不要换其他的进程来执行一下以确保CPU资源合理分配。
进程A从disk读取数据时发生的context switch
context switch是由kernel完成的
8.4 Process Control
我们可以调用一些system calls来操控程序中的进程。
8.4.1 获取Process ID
每一个进程都由一个独一无二的PID(正整数)标识,我们可以调用系统函数获取当前进程的PID或者当前进程的父进程(调用当前进程的进程)的PID。
8.4.2 创建和中止进程
从程序员的视角来看,进程拥有三种状态。
| State | Explain |
|---|---|
| Running | 进程正在运行中,或者正在等待CPU资源,且最终一定会被执行 |
| Stopped | 进程被暂停了,在被特定信号唤醒之前,不会被执行 |
| Terminated | 进程被中止了。可能是收到了停止命令,也可能是从main函数return,还可能是因为调用了exit函数 |
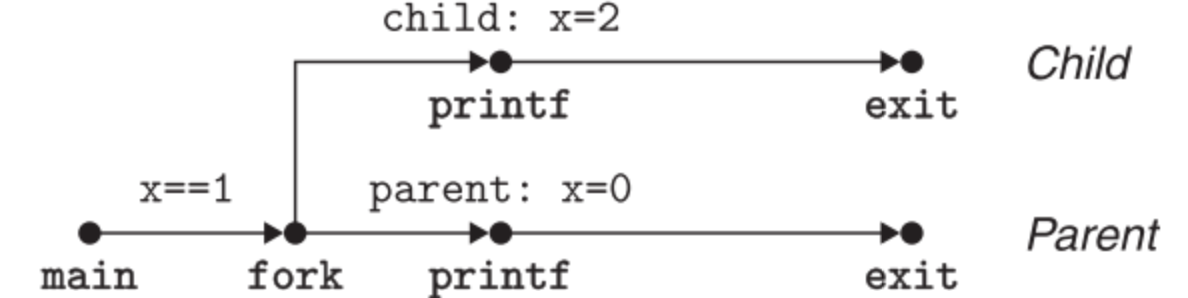
我们可以使用fork函数来基于当前进程生成一个它的子进程。子进程的虚拟地址空间是其父进程的副本,同时它还可以对父进程中打开的文件进行读和写,它们唯一的不同之处就是PID不同。
fork函数的特殊之处在于,它会return两次,一次在子进程中return 0,一次在父进程中return子进程的PID。要注意的是,子进程与父进程谁会先return是不确定的(并行所导致的)。
8.4.2.1 栗子
1 | int main() { |
其打印结果为:
parent: x=0
child : x=2
fork()调用完后,main进程被分成了两个线程,它们同时从fork()下一句开始继续执行。此时可以通过rePid(即fork()的返回值)来判断当前是位于子进程中还是父进程中。(注意子进程的PID一般是父进程PID+1,其返回值是0)
并且这两个独立的进程运行结果都打印到了同一个console上,这也印证了子进程继承了父进程的状态,使用的是父进程中打开的stdout文件。
再看一个复杂点的栗子帮助理解。
1 | int main() |
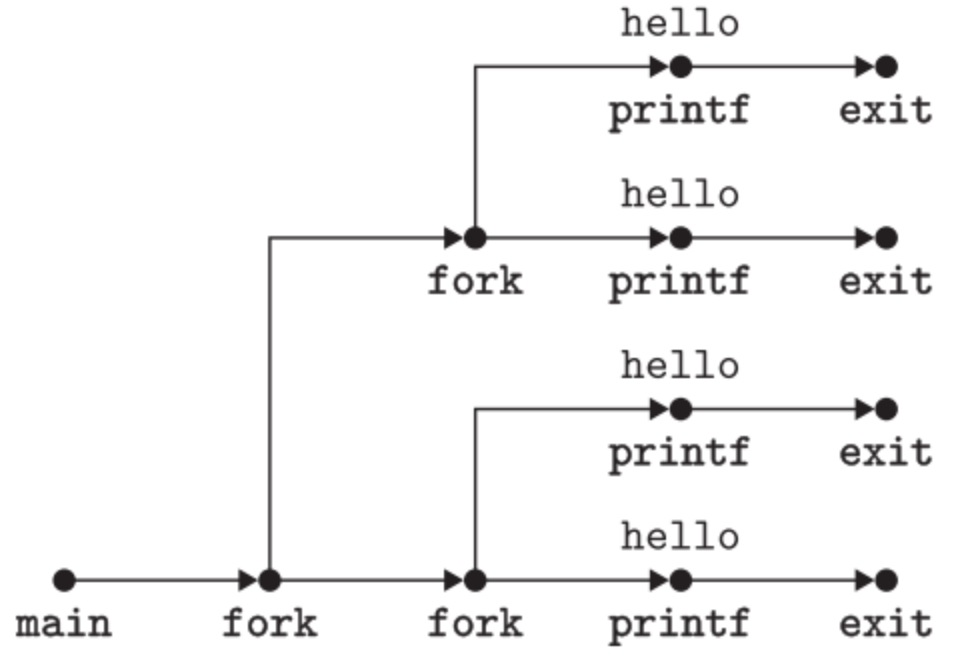
在这样的流程图表示中,任何一个拓扑排序都是一条可能的执行顺序。因为进程的调度是由内核来决定的,其算法是基于当前系统情况的,因此执行顺序是不固定的。
8.4.3 Reaping Child Processes
当一个进程被中止时,它依然还存在于系统中,处于一种僵尸的状态(已经无用了,却依然消耗系统资源)。只有当它的父进程明确要reap掉它时,内核才会真正的把它给释放掉。
若想要释放的进程本身就是父进程该怎么办呢?系统提供了一个PID为1的进程init(系统启动时它就被内核创建了),它是所有进程的父进程,只要系统在运行,它就一直在运行。
不仅如此,当某个进程被释放前它的父进程就被中止时,init也负责reap掉这些未被释放的子进程。(要注意的是,像shell这类长期运行的程序,一般都要自行reap掉僵尸进程,否则会极大的浪费系统资源)
8.4.4 Putting Processes to Sleep
调用sleep()可以让程序暂停一段时间再执行,在sleep期间可以可以被强行唤醒。
也可以调用pause()让程序永久暂停,直到被强行唤醒才可继续运行。
8.4.5 Loading and Running Programs
调用execve()函数可以将程序加载进内存并运行,它只有当发生错误(比如找不到文件名)时才会返回值,因此不同于fork()的return两次,正常时它压根就不会return。
它的函数原型如下:
1 | int execve(const char *filename, const char *argv[], const char *envp[]); |
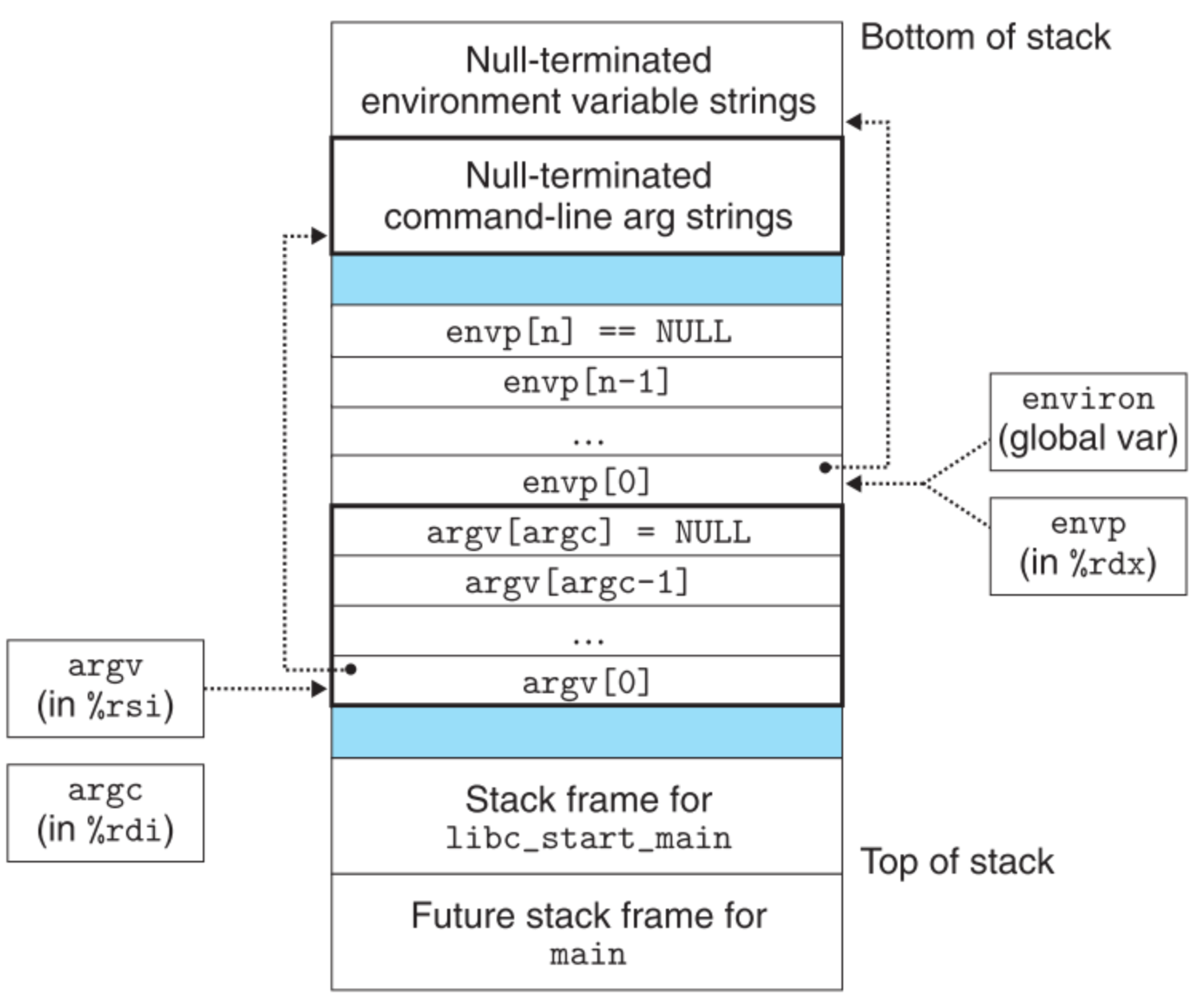
当execve成功读取了filename后,会调用一个start-up code,它将堆栈初始化并将控制传递给main函数:
1 | int main(int argc, char *argv[], char *envp[]); |
它的第一个参数就是execve的argv数组中有多少个值。(观察这两个函数的异同点)
当一个新程序开始运行时,其用户栈是这样的:
8.5 Signals
Signal是一种软件层的exception control flow,它的作用是通知某进程,系统中有某与其相关的事件发生,这种机制使得内核或某进程可以主动中断其他进程。
传输signals分为两步
发送
一般碰到如下两个情况时,内核会发送signals(实质是改变目标进程状态参数的形式),
· 内核检测到了一些系统事件时(比如除0,中止某进程)
· 某个进程调用了kill方法,明确要求内核发送信号给某进程。(进程可对自己调用kill,注意此处的kill并不是linux中的中止进程指令)接收
接收端进程对signal做出反应。它可以无视或中止这个signal,也可以通过调用用户层的signal handler函数来catch这个signal。
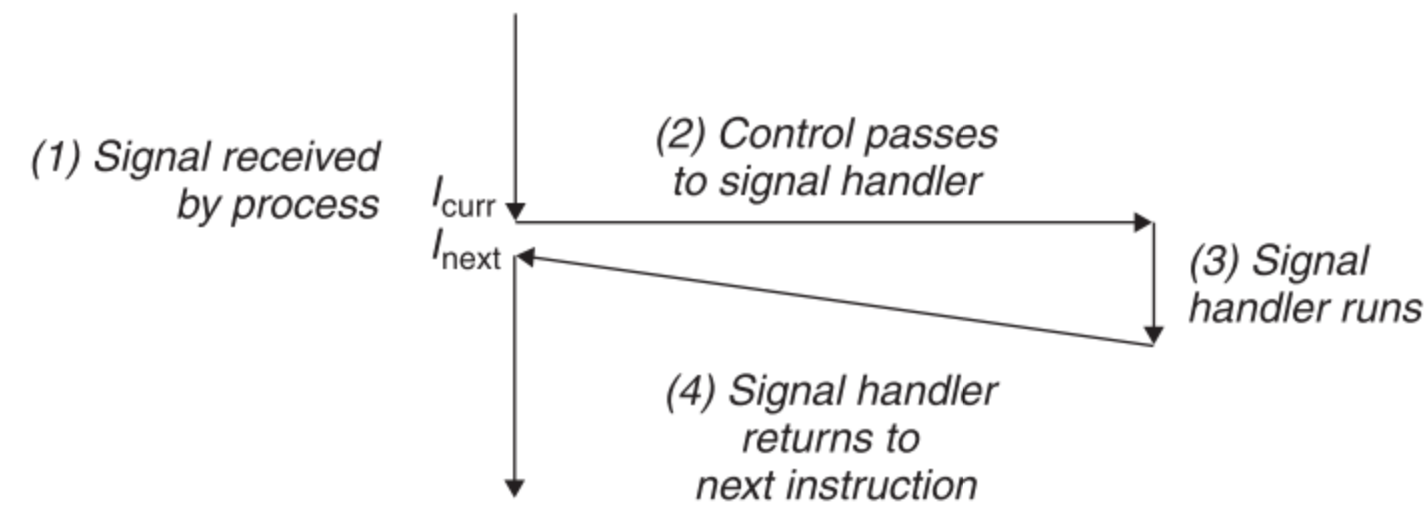
已经被发送,接收端尚未对其做出反应的叫pending signal,内核会对每一个进程维护一个pending vector(bool类型),一个队列中只能同时存在不同种类型的pending signal,如果后续收到了类型重复的signal会直接被丢弃。(内核发送signal k后,将目标进程的pending vector的第k位设为1,表示其处于pending状态,当k被目标进程接收后,队列位置k的值被重新置为0)
某进程可以选择block某种signal,被block的signal可以以该进程为目标发送,存入到该进程的pending vector中,但在解除block之前,它是不会被接收的,因此内核还维护了一个blocking队列来表示某signal是否被blocked。
8.5.1 发送信号
linux有一系列的机制来给进程发送Signals,这些机制全都依赖于process group来实现。
8.5.1.1 process group
每一个进程都仅属于一个process group,每一个process group都被一个唯一的正整数标识(process group ID)。默认情况下子进程与父进程同属于一个process group,但是进程可以修改它自己或者其他进程的process group ID。
为什么子进程与父进程同属于一个process group
因为一个process group(进程以及它的子进程)是属于同一类的,一类进程总体上来看是服务于一件事的(这件事被Unix shell称为job),我们一般都是对这整件事来操作,而不会对单个进程进行操作,因此就需要用一个统一ID来标识处理这整件事的所有进程,来对整件事进行操作。
在任何时候一个shell前台只能有一个job,后台可以有0~多个job。
以下示例,shell创建了一个前台job和两个后台job,前台进程又创建了两个子进程(pid进程号,pgid进程组号)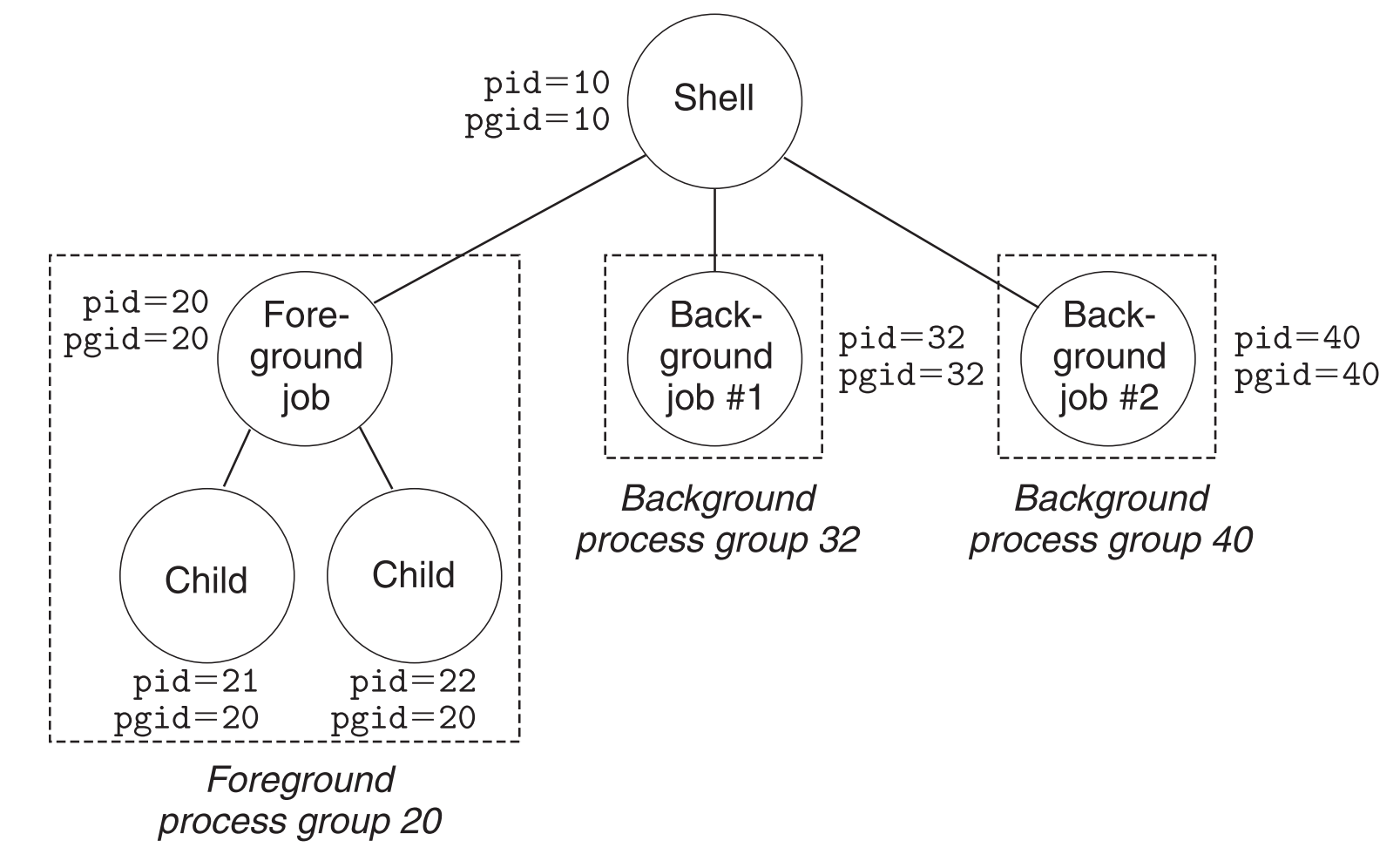
前台进程和它的子进程同属于一个process group。
8.5.1.2 通过键盘发送signals
比如linux中按【Ctrl+C】让kernel将中断信号发送给前台process group中的所有进程,将前台的job中止。
8.5.1.3 通过kill函数发送信号
任何进程都可以通过调用kill函数来发送信号给其他进程(包括它们自己)。
它的函数原型如下:
1 | int kill(pid_t pid, int sig) |
当pid大于0时,它会发送编号为sig的信号给进程pid;
当pid等于0时,它会发送sig信号给调用它的进程所属进程组的所有进程以及调用它的进程本身;
当pid小于0时,他会发送sig信号给|pid|进程组中的所有进程。
8.5.2 接收信号
当内核将一个进程p从内核态转换为用户态时(比如从system call中返回或者执行完context switch时),它会先通过(pending&~blocked)的结果来检查是否还有待处理的未被阻塞的信号,如果结果为空,则它直接将控制交给逻辑控制流p的下一条指令;若结果非空,则内核就会选择一个pending的信号k,让p去接收它。当完成这个信号要求的动作后,再将控制交给p的下一条指令。
进程对信号做出的反映默认有以下几种:
- 终止进程
- 暂停进程,让它直到接收到特定信号才能被唤醒
- 无视这个信号
然而这些默认的动作大部分都可以使用signal函数修改,它的原型如下:
1 | sighandler_t signal(int signum, sighandler_t handler); |
它可以改变编号为signum信号的默认动作,根据handler类型的不同,分为以下三种情况:
| handler类型 | 改变效果 |
|---|---|
| SIG_IGN | 无视对应signum信号 |
| SIG_DEL | 将对应signum信号动作重置为其默认 |
| 用户自定义函数的地址 | 称之为signal handler,一旦某进程接收到对应的signum信号,就会去执行这个用户自定义的函数。这种自定义信号的行为叫做installing the handler,调用这种信号的handler的行为叫做catching the signal,执行这个handler叫做handling the signal。 |
signal handler执行效果如下(信号s引起中断,因为s的默认动作被修改了,因此在s动作执行的过程中还会因为调用signal handler从而引起另一个中断),同时这也说明了handler是可以被其他handler打断的。
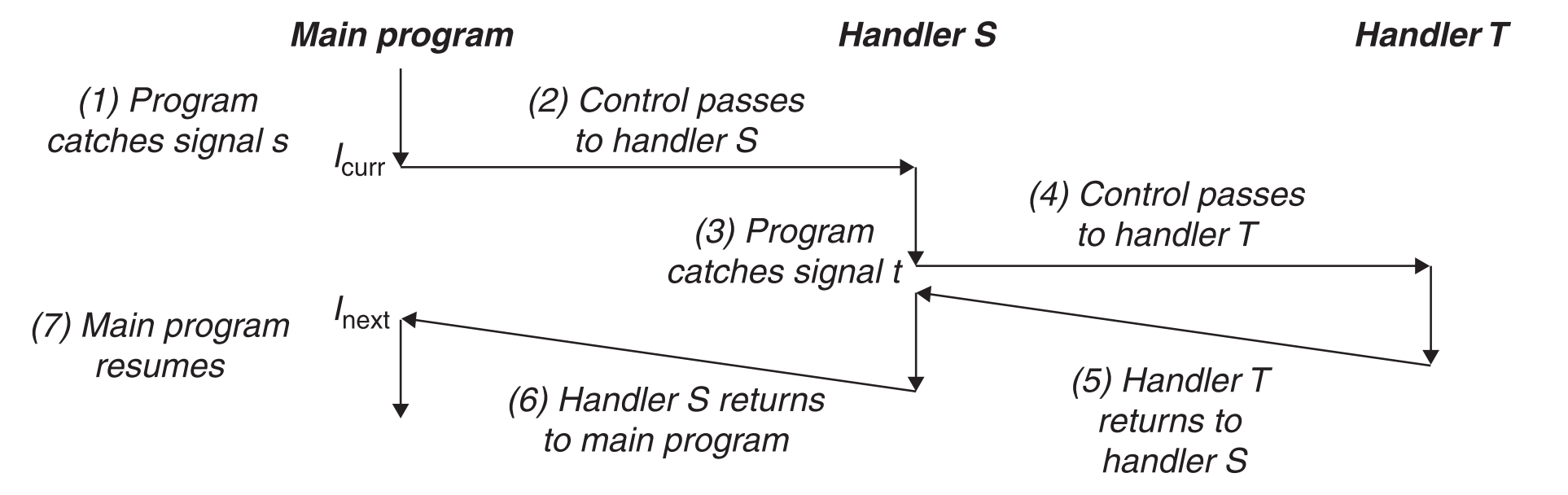
8.5.3 阻塞和恢复信号
linux中有直接和间接两种方式来阻塞信号。
- 间接阻塞
内核会阻塞任何一个正在被处理的信号。比如某进程接收到信号k,在处理信号k的过程中又收到一个信号k,则会默认将其阻塞。 - 直接阻塞
调用函数sigprocmask()明确阻塞某种信号。
这个函数可对block vector进行更改,他的函数原型如下:第一个参数how决定了如何更改blocked vector:1
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset);
| 参数 | 动作 |
|---|---|
| SIG_BLOCK | 将set中的信号阻塞,blocked=blocked | set |
| SIG_UNBLOCK | 将set中的信号恢复,blocked=blocked & ~set |
| SIG_SETMASK | blocked=set |
如果oldset是非空的**,它指向更改前的blocked vector。
8.5.4 等待信号
比如shell创建了一个前台job后,shell就必须等待这个job结束且被reap掉后,才能去接收用户的下一条指令。