《CSAPP》Memory Hierarchy
6.1 存储技术
6.1.1 易失性存储器(random access memory)
易失性存储器(random access memory)DRAM一般用作main memory,因为存在漏电现象所以必须周期性的刷新以保存数据。相比于SRAM集成度高,功耗较低,价格便宜,但缺点是访问速度较慢,SRAM,因为其访问速度较快,所以一般用作cache。而且只要处于通电状态,信息就不会消失,因此不需要像DRAM一样定时刷新。但相比之下SRAM的集成度较低,功耗较高,价格贵。他们都是易失性存储器,也就是说只要电源关闭,他们保存的数据就会丢失。
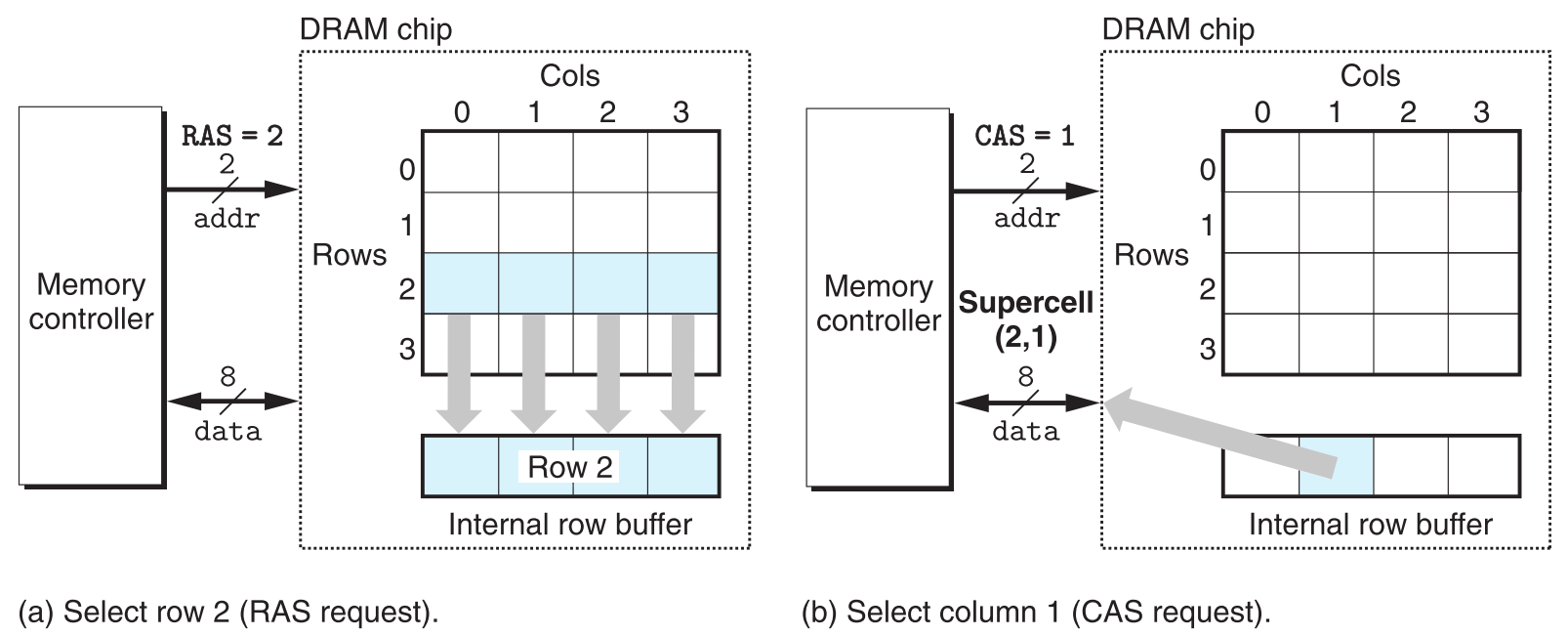
之所以DRAM chip设计为一个矩形,就是为了节省访问的元素需要的地址线个数,缺点是取数据的地址要分两次发(第一次选行,第二次选列)。比如,图中矩形DRAM芯片只需要两根地址线(可表示0、1、2、3四个值),发送两次就可以取到矩阵中的任意地址。而如果设计成线性数组,虽然取数据只需要发送一次地址,但要用四根地址线来囊括所有(0~15)范围的地址。
6.1.2 非易失性存储器(non-volatile memory)
与RAM相反,非易失性存储器中的数据在断电的状态下不会消失。
分为两大类,ROM和flash memory。
6.1.2.1 ROM(read-only memory)
顾名思义,只能往里面存一次数据,之后就不能修改只能读取了。一般用来存储不需要变更的数据,比如BIOS与一些firmware都存储在ROM中。
6.1.2.2 flash memory
特点是断电数据不会丢失,且可擦写。U盘,手机内存卡使用的就是flash memory。
6.1.3 CPU、主存和硬盘通信
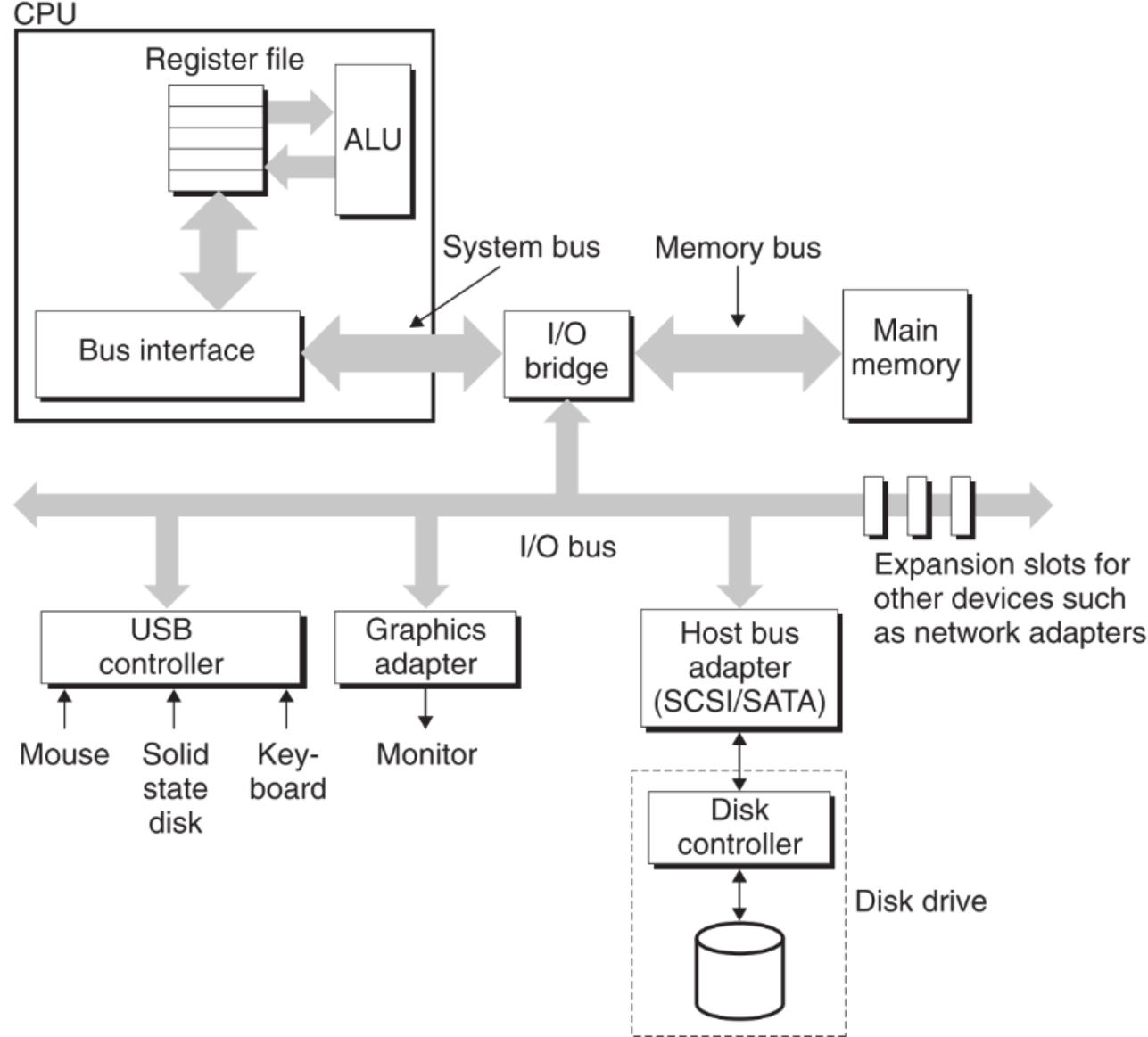
I/O桥的作用是转译信号。
system bus和memory bus根据厂家不同,型号也不同,因此适配性较差,但速度较快;I/O bus则不同,它适配几乎所有厂家生产的外设,但速度较慢。
访问主存的原理为CPU发出命令(如读取),通过bus传递到主存,主存执行命令,把对应数据发回给CPU。
访问硬盘的原理为CPU发出命令(如读取),将要读取数据的逻辑地址传递到硬盘(这期间所有cache(包括主存)全部miss),硬盘将逻辑地址转换为物理地址,找到对应数据后将其直接发送给主存(在此传输过程(DMA)中,CPU为了充分利用资源会去干别的事),当发送完毕时,硬盘发送中断指令给CPU,通知它停止当前的活动并去主存的逻辑地址中读取对应的数据。
访问硬盘的原理与CPU和主存之间的cache miss原理一致,比如CPU发出读取命令,数据在L2 cache中,L1没有。则L2把对应block传输给L1(CPU会利用这段时间干别的事),传输完成后发送中断指令给CPU,通知它可以去L1找刚才的数据了,CPU则又发送一次指令去L1中获取数据。
6.1.4 SSD
SSD是基于flash memory技术的
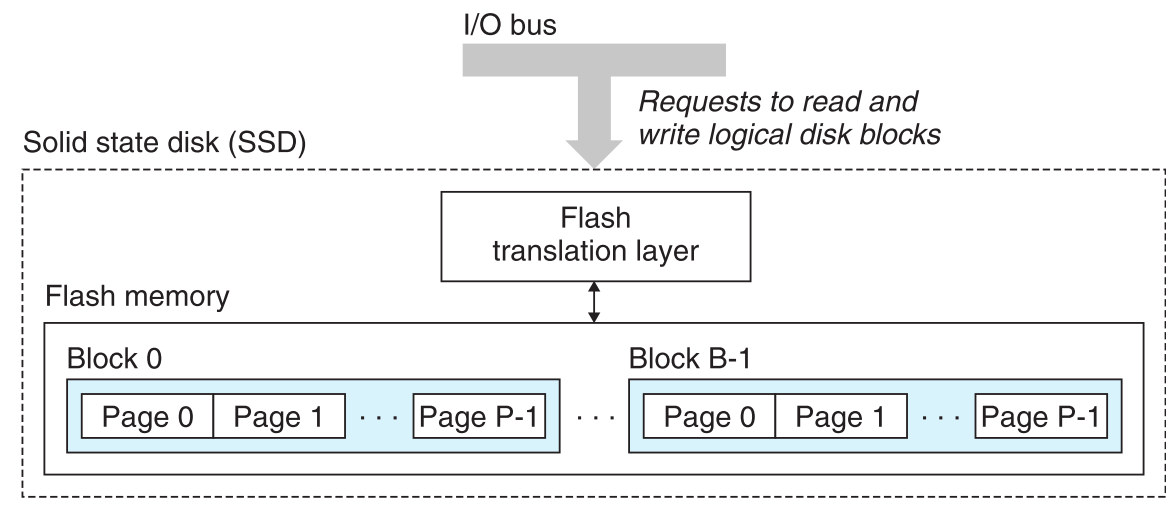
对SSD的读和写是以page为单位的,而每次写数据前必须保证block是全1(即为初始状态),这就导致如果要往已经存在数据的block中写入,就必须先把该block的数据复制到新的block中,再把新数据写入,这就导致了SSD的写速度相对较慢。然而它的优点也很明显,SSD不像普通的机械硬盘,它是不需要一个移动的针头来读取数据的,因此它的读取速度非常快
6.2 局部性原理(locality)
6.2.1 Spatial locality
如果多次操作的数据处在一段连续的内存空间中, 则它具备良好的spatial locality,程序总是倾向于具备这个性质。(根本原因是cache的block中总是一段连续的地址)
6.2.2 Temporal locality
如果一个变量被反复引用,则它具有良好的temporal locality。(编译器会把它放到register file中以提升访问速度)
6.2.3 栗子
比如这段代码:
1 | int sumvec(int v[N]) |
sum被反复引用,说明这段程序具有良好的temporal locality。
v[i]中i步长为1,又因为数组在内存中是连续存储的,因此这段程序具有良好的spatial locality。
二维数组中spatial locality会比较明显。
1 | for(i=0;i<M; i++) |
我们知道二维数组实际上就相当于下行首接上行尾拼接的一维数组(因此它在内存中是连续存储的),上述代码是按行访问的,因此它具有良好的spatial locality。
而
1 | for(j=0;j<N; j++) |
按列访问则相当于内部循环每次迭代都要跨越N个内存地址去访问元素,它的spatial locality较差。
这两种locality只要具备其一,就可以称这段程序具有良好的locality
6.3 cache
我们都听说过CPU与memory之间有一个cache,它的作用是存储最近CPU访问过的内存数据,以提升之后访问的速度。为什么这样就能提升访问速度?这与我们上一段讨论的locality有关:程序会倾向于反复的访问小范围的内存,甚至是反复访问同一个地址,而cache的运作方式正符合这个性质。
cache是一个广泛的概念,它并不只存在于CPU和memory之间。可以说任意两个存储结构(一个离CPU近,快;另一个远,慢),前者是后者的cache。
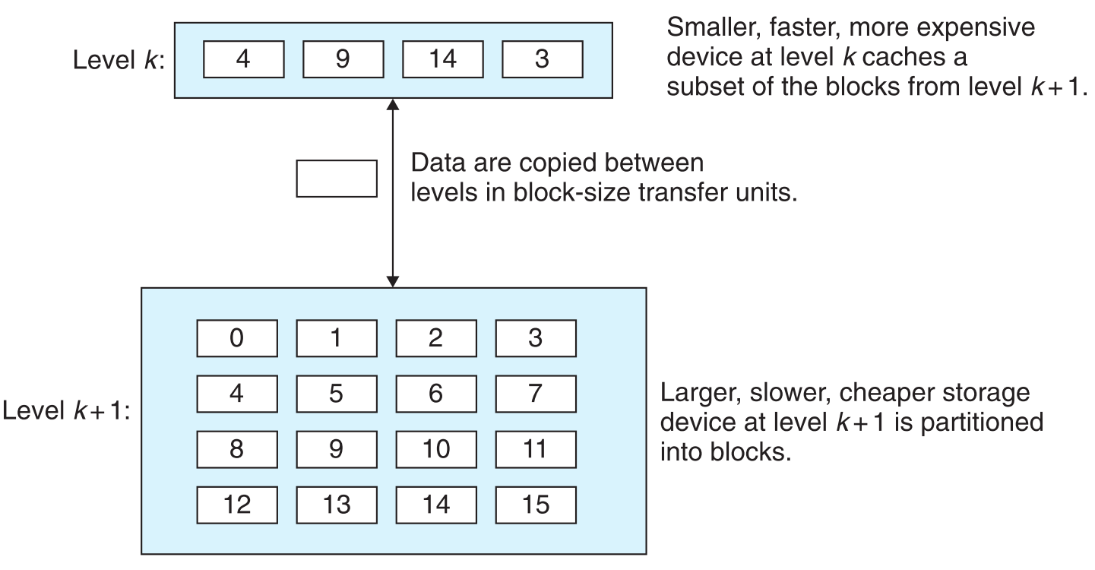
当程序想要取一个元素4,在指令走到k时发现它的cache中已经缓存了4,就直接从k中把4取走了,这对k来说是cache hit。相反如果想取6,就必须等待k去把k+1中的6取到自己的cache中(如果cache满了就会发生覆盖),程序再从k中取走6,这对k来说是cache miss。
6.3.1 三种cache miss
一种机制是从k+1取回的每一个值x会被固定存到k的cache中(x%4)的位置。这种机制的缺点也很明显,假设一段程序访问0之后又访问8(两个都要被存到k层cache的0位置),这叫conflict miss。进而如果反复的访问0,8,0,8…,就称之为thrashing。
另外一种情况,假如循环内所有变量占的空间大于k的cache容量,
则每次访问超出那部分的数据必然miss,这叫capacity miss如果一个cache本身就是空的,第一次访问必定miss,这叫compulsory misses or cold misses
随着科技的进步,CPU和主存之间的性能差异越来越大(加1个cache已经远远不够了),为了配合CPU日益进步的性能,设计者在CPU和主存之间存在N级缓存。
6.3.2 cache hit原理
先来看看普通cache的构造
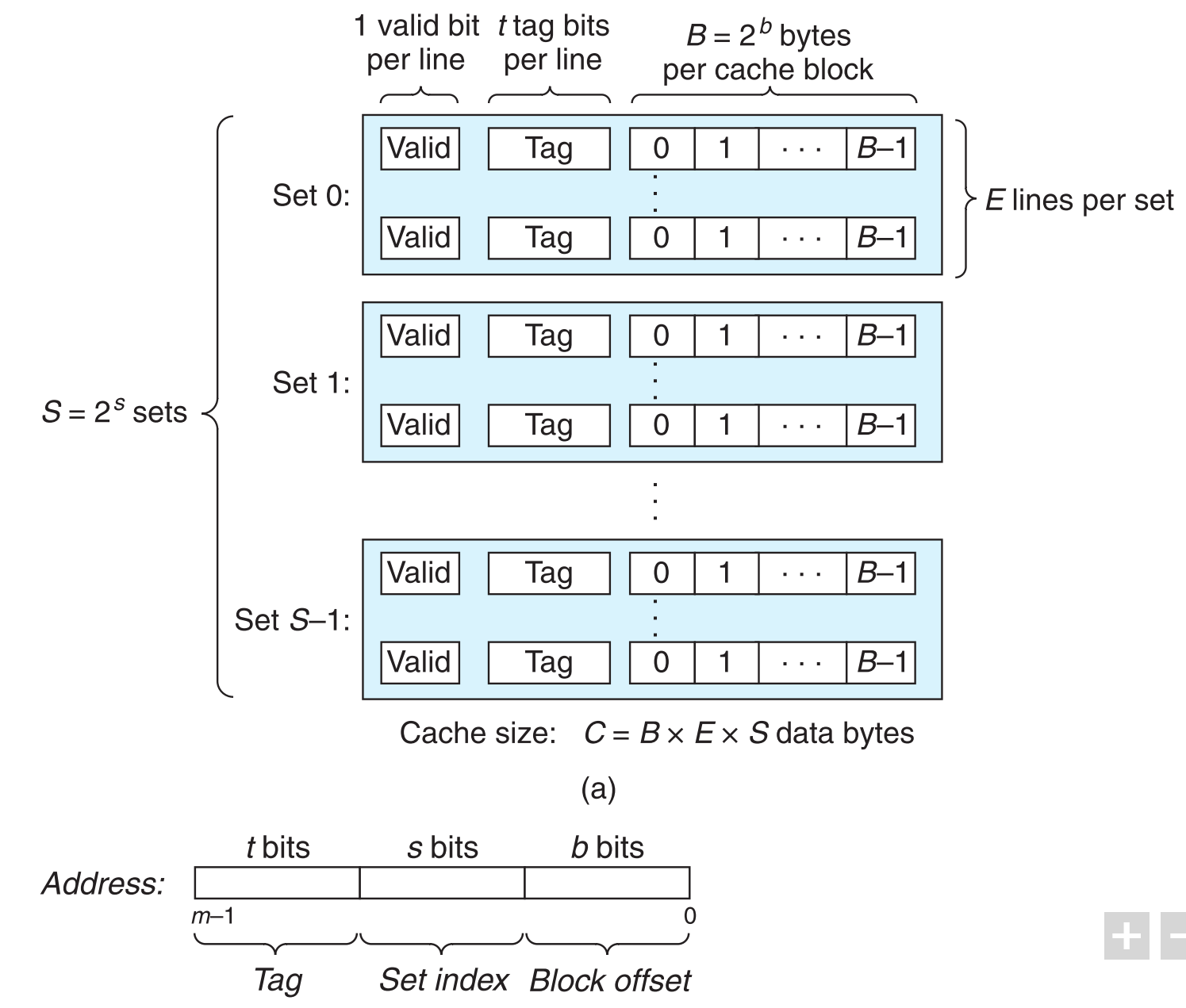
它从逻辑上把cache的空间分为了S个sets,每个set中有E行(E≥0),每行有一个block和一些描述信息,即:
$$
Line = block + informationOfBlock
$$
所以行几乎可以被等同为block。要谨记的是,block是cache之间通信的最小单位, 且block中存放是连续的数据.
6.3.2.1 栗子
假如本级cache中只有一个block,其大小为4bytes,现有一个char[8]数组保存在下一级cache中(图中数字均为下标)
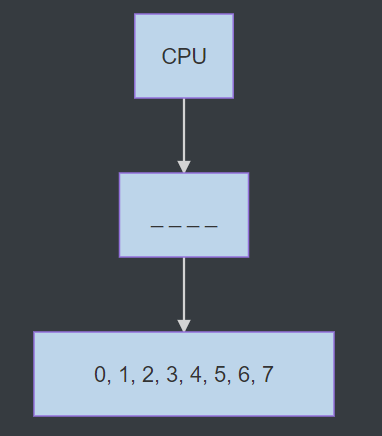
当CPU请求char[0]时,本级cache miss,该block会把下一级cache中char[0]和char[0]之后连续的元素, char[1], char[2], char[3]全部缓存(存满block的大小4个bytes),则下次访问这些元素就都能命中,
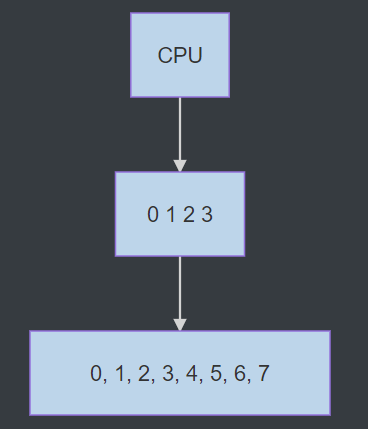
但如果接着访问char[4], 就会发生miss,block又会把下级cache的char[4], char[5], char[6], char[7]缓存
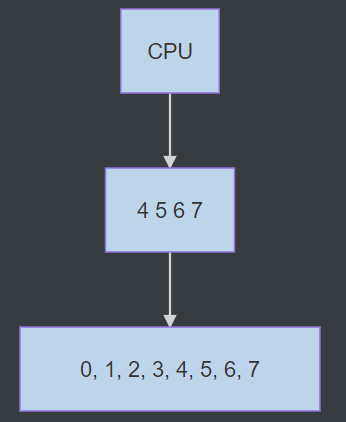
再下一次如果访问char[1],又会miss,block的数据又会被更新为char[1], char[2], char[3], char[4]。
这些概念是后面讨论的基础,一定要理解。
为了使cache运作,CPU访问的主存数据地址在逻辑上被分为了三个区域,依此与cache中存储的数据建立映射关系。
set index顾名思义,指定了数据在cache的哪个set中,选定了set后:
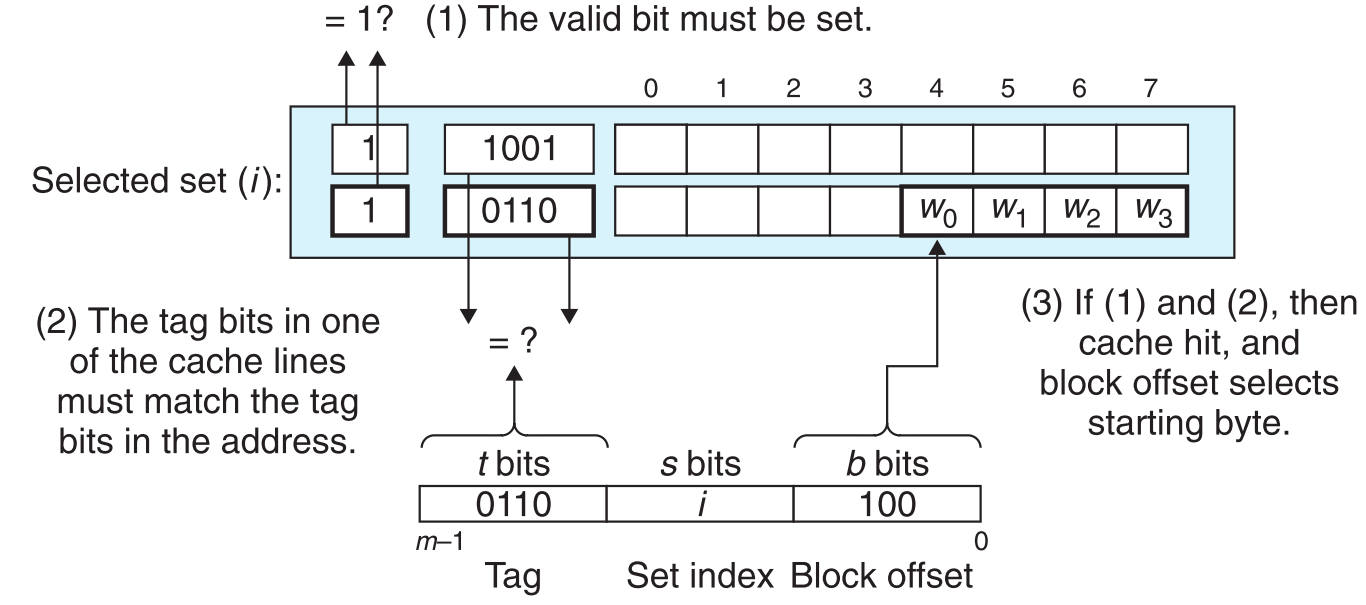
用地址中的tag与set中每一行的tag比对,如果相同且valid=1,就指定了行号。
最后block offset告诉我们数据在行中具体的位置(数据的第一个字节)。
概括为3步:1. 选set 2. 匹配行(前两步决定是否命中) 3. 提取数据
要注意是否发生了cache-hit是在找到具体数据之前的,也就是当tag匹配且valid=1时,就认为是cache-hit。然后才在cache-hit的基础上,根据block offset找到具体数据的第一个byte位置,也就是说cache-hit是基于行而不是基于block中的具体数据(是地址之间的匹配而不是数据之间的匹配)。
6.3.3 写(必须制定数据更新策略)
读取还好说,miss就一直往下找,一旦hit就把数据逐层取回。如果写入,就必须要想办法同步所有层该地址的数据以确保它们一致。因此在写入操作频繁发生的情况下,数据的更新策略会极大的影响整体性能。
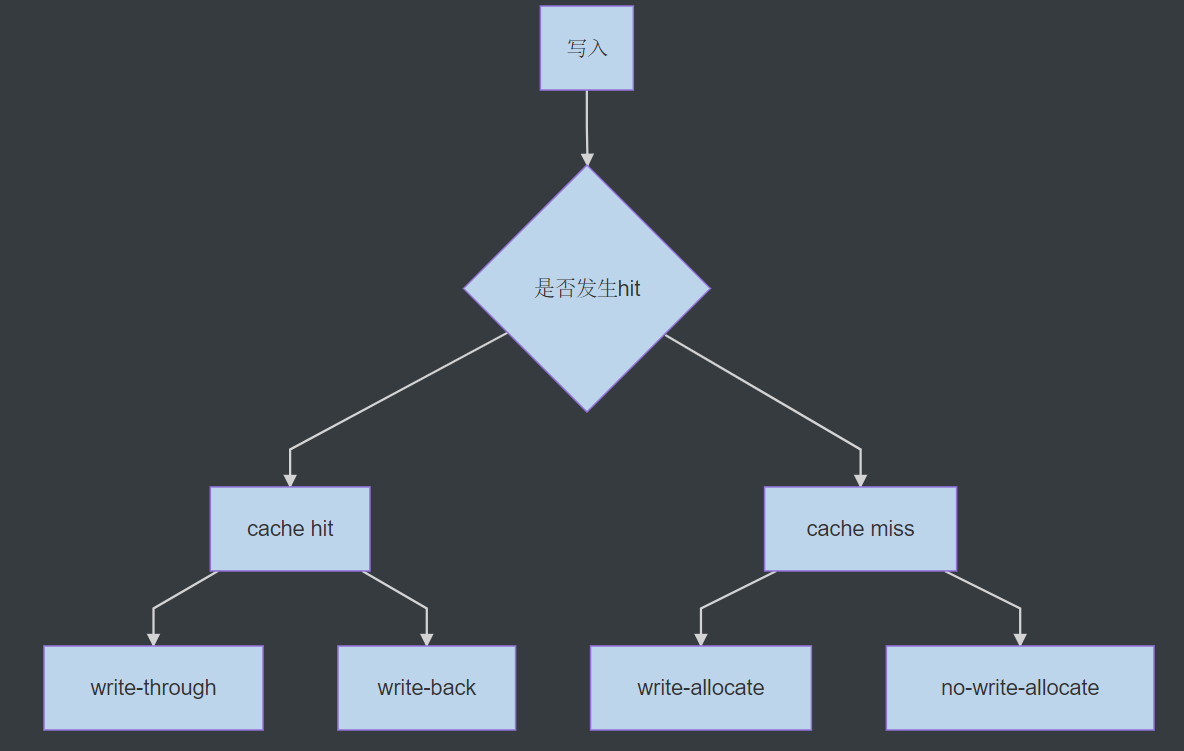
6.3.3.1 cache hit时的更新策略
write-through: 一旦命中,直接把命中的block更新到下一层(容易造成bus拥堵,但信息更新及时)。
write-back: 一旦命中,先只更新cache中的数据, 一直等到cache中的block要被替换掉时,才将该block更新到下一层(减轻了bus拥堵问题,增加了复杂度,此时对于每一行cache必须维护一个dirty bit来说明某block是否被修改过)。
6.3.3.2 cache miss时的更新策略
write-allocate: 一旦miss,从下一层取回目标block到cache,在cache中更新该block。
no-write-allocate:一旦miss,直接把数据更新到下一层。
一般情况下都采用write-back与write-allocate组合作为数据写入的策略。
6.3.3.3 例子
假定现在要往地址a写入一个数据。走到了cache1,发现命中了,直接更新cache1中的数据,并设置这一行的dirty bit为1,指令结束。
又往地址b写入一个数据,走到cache2才命中,根据write-allocate要把block取回给cache1,但是cache1满了,要把a地址的数据踢掉,检测发现a的dirty bit为1,此时根据write-back先把它现在的数据更新到cache2,然后在cache1中移除掉a,将取回的b的数据放到a的位置。
6.3.4 cache性能
6.3.4.1 cache可根据其存储的数据类型分为三种
i-cache,只存储instruction
d-cache,只存储数据
unified-cache,混合前两种
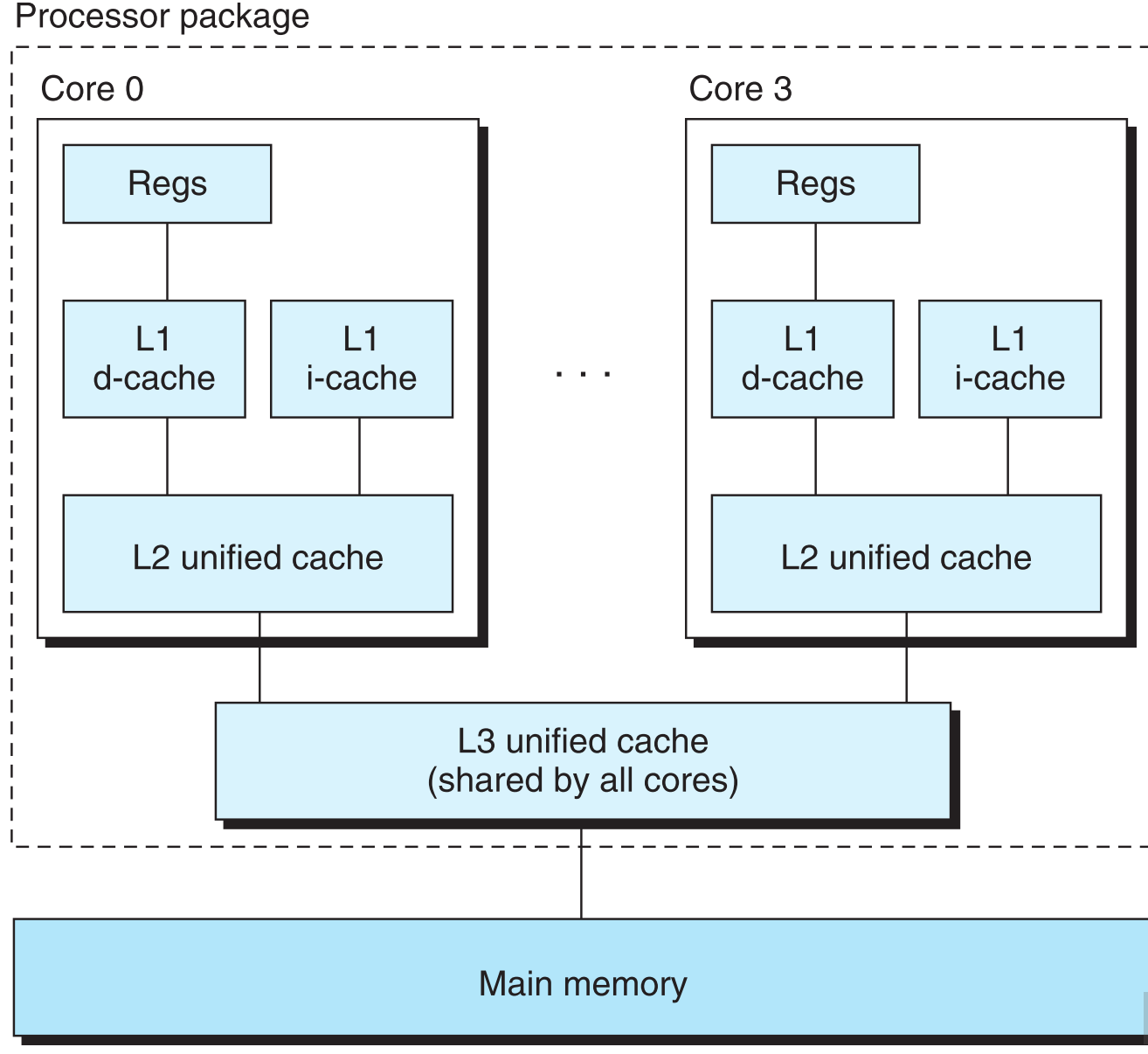
这样划分主要是为了提升性能,因为对它们采取不同的策略(比如i-cache为只读,所以对它的策略可以简单一些),同时减少访问指令和数据之间conflict miss。
6.3.4.2 决定cache性能的几个参数
- miss rate:miss次数/总reference次数
- miss penalty:因为miss导致的额外时间开销
- hit rate:hit次数/总reference次数
- hit time:命中后将数据传给CPU所需要的时间(从set selection开始算)
6.3.4.3 影响cache性能的几个因素
cache的大小:cache越大,hit rate越高。但这并不能够提升cache的性能,因为随着cache size变大,hit time也变长了(比如set selection需要更长时间了),而这个因素对cache性能的影响要大于hit rate。这也是为什么离CPU越近的cache容量越小
block大小:给定cache size,block越大,意味着行数越少,行数越少命中率越低。并且block的增大还会导致miss penalty的增加(一旦miss就要替换整个block,block越大耗得时间越长)。
每个set有几行(关联方式):行数(block数)增加可以降低thrashing发生的概率,增加cache hit的概率,但代价是需要维护更多的tag bit以及其他状态相关的位。
写入策略:离CPU越远,两个cache之间通信所需要的时间就越长,因此减少较远处caches之间的数据传输次数能提高cache的性能(较远处一般都采用write-back策略来减少通信次数)。
6.4 利用cache原理优化代码
了解了cache的原理后,对比来看,good locality其实就等于cache的高命中率。
6.4.1 make the common case go fast
程序的大部分时间都在调用几个核心的函数,而这些函数执行的大部分时间都是在调用几个核心的循环,这几个循环就是common cases,集中精力优化它们,让它们具备良好的locality,这比优化其他部分要有效的多。
6.4.2 根据locality进行优化
- 重复多次使用某一变量
- 对数组的操作,两次迭代的间隔尽量小(如在没有使用loop unrolling的情况下,i++优于i+=2)
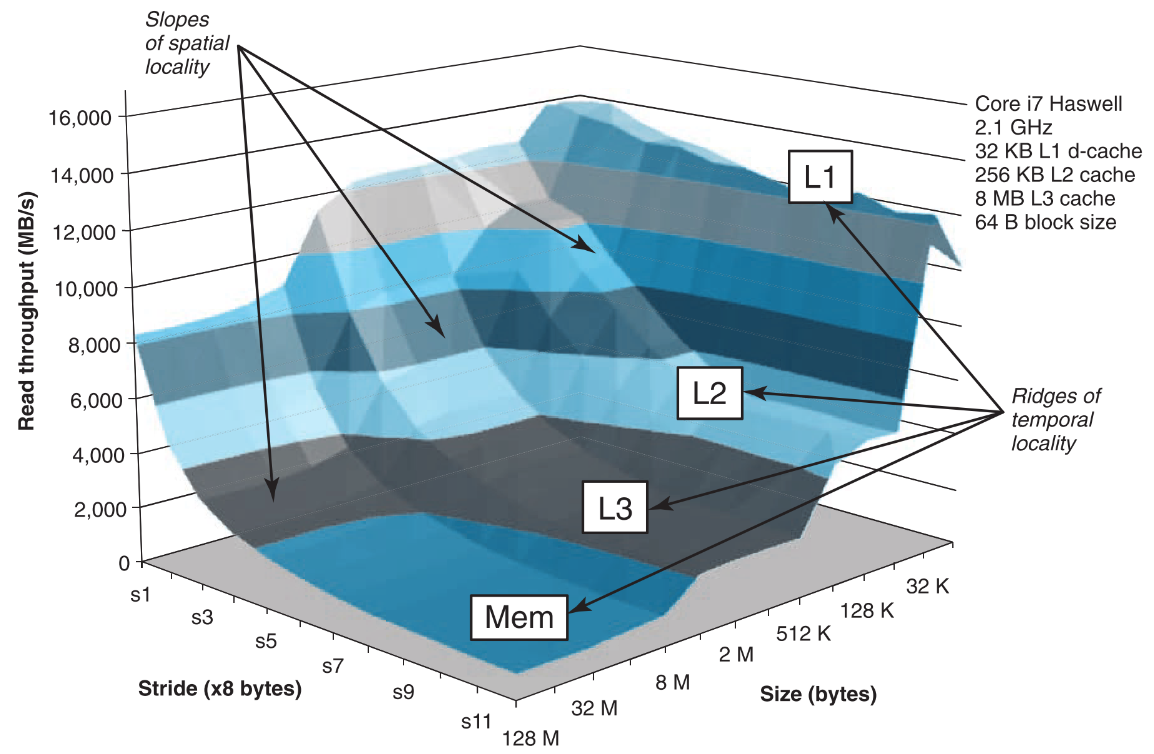
6.4.3 memory mountain
该图说明cache的性能是同时受spatial locality和temporal locality制约的。
循环中的程序小于32K时,无论stride(两次访问元素在内存中的间隔)是多少,都跑在L1层享受最高的读取速率。因为总共就占那么点地方,cache一次就都装下了,即使stride很大近期要访问的元素也就在cache中,不会产生miss。而随着程序size的增加,当stride增加时,读取速率会断崖式的下降,原因是当stride扩大,不光每个block中都缓存了大量近期不会被访问到的元素,而且整个访问的范围超过了cache的容量,导致后续的每次访问产生miss的概率非常高,由此产生大量的miss penalty。
反观当stride保持在1时,即使size大量增加程序也依然跑在L1层,毕竟stride 1在spatial locality上是对cache空间的极致利用了。
6.5 总结
降低stride,减少的局部资源声明即可契合cache的运作机制,提升程序的运行速度。