《CSAPP》Linking
7.1 Introduction
linking实际上就是把多个文件链接起来合并成一个文件的操作。
Linking不光是在编译阶段存在,在load time(loader把程序加载进内存时)也存在,甚至在程序的运行阶段也存在。我们把执行linking功能的程序叫linker。
linker对程序开发最大的贡献是它使整个程序模块化了,试想如果没有linking机制,则所有的代码都得写在本程序文件中,像打印和读取类的几乎每个程序都会用到的函数,也得每个程序都复制一份,很麻烦不说,如果之后这些函数更新了,则所有使用了它们的程序都得被手动更新。为了解决这些问题,linking技术诞生了。
理解linking的过程有啥用?
可以解决不同文件中全局变量重名造成的bug
帮助理解局部变量和全局变量的区别,static关键字的底层意义
利用shared libraries机制完成一些特定的任务
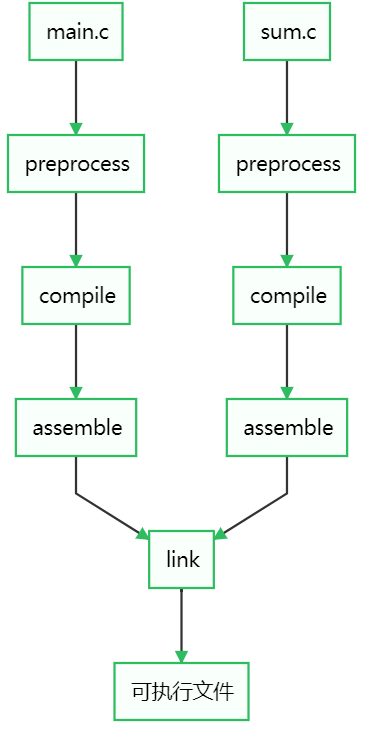
7.1.1 Compiler Drivers
Compiler Driver的作用是启动preprocessor(预处理器),compiler(编译器,程序文本转汇编代码),assembler(汇编器,汇编代码转二进制,这一步生成【object_file】,即.o文件),linker(链接器)这些编译过程中需要用到的程序。
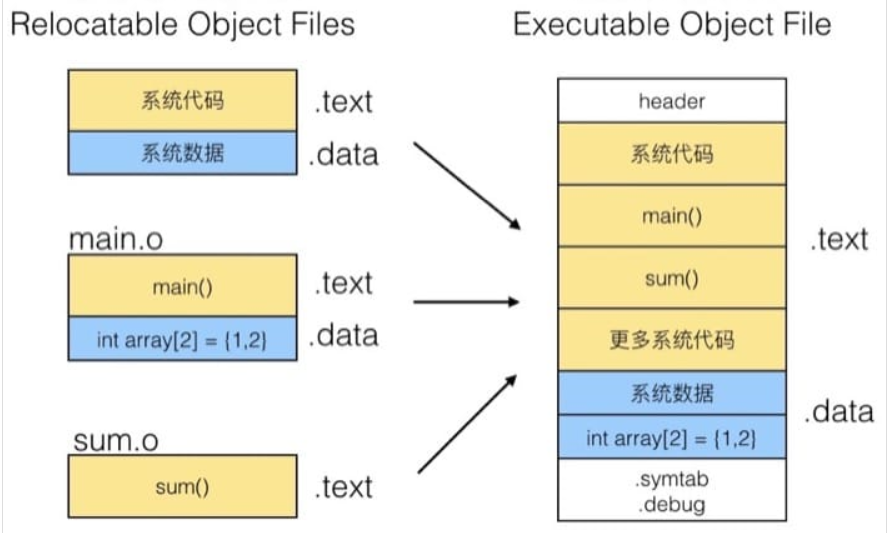
7.1.2 栗子(多个文本文件→一个可执行文件)
main.c函数中include了sum.h头文件
7.2 Static Linking
7.2.1 linker最基本的两个功能
7.2.1.1 symbol resolution(linking阶段发生)
Object file中其实全是symbols(变量名和函数名以及一些重载机制只是方便我们开发者,到了真正的可执行文件中这些对象都被转为符号形式了),每一个symbol都对应了一个函数或一个全局变量或一个static变量的引用(注意只是引用,而非定义)。因此所谓符号解析就是建立symbol和symbol definition之间一对一的映射。
比如函数void foo();是声明,调用foo()就是引用,而foo()的定义可能在本文件中或其他文件中。普通变量同理。
7.2.1.2 relocation(linking时或load进内存时发生)
load进内存时
Compiler和assembler从文件地址0处开始生成程序的代码和数据。然而这些代码和数据被加载进内存后不可能依然从0开始存放(内存有自己的格式),所以linker要对它们进行relocation操作,首先将每一个symbol definition(开始存放在逻辑地址空间)放入内存中适当的地址(物理地址空间),然后修改所有symbols,使它们指向symbol definition在内存中的地址。这些relocation操作都是根据assembler生成的重定位表来进行的。
linking时
合并多个relocatable object files必然会有地址冲突,此时就需要用重定位来解决。
7.2.1.3 小结
总之,linker要做的两件事是符号解析和重定位,前者将文件中的每个全局符号与其唯一的定义绑定;后者决定每个符号最终在内存中的地址,并将这些符号的引用修正。
7.3 Object File
Object files分为三种类型
- Relocatable object file:包含编译阶段可与其他Relocatable object file链接成为可执行文件(executable object file)的二进制的代码和数据,
- Executabe object file:包含可以直接被加载到内存中并运行的二进制代码和数据。
- Shared object file:一种特殊的relocatable object file,它可以被加载进内存并动态的链接(在程序被加载进内存时或者运行时)
compiler和assembler对文件加工生成relocatable object files(包括shared object files),linker对所有的relocatable object files加工生成executable object files。
object file是根据object file formats生成的,不同系统的formats是不同的。比如bell实验室的第一个unix系统用a.out格式,Windows中的PE格式,linux中的ELF格式。但它们的结构和原理其实是差不多的。
7.3.1 Relocatable Object Files
7.3.1.1 典型的ELF relocatable object file格式
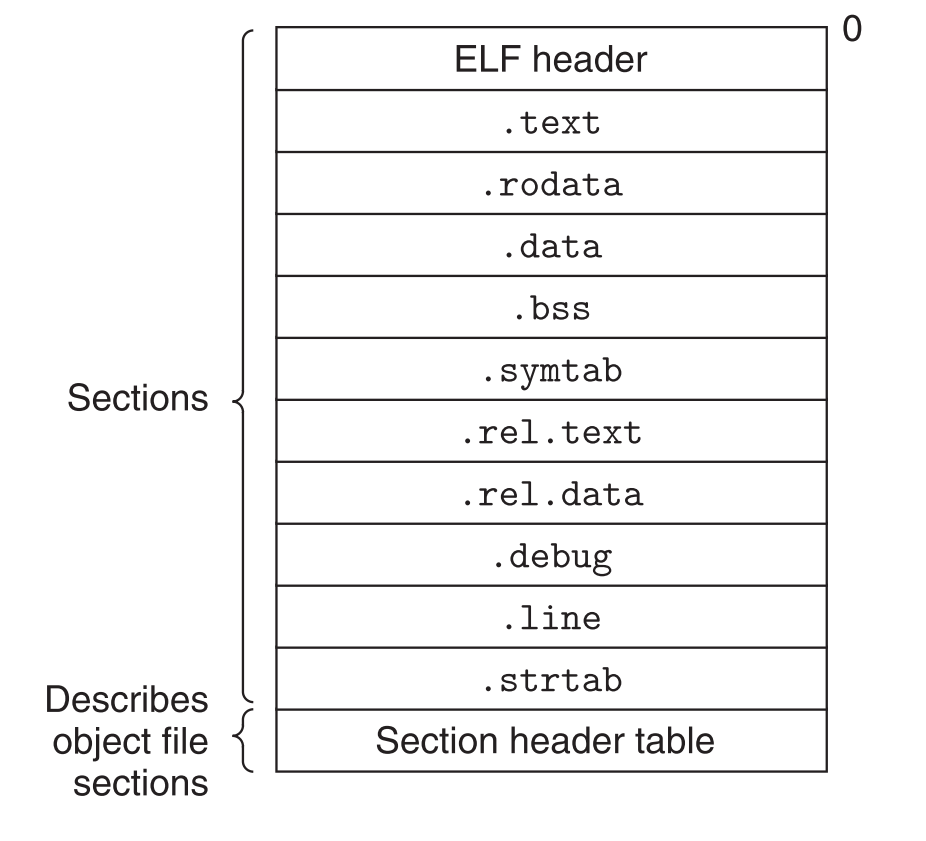
7.3.1.2 ELF relocatabl object file格式解析
| section name | 功能 |
|---|---|
| .text | 存放程序汇编处理后的机器码 |
| .rodata | 存放只读数据(如switch的跳转表) |
| .data | 存放赋了非0初值的全局和static变量 |
| .bss | 存放未赋初值的static变量和赋了初值为0的全局和static变量(未赋初值的全局变量存在符号表的COMMON区中),这个section在object file中只是一个占位符(不占用实际空间)。把数据区分为.data和.bss的目的就是为了降低硬盘中object file的体积,因为没有赋初值或初值为0的变量可以等到程序跑起来时再在内存中(全局数据区)给它们赋初值0。经常用.bss来指带未赋初值的数据,可以这样记忆“Better Save Space” |
| .symtab | 存放了一个符号表,里面有程序中引用和定义的全局变量和函数的信息。不过它和编译器的符号表不一样(编译原理中有详细介绍),注意.symtab中不包含局部变量 |
| .rel.text | 本区包含一个列表,存储着.text区的一些地址,这些地址都是在link阶段合并object files时要被修改的。一般来说,所有要调用外部函数或者全局变量的指令都要被修改,调用局部变量的指令不用修改。 |
| .rel.data | 存储所有被引用或定义的全局变量的relocation信息,一般来说,所有初值为全局变量地址的全局变量,或者外部定义的函数都需要被修改 |
| .debug | 存储debug information |
| .line | 原C语言文件和.text中二进制文件之间行号的映射表 |
| .strtab | 字符串表,存储节表名称和其他信息 |
| note:relocation信息在文件被编译为可执行文件后已经无用了,所以在executable object file的ELF格式中没有.rel.text和.rel.data区。 |
7.3.2 symbols and Object Files
每一个relocatable object file都有一个符号表,里面存储了它内部定义的或者引用自其他文件的符号。
符号分为三类:
| Symbols | explanation |
|---|---|
| Global linker symbols | 在本模块中定义,可以被其他模块引用。比如非静态函数和全局变量 |
| Externals | 引用自其他模块的global linker symbols |
| Local linker symbols | 在本模块中定义,且只能被本模块引用。比如static函数和static全局变量 |
static全局变量或函数只在本模块中可见,non-static全局变量或函数则对外可见。因此可通过static来让全局变量或函数变为私有的。
程序中的局部变量和local linker symbols是不同的。
—符号表中是不会存储局部变量的(局部变量又不给别人用,而且定义在本文件中,不需要做符号解析)
—程序中的局部变量是在运行时才会被初始化和引用的。
—而local linker symbols(即静态全局变量或函数)在编译阶段编译器就会在.data或者.bss中给他分配空间,并且为它创建一个local linker symbol并放入assembler创建的符号表中,用一个单独的名字来标识它。
7.3.2.1 symbol table
符号表是由assemblers创建的,里面的所有信息都是由compiler提供的。。
ELF符号表在.symtab节中,它的格式如下:
1 | typedef struct |
其中的section属性指向节表(section header),节表是用来表述节(ELF header和Section header table中间的那些区块)的。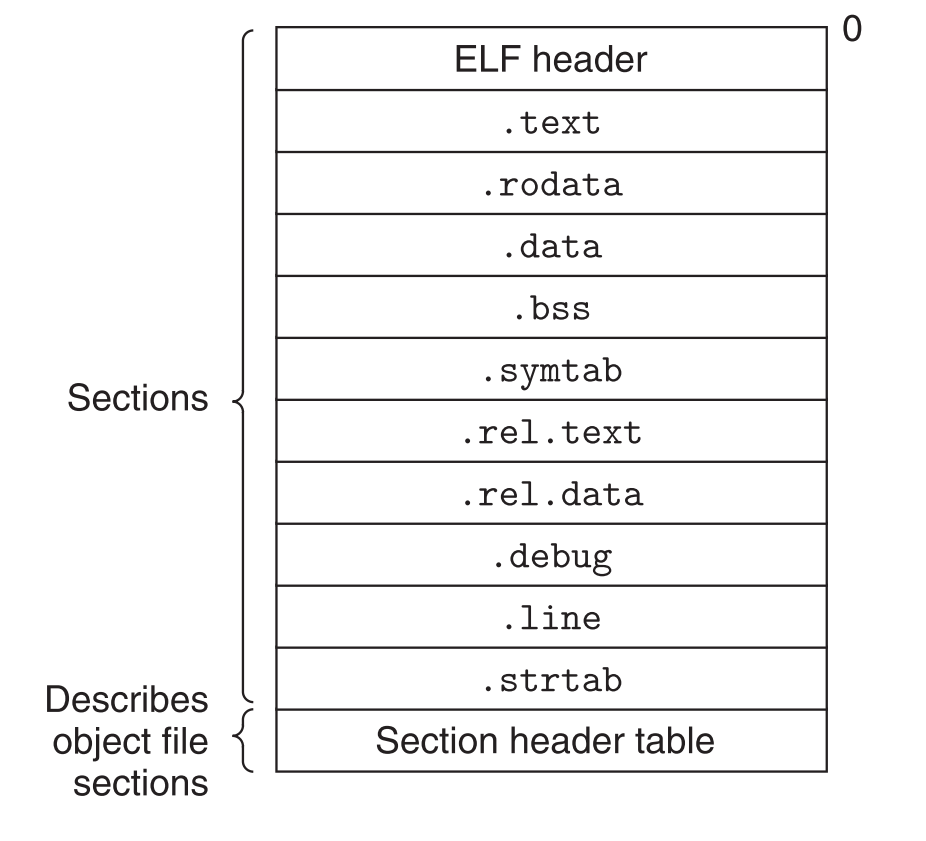
除了图上的这些section,还有一些“伪section”,节表并没有描述他们(它们只存在于relocatable object files)
| 伪section | 作用 |
|---|---|
| ABS | 存储不能被relocate的符号 |
| UNDEF | 存储在其他模块中定义的,在本模块中引用的符号 |
| COMMON | 存储还没有被初始化的(没被分配资源的)数据对象 |
COMMON与.bss的区别
COMMON中存储未赋初值的全局变量。
.bss中存储未赋初值的static变量,或赋了初值0的全局变量和static变量。
这样划分的原因在下一小节中。
7.4 Symbol Resolution
解析符号的方法是通过该符号与该符号本身所属的relocatable object file中的符号表进行比对匹配解析的。
7.4.1 解析本模块中定义的符号
compiler直接拿它在本模块的符号表比对匹配即可,因为定义就在本模块的符号表中。
7.4.2 解析定义不在本模块的符号
compiler会在符号表中生成一个新的条目,把寻找该符号定义的任务交给linker。
如果linker在其他模块中也找不到某个symbol的定义,就会报错。举例如下:
1 | void foo(void); |
另外,解析global symbols还可能遇到不同模块但同名的global symbols,这时linker该怎么办呢?
7.4.3 linkers是如何解析重名符号的
N个relocatable模块作为参数被传入linker中,每一个模块中都有一些符号,这些符号被分为两大类,第一类是local的,他们只能在本模块中被使用;另一类是global的,他们能被其他模块调用。这时如果出现两个模块的global符号是重复的情况,linux编译系统会采取如下策略:
在compiler把符号导出到assembler的符号表的过程中,就把global symbol分为强和弱两种状态。
函数或者赋了初值的全局变量都为strong,未赋初值的全局变量都为weak。
global symbol重名情况下采用这样的策略:强弱同名选强,弱弱同名随机选,强强同名报错。
这也是为啥变量要分装在COMMON和.bss的原因,假如compiler碰到一个weak(未赋初值)的global symbol,此时它并不知道其他模块是否有与它重名的symbol,即使有,它也无法确定linker是否会选择自己模块中的这个weak符号。所以compiler会先把这个变量放到COMMON中,等待linker做进一步选择,把最终选择的那个变量放入.bss区。
反之假如compiler碰到的是strong(赋了初值)的global symbol,则可以确定linker一定会选择它(否则报错),因此compiler可以直接把这个symbol放到.bss中。
7.5 静态链接库的原理
静态链接库使程序初步模块化。
我们写程序时一般都要include标准头文件,来使用一些已经定义好的基本功能函数。假设没有静态链接库,要使用基本功能函数我们还得手动从别处copy一份代码到我们的程序中。这样做一来是很麻烦,二个是可能会浪费大量空间(如果想省事把一个类的轮子全部copy),再者是当轮子的内容需要更新时,每一个copy了它的程序都要被一一手动修改,这是无法容忍的。
静态链接库的诞生就是为了解决这个问题,它把某一类轮子合并在一起生成.lib文件后放入目标工程文件中,之后程序中想要用lib中的啥函数,就include对应的头文件。在之后的linking阶段linker只会去lib中link那个库中被使用到的函数,没用到就不link,在节省资源的同时也方便了程序开发。而且之后要修改库文件内容只需要更新.lib中的文件,再重新编译整个工程即可,不需要去逐一手动修改。
7.5.1 栗子
比如我们在.lib中实现了两个函数,addvec和multvec。把该lib粘贴到某工程文件目录下,工程文件的main2.c文件include了该lib,但只调用了addvec函数(以及标准库的printf用于打印结果),过程如下。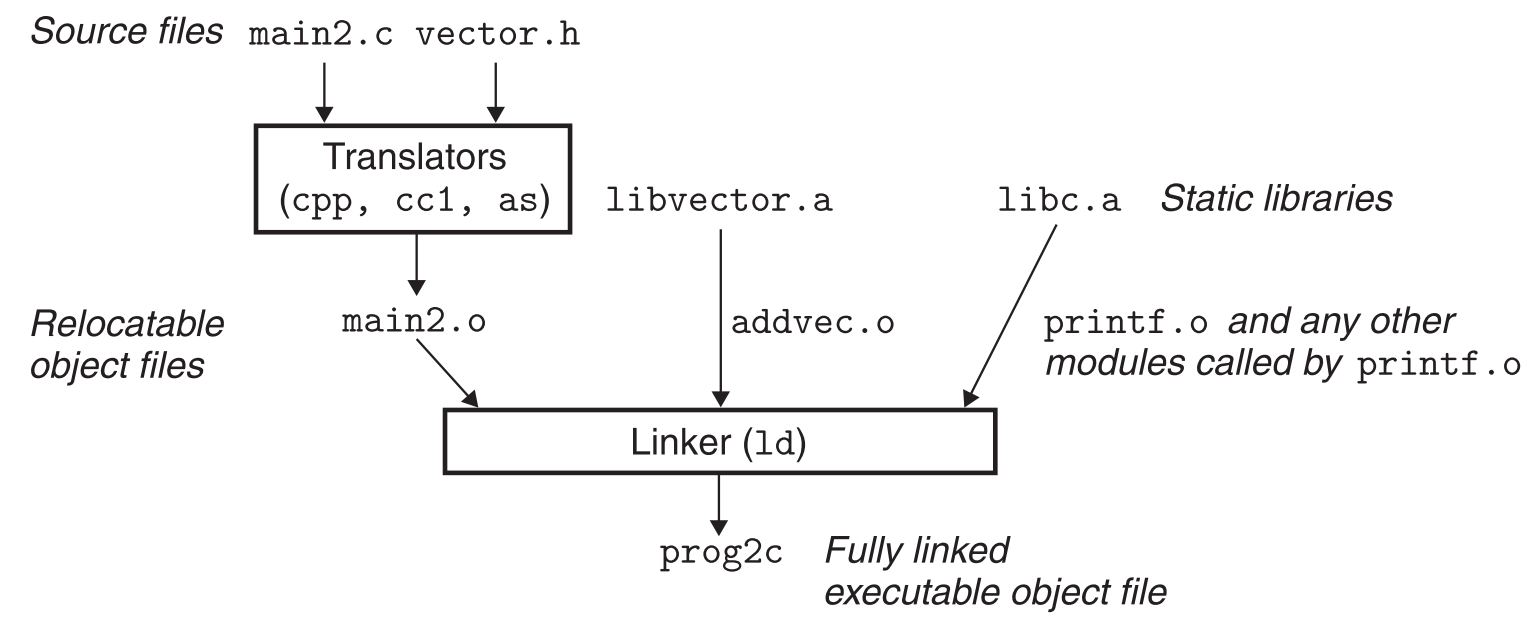
只用了lib中的addvec,则linking时也只link了lib中的addvec函数(另一个函数multvec就与main2.c无关了),另外还要link标准lib中的printf函数。
7.5.2 linker是如何扫描静态链接库解析外部符号的
在符号解析阶段,linker会顺序扫描relocatable object files和链接库,在这个过程中,linker维护了三个sets(初始为空)
| set name | function |
|---|---|
| E | 要被合并的relocatable object files] |
| U | unresolved symbols, 被引用了但是找不到定义的符号 |
| D | 在本次扫描前被找到定义的符号 |
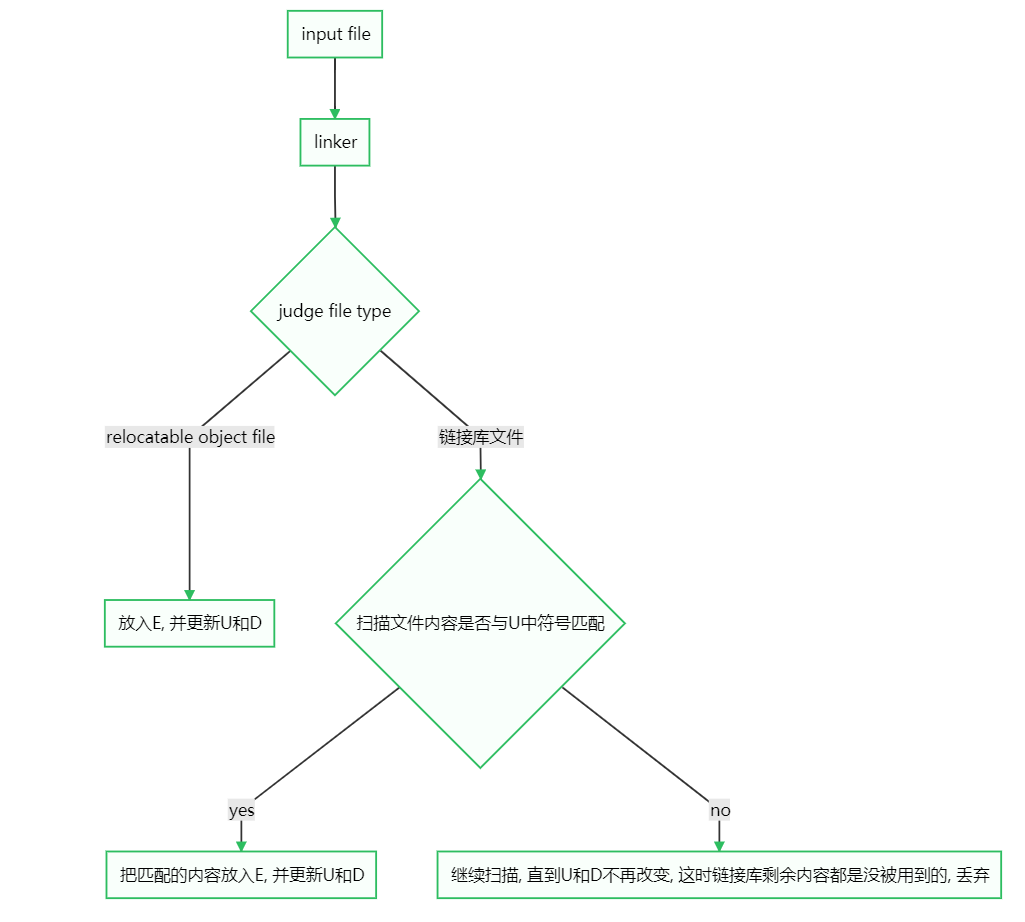
所有扫描结束后,如果U非空则报错(error:unresolved symbols)。反之则开始对E中的内容执行linking。
这种策略会因为linker的参数传入顺序产生依赖性问题。
比如在最开始就先传给linker一个链接库,那这个链接库相当于废了,因为这时U set为空,但是链接库中内容的选取是基于U的,所以整个库都会被丢掉。
同理,如果有两个静态链接库,库a调用了库b的函数,那么库a一定要比库b先传入linker。因为如果b先传入的话,它根本不知道a调用了它的哪个函数,就可能会把a要用的函数定义当垃圾扔掉。肯定要先提出需求(使U非空),才能解决需求嘛(删除U的某项内容,把它放入D)。
7.6 Relocation
当linker完成了符号解析后,它就已经知道整个代码以及数据区域的大小,现在要做的就是把所有的模块合并,并且赋予每一个symbol运行时的地址。
7.6.1 load阶段重定位的两个步骤
7.6.1.1 重定位sections和symbol definitions
linker把所有的sections的数据区和代码区合并,(比如陆续传入linker的所有模块的.data区域最后会被合并为一个.data区),然后把这些合并后的sections,以及每个section中的每一个symbol都“贴”到内存中(给它们分配内存的物理地址)。这些过程结束后,每一个指令和全局变量都在内存中有了自己独一无二的地址。
(该图取自https://wdxtub.com/csapp/thin-csapp-4/2016/04/16/)
7.6.1.2 重定位每一个section中的symbol references
linker把所有symbols指向其definition被重定位到内存后的物理地址。
完成这个过程要用到一个数据结构:重定位表
7.6.2 重定位表
当assembler生成一个object file时,它并不知道这个文件中的数据区和代码区最终会被放到内存的哪个位置,更不会知道它引用的外部模块中数据和代码最终会被放到内存的哪个位置,它会为这些最终位置不确定的数据生成一个重定位表(其中记录这些数据的地址),来告诉linker当合并这个文件时,这些不确定位置的数据的地址应该被怎样修改。
代码的重定位表在.rel.text中,数据的重定位表在.rel.data中
1 | typedef struct |
重定位的详细讨论可以参看【PE重定位表】
7.7 Executable Object Files
7.7.1 ELF executable object file格式
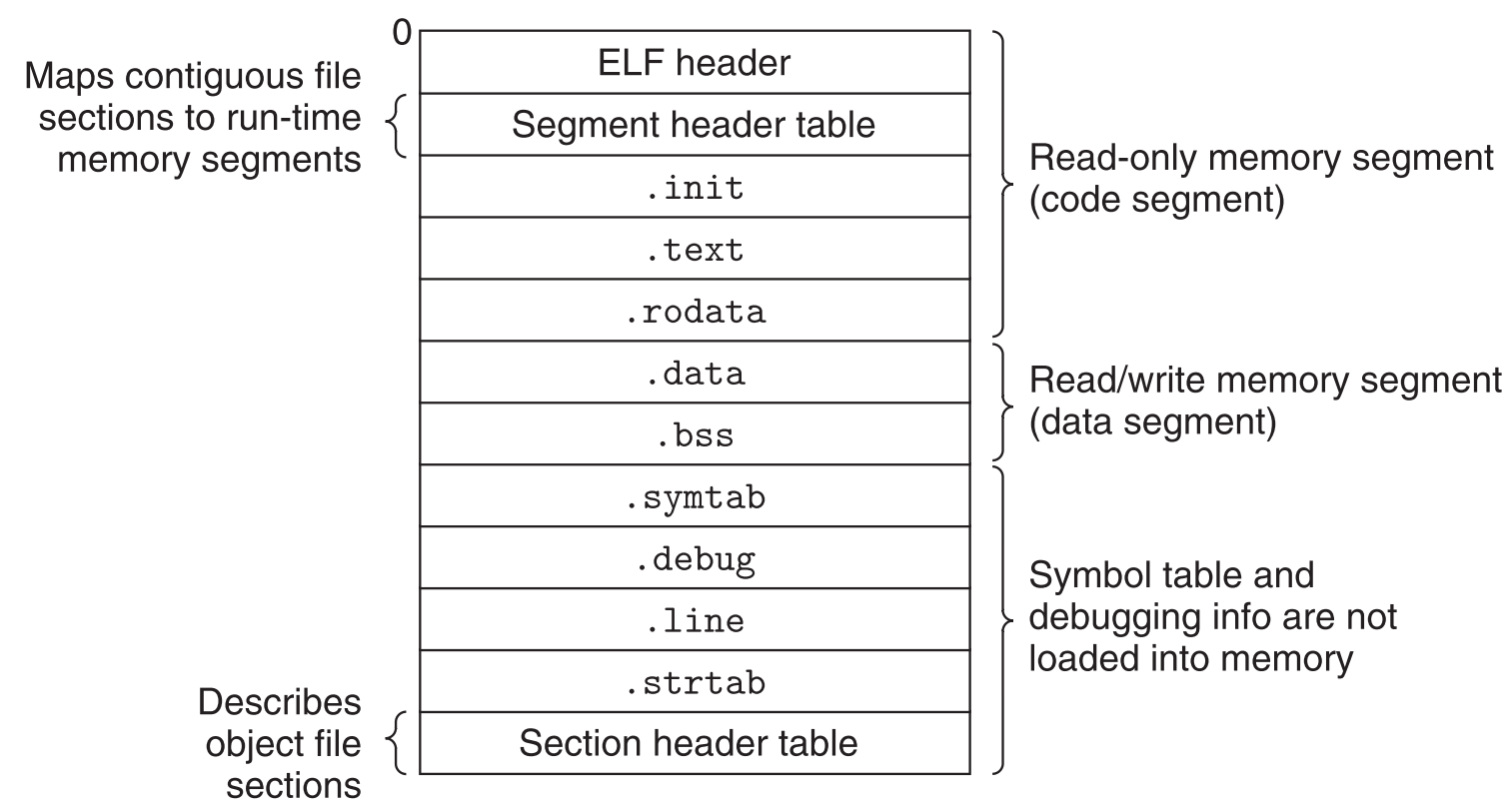
可以看到executable object file的结构与relocatable object file是十分类似的。除了几个特别的地方:
.init section中定义了一个函数_init,是用来初始化程序的。
executable object file已经是full linked了,不需要再进行linking阶段的重定位了,因此不存在.rel section。
7.7.2 Program Header Table
ELF格式的可执行文件与内存有直接映射关系(文件中一整块连续的内容会被映射到内存中一整块连续的区域),这种可执行文件与其运行时内存之间的映射关系反映在一张program header table上,其结构如下。
| name | function |
|---|---|
| off | 可执行文件中的offset |
| vaddr/paddr | 内存地址 |
| align | 对齐 |
| filesze | 可执行文件的大小 |
| memsz | 内存大小 |
| flags | 运行时权限 |
| 这个table中只涉及了两个区域,code区和data 区。 | |
| 其中code区是只读的,且可以被执行(r-x) | |
| data区是可读可写,但不可执行的(rw-) |
note:注意到本例中data区的filesz和memsz并不相等,这是因为文件中存在未赋初值的全局变量(在文件中表现为占位符,存储在.bss),它在运行时才会被分配空间。
至于这两个区会被映射到内存的哪个位置(vaddr/paddr,也就是他们在内存中的起始地址),则是由linker指派。这个地址必须满足:
1 | (vaddr) mod (align) = (off)mod(align) |
(其中off是可执行文件中某segment相对于文件开头的offset)
例如本例的data segment中,vaddr mod align = off mod align = 0xdf8
这样对齐的好处是能提升文件被加载进内存的效率, 具体原因在虚拟内存章节中会详细描述。
7.8 Loading 程序被加载进内存并运行的过程
当loader运行时,它会首先生成一个内存镜像,如下: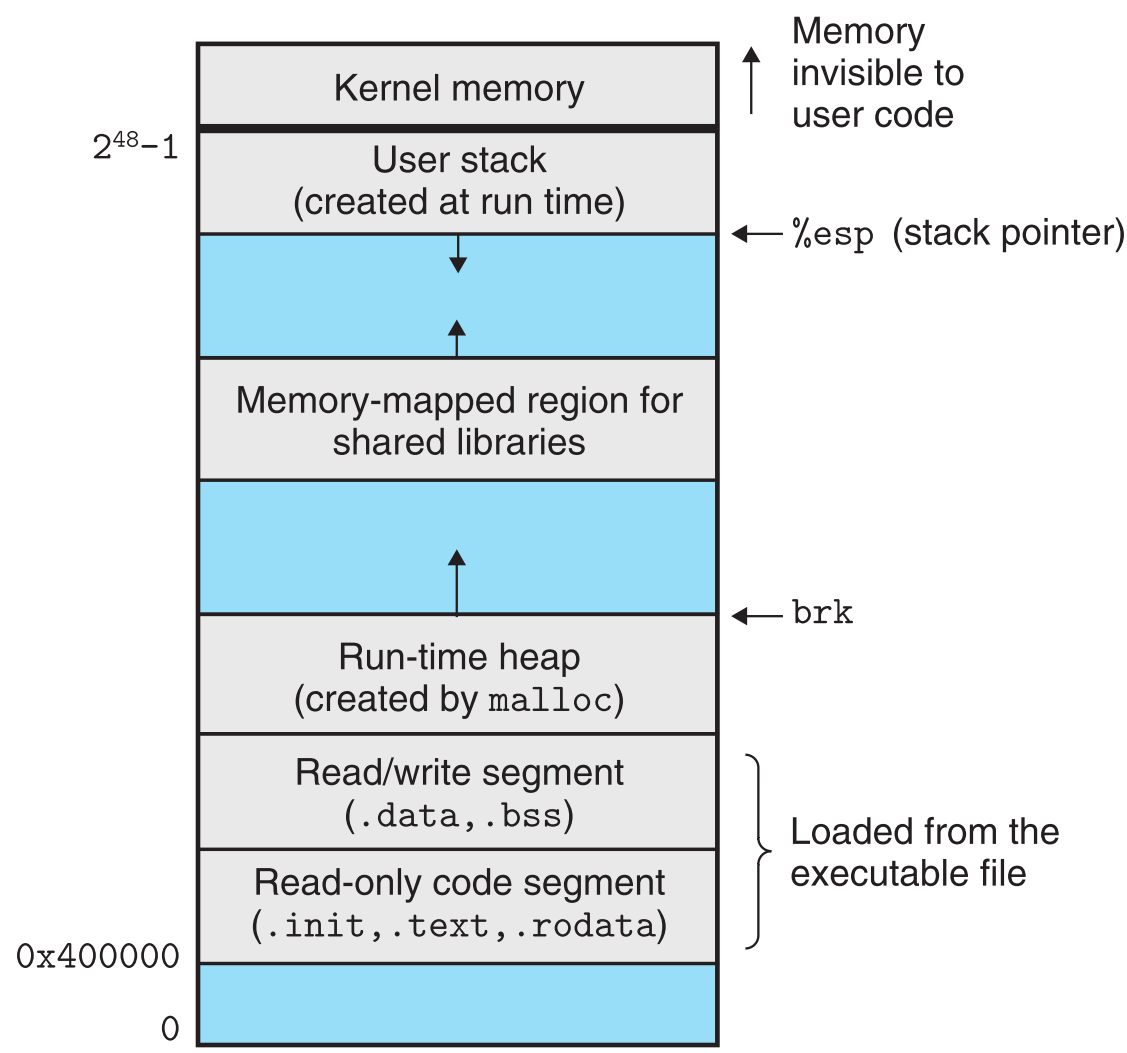
接着根据程序的header table提供的映射关系,loader把可执行文件中的code和data从disk复制到内存中的相应位置(该过程叫loading),然后loader跳转到程序的第一条指令处(entry point,它指向一个函数_start),它会调用这个_start函数,_start函数又会调用系统函数__libc_start_main,这个函数的作用是初始化运行环境,并调用用户层的main函数(至此程序本体开始执行),处理main函数的返回值,并在程序执行完后将控制交还给kernel。
生成虚拟内存镜像时,linker会使用一种ASLR(Address-space layout randomization 地址空间随机化)的策略来决定stack、shared library和heap segments在内存中的位置(为了保护内存数据)。所以同一个程序每次运行时的stack、shared library和heap segments在内存中的位置都不一样。
7.9 Dynamic Linking with shared libraries
静态链接库其实还不够方便,因为只要它里面的内容改变了,使用了它的程序就必须先获得它最新的库文件,然后重新编译链接。当然这一切的前提还是程序员要时刻关注静态链接库的更新情况。另外,几乎每一个C程序都要用到stdio.h这个包(一般至少要用到printf或者scanf),使用静态链接库会依然会造成巨大的空间浪费(每个文件都存有一份stdio.h的副本)。
为了解决这个问题,shared libraries诞生了,它可以在程序的load阶段或运行时被加载进内存,与程序进行动态链接(由dynamic linker完成)。也就是说,在程序被加载进内存之前,它在磁盘上躺着时所占的空间是不包含shared libraries的,这就解决了静态链接库空间浪费的问题。同时因为shared libraries每次只有在程序运行时才会被动态的加载,因此无论库文件怎么改动,程序也不需要重新编译。
windows上的dll文件就是动态链接库文件。
7.9.1 shared libraries的两个特点
动态链接库文件在一个文件系统中只有一个, 不会存在复制(除非刻意为之),因为一份dll中的code和data是可以被所有引用了它的exe文件所共享的。
dll中的.text节在内存中可以被不同的运行程序访问(原因将在虚拟内存章节中揭晓)。
7.9.2 dynamic linking的过程(load阶段)
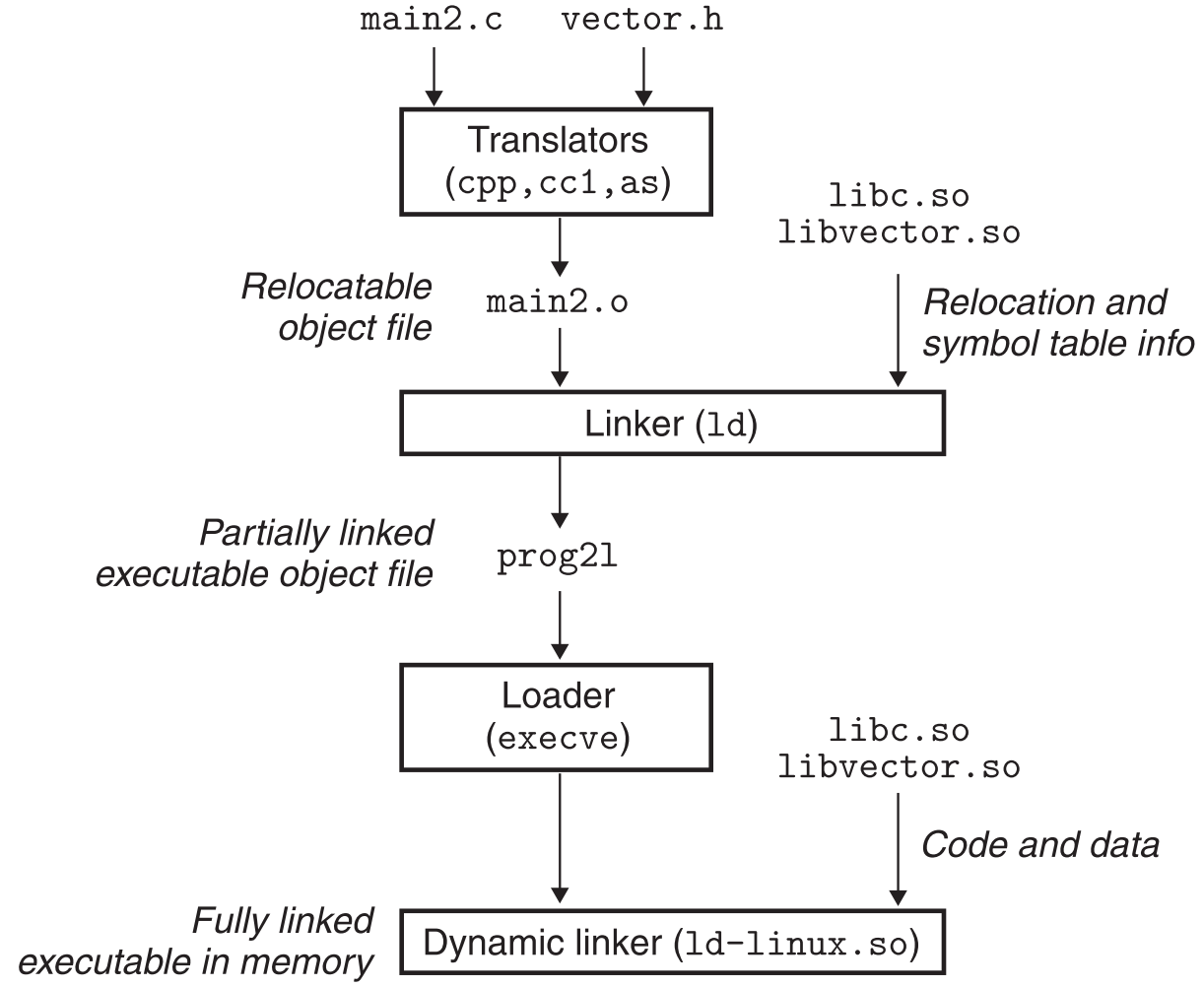
—在linking阶段,动态链接库的一些信息(重定位,符号表等)会被linker合并(作为之后运行时加载动态链接库的依据),由此生成的exe文件被称为Partially linked exe文件。(这一步也是dll和静态链接库主要的区别了,静态链接库此时是会全部被linker链接的,而dll只是一些信息被linker链接)
—当Partially linked exe文件运行被加载进内存后,系统检测发现这个文件中存在.interp节,这个节中包含了dynamic linker(它本身也是一个dll)的路径信息,这时系统不会像往常(无dll情况)一样把control传给程序本体了,而是先把dynamic linker加载进内存并执行,dynamic linker执行的工作如下:
重定位dll文件的text和data(dll中原本的地址一般会和exe文件冲突,且多个dll文件必然冲突,所以必须要重定位,详细请参考PE解析重定位表的内容)b. 重定位所有**程序中引用的dll内容**(程序中引用,dll中定义的内容)。
- 最后dynamic linker再把control传给程序本身。程序开始执行,这时所有dll在内存中的位置已经固定不再改变了,动态链接完成。
7.9.3 dynamic linking(running阶段)
在程序运行时可以调用函数请求dynamic linker加载并连接某dll。